http://www.dzsc.com/data/html/2008-11-28/73975.html
由于大多数无线传感器网络应用都是由大量传感器节点构成的,共同完成信息收集、目标监视和感知环境的任务。因此,在信息采集的过程中,采用各个节点单独传输数据到汇聚节点的方法显然是不合适的。因为网络存在大量冗余信息,这样会浪费大量的通信带宽和宝贵的能量资源。此外,还会降低信息的收集效率,影响信息采集的及时性。
为避免上述问题,人们采用了一种称为数据融合(或称为数据汇聚)的技术。所谓数据融合是指将多份数据或信息进行处理,组合出更高效、更符合用户需求的数据的过程。在大多数无线传感器网络应用当中,许多时候只关心监测结果,并不需要收到大量原始数据,数据融合是处理该类问题的有效手段。
1.数据融合技术的产生背景来自于数据融合的几个重要作用
(1)节省能量
由于部署无线传感器网络时,考虑了整个网络的可靠性和监测信息的准确性(即保证一定的精度),需要进行节点的冗余配置。在这种冗余配置的情况下,监测区域周围的节点采集和报告的数据会非常接近或相似,即数据的冗余程度较高。如果把这些数据都发给汇聚节点,在已经满足数据精度的前提下,除了使网络消耗更多的能量外,汇聚节点并不能获得更多的信息。而采用数据融合技术,就能够保证在向汇聚节点发送数据之前,处理掉大量冗余的数据信息,从而节省了网内节点的能量资源。
(2)获取更准确的信息
由于环境的影响,来自传感器节点的数据存在着较高的不可靠性。通过对监测同一区域的传感器节点采集的数据进行综合,有效地提高获取信息的精度和可信度。
(3)提高数据收集效率
网内进行数据融合,减少网络数据传输量,降低传输拥塞,降低数据传输延迟,减少传输数据冲突碰撞现象,可在一定程度上提高网络收集数据的效率。数据融合技术可以从不同角度进行分类,主要的依据是三种:融合前后数据信息含量、数据融合与应用层数据语义的关系以及融合操作的级别。
2,根据融合前后数据信息含量划分为无损融合和有损融合
前者在数据融合过程中,所有细节信息均被保留,只去除冗余的部分信息。后者通常会省略一些细节信息或降低数据的质量。
3.根据数据融合与应用层数据语义的关系划分为依赖于应用的数据融合、独立于应用的数据融合以及两种结合的融合技术
依赖于应用的数据融合可以获得较大的数据压缩,但跨层语义理解给协议栈的实现带来了较大的难度。独立于应用的数据融合可以保持协议栈的独立性,但数据融合效率较低。以上两种技术的融合可以得到更加符合实际应用需求的融合效果。
4.根据融合操作的级别划分为数据级融合、特征级融合以及决策级融合
数据级融合是指通过传感器采集的数据融合,是最底层的融合,通常仅依赖于传感器的类型。特征级融合是指通过一些特征提取手段,将数据表示为一系列的特征向量,从而反映事物的属性,是面向监测对象的融合。决策级融合是根据应用需求进行较高级的决策,是最高级的融合。
5. 无线传感器网络的数据融合技术可以结合网络的各个协议层来进行
在应用层,可通过分布式数据库技术,对采集的数据进行初步筛选,达到融合效果;在网络层,可以结合路由协议,减少数据的传输量;在数据链路层,可以结合MAC,减少MAC层的发送冲突和头部开销,达到节省能量目的的同时,还不失去信息的完整性。无线传感器网络的数据融合技术只有面向应用需求的设计,才会真正得到广泛的应用。
(1)应用层和网络层的数据融合
无线传感器网络通常具有以数据为中心的特点,因此应用层的数据融合需要考虑以下因素:无线传感器网络能够实现多任务请求,应用层应当提供方便和灵活的查询提交手段;应用层应当为用户提供一个屏蔽底层操作的用户接口,用户使用时无须改变原来的操作习惯,也不必关心数据是如何采集上来的;由于节点通信代价高于节点本地计算的代价,应用层的数据形式应当有利于网内的计算处理,减少通信的数据量和减小能耗。
从网络层来看,数据融合通常和路由的方式有关,例如以地址为中心的路由方式(最短路径转发路由),路由并不需要考虑数据的融合。然而,以数据为中心的路由方式,源节点并不是各自寻找最短路径路由数据,而是需要在中间节点进行数据融合,然后再继续转发数据。如图1所示,这里给出了两种不同的路由方式的对比。网络层的数据融合的关键就是数据融合树(aggregatton tree)的构造。在无线传感器网络中,基站或汇聚节点收集数据时是通过反向组播树的形式从分散的传感器节点将数据逐步汇聚起来的。当各个传感器节点监测到突发事件时,传输
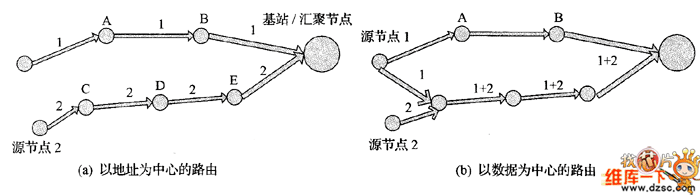
图1 以地址为中心的路由与以数据为中心的路由的区别
数据的路径形成一棵反向组播树,这个树就成为数据融合树。如图2所示,无线传感器网络就是通过融合树来报告监测到的事件的。
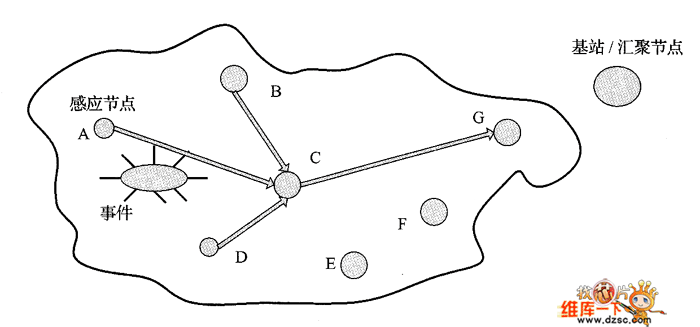
图2 利用数据融合树来报告检测事件
关于数据融合树的构造,可以转化为最小Steiner树来求解,它是个NP Com-plete完各难题。文中给出了三种不同的非最优的融合算法。
①以最近源节点为中心(center at nearest Source,CNS):以离基站或汇聚节点最近的源节点充当融合中心节点,所有其他的数据源将数据发送到该节点,然后由该节点将融合后的数据发送给基站或汇聚节点。一旦确定了融合中心节点,融合树就基本确定下来了。
②最短路径树(shortest paths tree,SPT):每个源节点都各自沿着到达基站或汇聚节点最短的路径传输数据,这些来自不同源节点的最短路径可能交叉,汇集在一起就形成了融合树。交叉处的中间节点都进行数据融合。当所有源节点各自的最短路径确立时,融合树就基本形成了。
③贪婪增长树(greedy incremental tree,GIT):这种算法中的融合树是依次建立的。先确定树的主干,再逐步添加枝叶。最初,贪婪增长树只有基站或汇聚节点与距离它最近的节点存在一条最短路径。然后每次都从前面剩下的源节点中选出距离贪婪增长树最近的节点连接到树上,直到所有节点都连接到树上。
上面三种算法都比较适合基于事件驱动的无线传感器网络的应用,可以在远程数据传输前进行数据融合处理,从而减少冗余数据的传输量。在数据的可融合程度一定的情况下,上面三种算法的节能效率通常为:GIT)SPT)CNS。当基站或汇聚节点与传感器覆盖监测区域距离的远近不同时,可能会造成上面算法节能的一些差异。
(2)独立的数据融合协议层
无论是与应用层还是网络层相结合的数据融合技术都存在一些不足之处:为了实现跨协议层理解和交互数据,必须对数据进行命名。采用命名机制会导致来自同一源节点不同数据类型的数据之间不能融合;打破传统各网络协议层的独立完整性,上下层协议不能完全透明;采用网内融合处理,可能具有较高的数据融合程度,但会导致信息丢失过多。
He等提出了独立于应用的数据融合机制(application independent data ag-gregatlon,AIDA),
其核心思想就是根据下一跳地址进行多个数据单元的合并融合,通过减少数据封装头部的开销,以及减少MAC层的发送冲突来达到节省能量的效果。AIDA并不关心数据内容是什么,提出的背景主要是为了避免依赖于应用的数据融合(application dependent data aggregatton,ADDA)的弊端,另外还可以增强数据融合对网络负载的适应性。当负载较轻时,不进行融合或进行低程度的融合;负载较高或MAC层冲突较重时,进行较高程度的数据融合,如图3所示,AIDA的基本功能构件主要分为两大部分:一个是网络分组的汇聚融合及取消汇聚融合功能单元,另外一个是汇聚融合控制单元。前者主要是负责对数据包的融合和解融合操作,后者是负责根据链路的忙闲状态控制融合操作的进行,调整融合的程度(合并的最大分组数)。
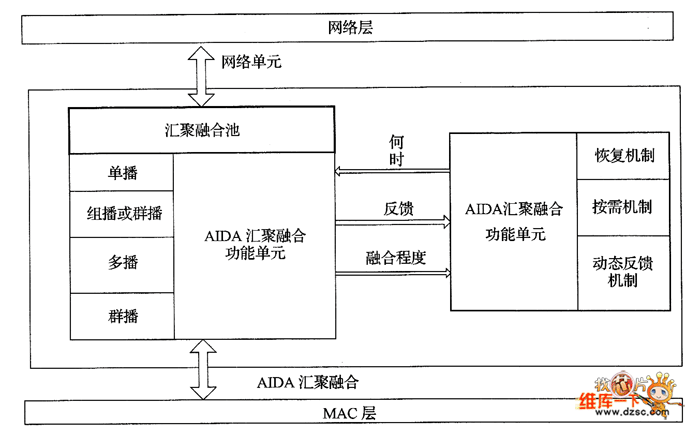
图3 AIDA的基本构件
在介绍AIDA的工作流程之前,比较一下数据融合不同方法的几种结构设计。传统的ADDA存在网络层和应用层间的跨层设计,而AIDA是增加了独立的界于MAC层和网络层之间数据融合协议层。前面提到过分层和跨层数据融合各有自己的利弊。当然,也可以将AIDA和ADDA综合起来应用,如图4所示。AIDA的提出就是为了适应网络负载的变化,可以独立于其他协议层进行数据融合,能够保证不降低信息的完整性和不降低网络端到端延迟的前提下,减轻MAC层的拥塞冲突,降低能量的消耗。
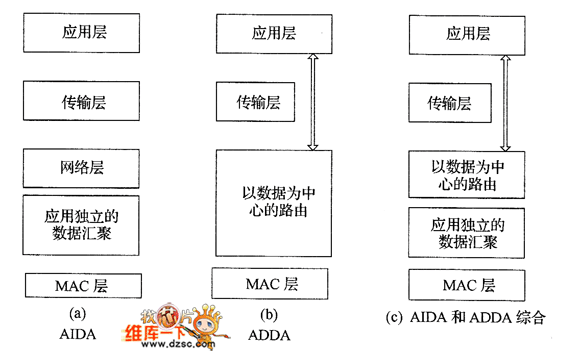
图4 数据融合不同方式的几种结构设计
AIDA的工作流程主要包括以下两个方向的操作:发送和接收。
发送主要是指从网络层到MAC层的操作,网络层发来的数据分组进入汇聚融合池,AIDA功能单元根据要求的融合程度,将下一跳地址相同的网络单元(数据)合并成一个AIDA单元,并送到MAC层进行传输。何时调用融合功能单元以及融合程度的确定都由融合控制单元来决定。
接收操作主要是从MAC层到网络层,将MAC层送上来的AIDA单元拆散为原来的网络层分组单元并送交给网络层。这样可以保证协议的模块性,并允许网络层对每个数据分组可以重新路由。