代码编写思路:

学习知识点:
1.class=a b(a假设是字体-宋体,b是颜色-蓝色;class中可以同时有两个参数a,b(宋体+蓝色),两者用空格隔开即可)
2.拓展1:想要soup到某个元素,且该元素对应class中含有多个值,我们可以根据class中元素出现的规律,找到共性出现的元素去编写soup中内容。
例如 想soup 中的class可以找到相关规律,发现想找的元素对应class中都含有“l_post_bright”那么写成以下形式即可找到相关的元素对应内容。
中的class可以找到相关规律,发现想找的元素对应class中都含有“l_post_bright”那么写成以下形式即可找到相关的元素对应内容。
soup.find_all('div', class_="l_post_bright") 即可。
百度贴吧-中国好声音评论爬爬
1 # coding=utf-8 2 import csv 3 import random 4 import io 5 from urllib import request,parse,error 6 import http.cookiejar 7 import urllib 8 import re 9 from bs4 import BeautifulSoup 10 11 # 爬爬网址 12 #homeUrl ="http://tieba.baidu.com" #贴吧首页 13 subUrl = "http://tieba.baidu.com/f?kw=%E4%B8%AD%E5%9B%BD%E5%A5%BD%E5%A3%B0%E9%9F%B3&ie=utf-8&pn=0" #中国好声音贴吧页面 14 #childUrl="http://tieba.baidu.com/p/5825125387" #中国好声音贴吧第一条 15 16 #存储csv文件路径 17 outputFilePath = "E:scriptpython-scriptlaidutiebapapacsvfile_output.csv" 18 19 def GetWebPageSource(url): 20 21 values = {} 22 data = parse.urlencode(values).encode('utf-8') 23 24 # header 25 user_agent = "" 26 headers = {'User-Agent':user_agent,'Connection':'keep-alive'} 27 28 # 声明cookie 声明opener 29 cookie_filename = 'cookie.txt' 30 cookie = http.cookiejar.MozillaCookieJar(cookie_filename) 31 handler = urllib.request.HTTPCookieProcessor(cookie) 32 opener = urllib.request.build_opener(handler) 33 34 # 声明request 35 request=urllib.request.Request(url, data, headers) 36 # 得到响应 37 response = opener.open(request) 38 html=response.read().decode('utf-8') 39 # 保存cookie 40 cookie.save(ignore_discard=True,ignore_expires=True) 41 42 return html 43 44 # 将读取的内容写入一个新的csv文档 54 # 主函数 55 if __name__ == "__main__": 56 #outputString = [] 57 maxSubPage=2 #中国好声音贴吧翻几页设置? 58 m=0#起始页数 59 with open("E:scriptpython-scriptlaidutiebapapacsvfile_output.csv", "w", newline="", encoding='utf-8') as datacsv: 60 headers = ['title', 'url', 'comment'] 61 csvwriter = csv.writer(datacsv, headers) 62 for n in range(1, int(maxSubPage)): 63 subUrl = "http://tieba.baidu.com/f?kw=%E4%B8%AD%E5%9B%BD%E5%A5%BD%E5%A3%B0%E9%9F%B3&ie=utf-8&pn=" + str(m) + ".html" 64 print(subUrl) 65 subhtml = GetWebPageSource(subUrl) 66 #print(html) 67 # 利用BeatifulSoup获取想要的元素 68 subsoup = BeautifulSoup(subhtml, "lxml") 69 #打印中国好声音贴吧页标题 70 print(subsoup.title) 71 #打印中国好声音第一页贴吧标题 72 all_titles = subsoup.find_all('div', class_="threadlist_title pull_left j_th_tit ") # 提取有关与标题 73 for title in all_titles: 74 print('--------------------------------------------------') 75 print("贴吧标题:"+title.get_text())#贴吧各标题题目 76 commentUrl = str(title.a['href']) 77 #print(commitment) 78 #评论页循环需要改改,maxchildpage 79 childPage = 1#评论页翻页变量 80 maxChildPage = 6#【变量】几页就翻几页设置? 81 for n in range(1, int(maxChildPage)): 82 childUrl = "http://tieba.baidu.com" + commentUrl +"?pn=" + str(childPage) 83 print("贴吧Url:"+childUrl) 84 childhtml = GetWebPageSource(childUrl) 85 childsoup = BeautifulSoup(childhtml, "lxml") 86 all_comments = childsoup.find_all('div', class_="d_post_content_main") # 提取有关与评论 87 for comment in all_comments: 88 print("用户评论:" + comment.get_text()) # 贴吧各标题题目 89 #outputString.append([title.get_text(), childUrl, comment.get_text()]) 90 csvwriter.writerow([title.get_text(), childUrl, comment.get_text()]) 91 print('--------------------------------------------------') 92 childPage = childPage + 1 93 m = m + 50 # 翻页控制,通过观察发现,每页相差50
跑完了成果图

csv文档中效果

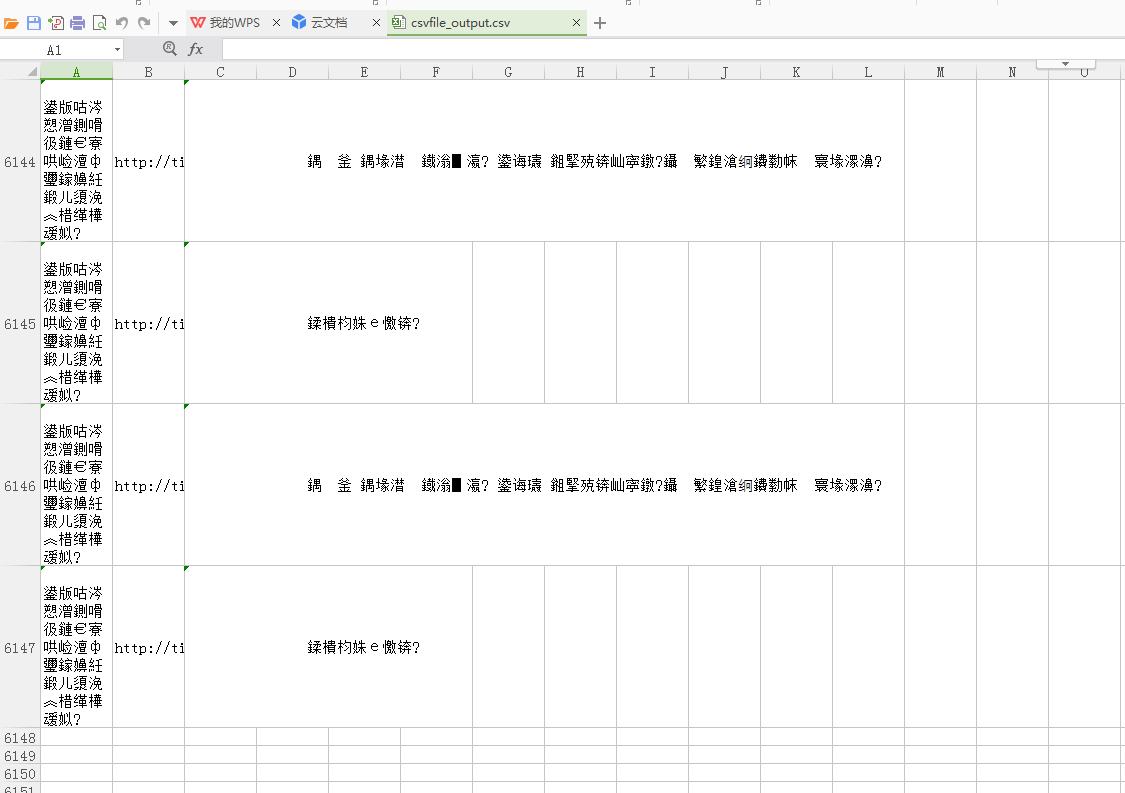
上方生成的csv文件通过txt记事本打开另存为ANIS编码方式,然后在通过csv打开就不会再乱码了,解决csv打开乱码问题相关可以参考博文:https://www.cnblogs.com/zhuzhubaoya/p/9675203.html
----------------------------------------------------------------------------------------
升级版-待完善代码:
# coding=utf-8 import csv import random import io from urllib import request,parse,error import http.cookiejar import urllib import re from bs4 import BeautifulSoup # 爬爬网址 #homeUrl ="http://tieba.baidu.com" #贴吧首页 subUrl = "http://tieba.baidu.com/f?kw=%E4%B8%AD%E5%9B%BD%E5%A5%BD%E5%A3%B0%E9%9F%B3&ie=utf-8&pn=0" #中国好声音贴吧页面 #childUrl="http://tieba.baidu.com/p/5825125387" #中国好声音贴吧第一条 #存储csv文件路径 outputFilePath = "F:Pythonscriptspestpapacsvfile_output.csv" def GetWebPageSource(url): values = {} data = parse.urlencode(values).encode('utf-8') # header user_agent = "" headers = {'User-Agent':user_agent,'Connection':'keep-alive'} # 声明cookie 声明opener cookie_filename = 'cookie.txt' cookie = http.cookiejar.MozillaCookieJar(cookie_filename) handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) # 声明request request=urllib.request.Request(url, data, headers) # 得到响应 response = opener.open(request) html=response.read().decode('utf-8') # 保存cookie cookie.save(ignore_discard=True,ignore_expires=True) return html # 将读取的内容写入一个新的csv文档 # 主函数 if __name__ == "__main__": #outputString = [] maxSubPage=2 #中国好声音贴吧翻几页设置? m=0#起始页数 with open("F:Pythonscriptspestpapacsvfile_output.csv", "w", newline="", encoding='utf-8') as datacsv: headers = ['title', 'url', 'comment'] csvwriter = csv.writer(datacsv, headers) for n in range(1, int(maxSubPage)): subUrl = "http://tieba.baidu.com/f?kw=%E4%B8%AD%E5%9B%BD%E5%A5%BD%E5%A3%B0%E9%9F%B3&ie=utf-8&pn=" + str(m) + ".html" print(subUrl) subhtml = GetWebPageSource(subUrl) #print(html) # 利用BeatifulSoup获取想要的元素 subsoup = BeautifulSoup(subhtml, "lxml") #打印中国好声音贴吧页标题 print(subsoup.title) #打印中国好声音第一页贴吧标题 all_titles = subsoup.find_all('div', class_="threadlist_title pull_left j_th_tit ") # 提取有关与标题 for title in all_titles: print('--------------------------------------------------') print("贴吧标题:"+title.get_text())#贴吧各标题题目 commentUrl = str(title.a['href']) #print(commitment) #评论页循环需要改改,maxchildpage childPage = 1#评论页翻页变量 maxChildPage = 6#【变量】几页就翻几页设置? csvwriter.writerow(['title', 'url', 'comment']) for n in range(1, int(maxChildPage)): childUrl = "http://tieba.baidu.com" + commentUrl +"?pn=" + str(childPage) print("贴吧Url:"+childUrl) childhtml = GetWebPageSource(childUrl) childsoup = BeautifulSoup(childhtml, "lxml") #all_comments = childsoup.find_all('div', class_="d_post_content_main") # 提取有关与评论 allCommentList = childsoup.find_all('div', class_="l_post_bright") for n in allCommentList: authorName = n.find_all('li', class_="d_name") for i in authorName:#写成for循环可以规避报错,如果有,走0条,不会报错。 print("作者:" + i.get_text().strip()) authorLev = n.find_all('div', class_="d_badge_lv") for i in authorLev: print("等级:" + i.get_text().strip()) all_comments = n.find_all('div', class_="d_post_content_main") for comment in all_comments: print("评论:" + comment.get_text().strip()) csvwriter.writerow([title.get_text(), childUrl, comment.get_text()]) print('--------------------------------------------------') childPage = childPage + 1 m = m + 50 # 翻页控制,通过观察发现,每页相差50
————————————————————————————————————————————————————————————————————————————
完善后代码:
# coding=utf-8 import csv from urllib import request,parse import http.cookiejar import urllib from bs4 import BeautifulSoup # 爬爬网址 #homeUrl ="http://tieba.baidu.com" #贴吧首页 subUrl = "http://tieba.baidu.com/f?kw=%E4%B8%AD%E5%9B%BD%E5%A5%BD%E5%A3%B0%E9%9F%B3&ie=utf-8&pn=0" #中国好声音贴吧页面 #childUrl="http://tieba.baidu.com/p/5825125387" #中国好声音贴吧第一条 #存储csv文件路径 outputFilePath = "E:scriptpython-scriptlaidutiebapapacsvfile_output.csv" def GetWebPageSource(url): values = {} data = parse.urlencode(values).encode('utf-8') # header user_agent = "" headers = {'User-Agent':user_agent,'Connection':'keep-alive'} # 声明cookie 声明opener cookie_filename = 'cookie.txt' cookie = http.cookiejar.MozillaCookieJar(cookie_filename) handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) # 声明request request=urllib.request.Request(url, data, headers) # 得到响应 response = opener.open(request) html=response.read().decode('utf-8') # 保存cookie cookie.save(ignore_discard=True,ignore_expires=True) return html #打印子贴吧评论区 def PrintUserComment(childUrl): childhtml = GetWebPageSource(childUrl) childsoup = BeautifulSoup(childhtml, "lxml") allCommentList = childsoup.find_all('div', class_="l_post_bright") for n in allCommentList: print('--------------------------------------------------') authorName = n.find_all('li', class_="d_name") for i in authorName: # 写成for循环可以规避报错,如果有,走0条,不会报错。 authorName = i.get_text().strip() print("作者:" + authorName) authorLev = n.find_all('div', class_="d_badge_lv") for i in authorLev: authorLev = i.get_text().strip() print("等级:" + authorLev) all_comments = n.find_all('div', class_="d_post_content_main") for comment in all_comments: commentRes = comment.get_text() print("评论:" + comment.get_text().strip()) csvwriter.writerow([titleName, childUrl, authorName, authorLev, commentRes]) print('--------------------------------------------------') # 主函数 if __name__ == "__main__": # 几个控制变量初值定义 m = 0 # 起始页数 maxSubPage = 2 # 中国好声音贴吧翻几页设置? maxChildPage = 6 # 【变量】几页就翻几页设置? # 开始遍历贴吧内容,顺序:父贴吧-子贴吧-评论区,并将以下子贴吧评论内容写入csv文件 with open("E:scriptpython-scriptlaidutiebapapacsvfile_output.csv", "w", newline="", encoding='utf-8') as datacsv: headers = [] csvwriter = csv.writer(datacsv, headers) # 父贴吧页面处理 for n in range(1, int(maxSubPage)): subUrl = "http://tieba.baidu.com/f?kw=%E4%B8%AD%E5%9B%BD%E5%A5%BD%E5%A3%B0%E9%9F%B3&ie=utf-8&pn=" + str(m) + ".html"# 父贴吧链接 print(subUrl) subhtml = GetWebPageSource(subUrl) subsoup = BeautifulSoup(subhtml, "lxml") print(subsoup.title)# 打印父贴吧标题 # 遍历父贴吧下子贴吧标题 all_titles = subsoup.find_all('div', class_="threadlist_title pull_left j_th_tit ") # 提取有关与标题 for title in all_titles: titleName = title.get_text() print("贴吧标题:"+titleName)# 打印中国好声音父贴吧页各子贴吧title commentUrl = str(title.a['href'])# 取子贴吧网址链接规律值'href' csvwriter.writerow(['贴吧标题', '链接', '用户姓名', '用户等级', '评论'])# 定义打印评论csv文件标题行 childPage = 1 # 评论页翻页变量 # 遍历子贴吧下评论页 for n in range(1, int(maxChildPage)): childUrl = "http://tieba.baidu.com" + commentUrl +"?pn=" + str(childPage) print("贴吧Url:"+childUrl) # 打印子贴吧评论区 PrintUserComment(childUrl) childPage = childPage + 1 m = m + 50 # 翻页控制,通过观察发现,每页相差50
运行后效果:
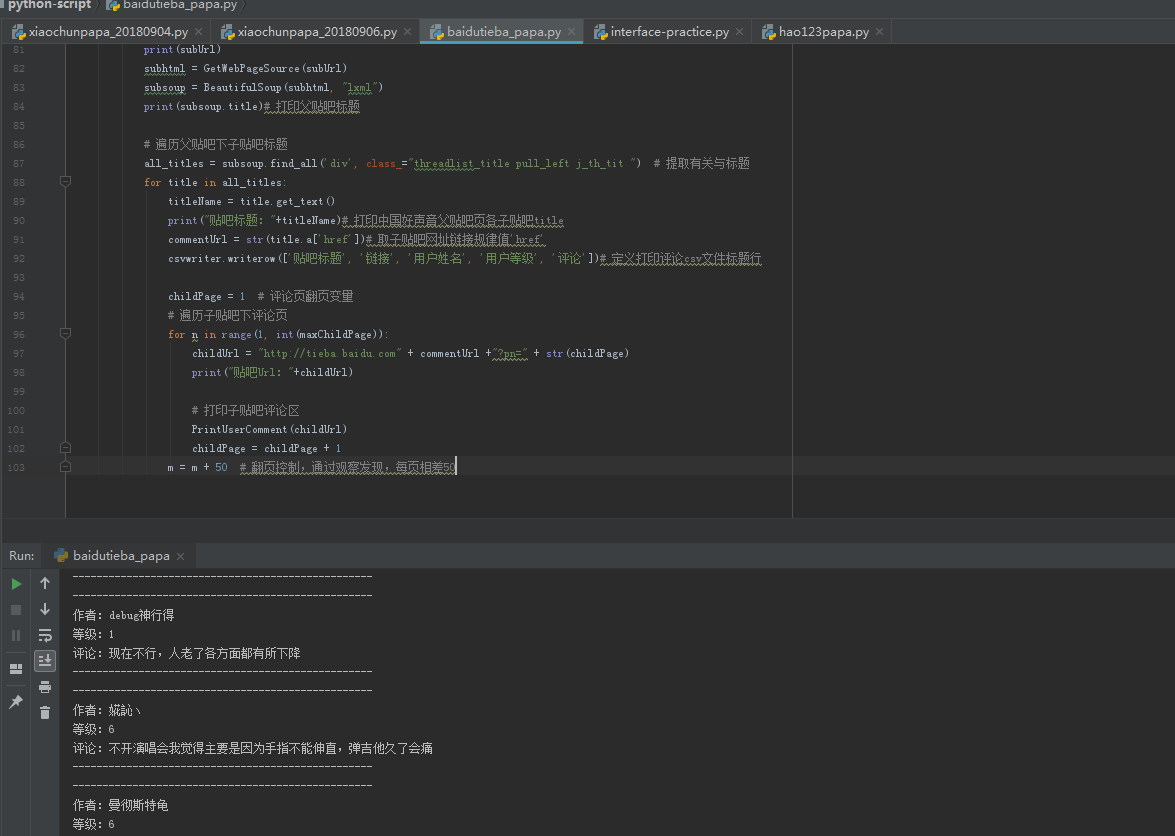
自动生成csv效果(如果乱码需要按照上面的方法进行转码后再打开就OK了):
