1、统计用户登录类型
#!/bin/bash
declare -A shells (定义关联数组shells)
while read ll (读取/etc/passwd,ll为变量)
do
type=`echo $ll | awk -F: '{print $7}'` (type为变量,切割ll后的变量)
let shells[$type]++
done < /etc/passwd
for i in ${!shells[@]}
do
echo "$i ::::: ${shells[$i]}"
done
~
[root@localhost ~]# bash tj2.sh
/sbin/nologin ::::: 17
/bin/sync ::::: 1
/bin/bash ::::: 3
/sbin/shutdown ::::: 1
/sbin/halt ::::: 1
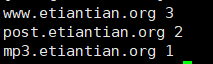
2、将域名取出并根据域名进行计数排序处理(常用)
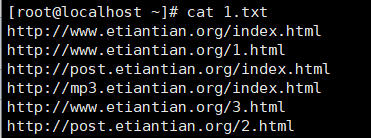
#cat 1.txt | awk -F "/+" '{ip[$2]++}END{for(i in ip) print i,ip[i]}' | sort -rnk2
3、替换硬件地址小写为大写,去掉:
# ip a | grep "link/ether" | awk -F" " '{print $2}' | tr '[a-z]' '[A-Z]'|sed 's/://g'
4、打印某行某列
# cat /etc/passwd | column -s : -t | awk 'NR==2 {print $3}' #NR表示行,$跟列($0特殊,表示本行)
# cat /etc/passwd | column -s : -t | awk 'NR==2,NR==4 {print $3}' #行的范围
# cat /etc/passwd | column -s : -t | awk 'NR==1' #只要某行时,不需要跟print就能出来
root x 0 0 root /root /bin/bash
注意:column -t 表示把输出以表格显示,-s参数是指定输出中已经存在的字符变为空格符。
5、sed和cut
# sed -n 1,5p file1 | cut -d : -f1-6 (1,5p打印范围,-d 指定分隔符,-f字符串) root:x:0:0:root:/root bin:x:1:1:bin:/bin daemon:x:2:2:daemon:/sbin adm:x:3:4:adm:/var/adm lp:x:4:7:lp:/var/spool/lpd
# sed -n 1,5p file1 | cut -c1-6(-c从左往右一个单字符就算一个整体) root:x bin:x: daemon adm:x: lp:x:4 打印1行5列 # sed -n 4p file1 |cut -c 5 (文本里是连续纯字符,-d 和 -f 组合就不适用了) 5
6、awk拼接打印
# docker images | grep 192 | awk 'BEGIN{OFS=":"}''{print $1,$2}' > 1.txt
# cat images.txt | awk '{print $1 ":" $2}'
OFS=":"表示以:为拼接符号
或者
# docker images | grep harbor | awk '{print "docker tag" " " $3 " " $1":"$2}'
docker tag 18036ee471bc harbor.cetccloud.com/amd64/redis-photon:v1.8.2
docker tag ad798fd6e618 harbor.cetccloud.com/amd64/harbor-registryctl:v1.8.2
docker tag 081bfb3dc181 harbor.cetccloud.com/amd64/registry-photon:v2.7.1-patch-2819-v1.8.2
docker tag 1592a48daeac harbor.cetccloud.com/amd64/nginx-photon:v1.8.2
docker tag 42ad5ef672dd harbor.cetccloud.com/amd64/harbor-log:v1.8.2
docker tag 623ed0095966 harbor.cetccloud.com/amd64/harbor-jobservice:v1.8.2
docker tag 03d6daab10c7 harbor.cetccloud.com/amd64/harbor-core:v1.8.2
docker tag 41e264a7980b harbor.cetccloud.com/amd64/harbor-portal:v1.8.2
docker tag 927ecd68ee1f harbor.cetccloud.com/amd64/harbor-db:v1.8.2
7、awk -F分隔符 'BEGIN { 初始化 } { 循环执行部分 } END { 结束处理 }' file1 file2
NR放在循环执行部分 # awk '{print NR,$0}' aa.txt,表示行数,显示行号。 1 aadak 2 ksdlb 3 d;smlb 4 fl; b 放在 END { 结束处理 }',表示最后一行。 # awk 'END{print NR,$0}' aa.txt 4 fl; b
8、求和(docker images镜像的大小)
[root@localhost ~]# cat 1.sh |grep MB | awk '{sum+=$7}END{print sum}'
7256
[root@localhost ~]# cat 1.sh |grep MB| awk '{print sum+=$7}END{print sum}'
697
1105
1513
1926
2359
2773
3693
4118
4543
5030
5623
6465
6848
7256
7256
9、tr常用操作
[root@localhost ~]# echo 1 2 3 4 5 6 7 8 9 | xargs -n1 | echo $[ $(tr ' ' '+') 0 ] 45
注:$[]表示计算,0表示末尾要加的数,因为会9后面的回车符会换成+号
[root@localhost ~]# echo 1 2 3 4 5 6 7 8 9 | xargs -n1 | echo $[ $(tr ' ' '+') 1 ]
46
[root@localhost ~]# echo 1 2 3 4 5 6 7 8 9 | xargs -n1 | echo $[ $(tr ' ' '+') 2 ]
47 [root@localhost ~]# echo 1 2 3 4 5 6 7 8 9 |tr ' ' '+' 1+2+3+4+5+6+7+8+9 [root@localhost ~]# echo 1 2 3 4 5 6 7 8 9 |tr ' ' '+'|bc 45
-s 压缩重复的部分或者是把多个字符当做一个整体
[root@localhost ~]# cat 1.sh |grep MB| awk '{print $7}'| tr "MB
" '+'
697+++408+++408+++413+++433+++414+++920+++425+++425+++487+++593+++842+++383+++408+++
[root@localhost ~]# cat 1.sh |grep MB| awk '{print $7}'| tr -s "MB
" '+'
697+408+408+413+433+414+920+425+425+487+593+842+383+408+
-d 删除
[root@localhost ~]# cat 1.sh |grep MB| awk '{print $7}'
697MB
408MB
408MB
[root@localhost ~]# cat 1.sh |grep MB| awk '{print $7}'|tr -d MB
697
408
408
10、生成任意长度的字符串
# head /dev/urandom | tr -dc A-Za-z0-9 | head -c 12 FZmEl60TxdvX