性能涉及的层面很多,但是在操作层面,主要有表结构设计优化、索引优化和查询优化

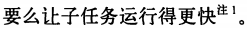
查询的生命周期大致可以分为,从客户端、到服务端、在服务器上解析、生成执行计划、执行、返回结果给客户端
sql执行流程




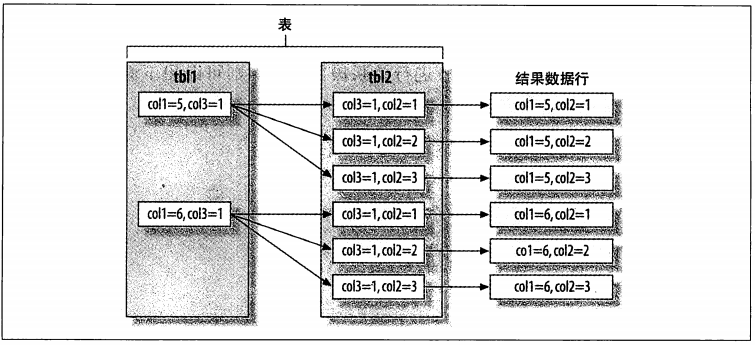
具体优化技巧
1.消除外连接

2.消除子查询
尽量用join代替子查询,虽说mysql查询优化器会进行优化,但是我们自己优化掉以后,也就省去了mysql优化的部分时间,同样可以提升性能

3.消除连接
尽量单表查询,或者使用常量
4.只查询需要的字段
节省流量,减少mysql读取数据的量,有些时候能利用索引覆盖
5.避免使用count(*)
统计操作可以放到从库中进行
6.避免多余的排序
如果没有索引,排序会使用filesort(内存或者磁盘),在不需要排序时不要排序,group by 会默认按照分组字段排序,可以使用order by null来禁止排序
7.尽量不要在DB里面进行排序
同上,1000条以内的数据的排序,尽量在应用层做,应用层方便做集群,cpu和内存都很容易扩展
8.不要在DB里面进行复杂计算
计算密集型任务放到应用层做,应用层可以方便的做集群,计算能力很容易扩展
9.避免全模糊或者前缀模糊查询
无法使用索引
10.使用IN代替OR

当where字句中存在多个条件以“或”并存的时候,Mysql的查询优化器并没有很好的解决其执行计划优化问题,再加上Mysql特有的Sql与Storage
分层架构方式,造成其性能比较低下,可以使用union all或者是union(去重、排序)的方式代替“or”会得到更好的效果
11.禁止隐式转换,数值类型禁止加引号,字符串必须加引号
隐式转换需要消耗cpu计算资源,应避免DB做计算任务
12.禁止使用负向查询,如not in、!=、not like
无法使用索引
13.慎重选择select for update
加锁造成阻塞
14.尽量是用union all代替union
union和union all的差异主要是前者需要将两个(多个)结果集合合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的cpu运算,加大资源消耗及延迟。
所以当可以确认不可能出现重复结果集或者不在乎重复结果集的时候,尽量使用union all代替union
15.尽量早过滤
将过滤性好(可以排除更多的数据)的条件放的更靠前;mysql的查询是嵌套查询,第一层的数据越少,查询效率越高。
16.禁止在主库执行统计类query
统计操作可以放到从库中进行
17.索引覆盖
由于索引的数据结构也是B+Tree,key是索引字段的值,value是聚集索引的值,所以如果查询的字段都是索引字段,则直接从索引的数据结构中就可以取到字段值,而不用再去根据聚集索引去查找整行的数据。
18.Group by


19. limit

