1、相关描述
using index 和using where只要使用了索引我们基本都能经常看到,而using index condition则是在mysql5.6后新加的新特性,我们先来看看mysql文档对using index condition的描述

附上mysql文档链接:https://dev.mysql.com/doc/refman/5.7/en/index-condition-pushdown-optimization.html
简单来说,mysql开启了ICP的话,可以减少存储引擎访问基表的次数
2、预备知识
了解这三个参数,首先你需要知道的是,mysql查询数据的流程,已经索引的相关概念,这里的测试表如下
CREATE TABLE `test` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `bid` int unsigned NOT NULL DEFAULT '0', `status` int NOT NULL DEFAULT '1', `rid` int NOT NULL, `createTime` int unsigned NOT NULL, `updateTime` int unsigned NOT NULL, PRIMARY KEY (`id`), KEY `idx_bid_rid_status` (`bid`,`rid`,`status`) ) ENGINE=InnoDB AUTO_INCREMENT=10001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
该表有两个索引,分别是id(主键索引)和idx_bid_rid_status(二级索引),假如说有个查询是
select * from test where bid = 1;
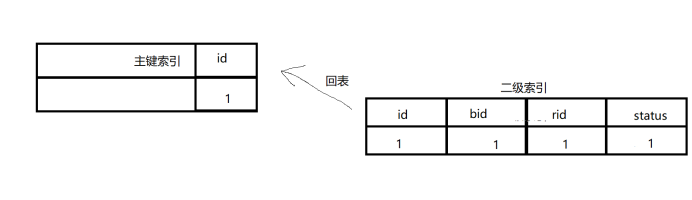
那么其查询流程如下(只简单的说明)
1、首先遍历idx_bid_rid_status索引中的数据,直到不满足bid=10的数据后,回主键索引查询数据(回表),注意这里的回表的概念,这个是等下解释extra那三个值的重要概念
2、在主键索引中查找对应的数据,然后返回,如下图所示
3、using index,using where,using index condition 分析
- using index:使用覆盖索引,不需要回表就直接从二级索引返回数据
- using where: 需要在服务层过滤数据(mysql分为服务层和存储引擎层)
- using index condition:需要回表查询数据,但是有部分数据是在二级索引过滤后,再回表查询数据,减少了回表查询的数据行数
用上面的测试表进行验证说明
创建存储过程,插入1w条数据,代码如下
DROP PROCEDURE IF EXISTS create_service_data$$ create procedure create_service_data(size INT) begin START TRANSACTION; SET @id=0; WHILE @id<size DO SET @bid=@id+1; SET @status = FLOOR(RAND() * 100000); SET @rid = FLOOR(RAND() * 100000); SET @createTime = FLOOR(RAND() * 100000); SET @updateTime = 90000; INSERT INTO test.test(id, bid,status,rid,createTime,updateTime)VALUES(null,@bid,@status,@rid,@createTime,@updateTime); SET @id=@id+1; end while ; COMMIT; end$$ delimiter ;
1、using index

bid,status的数据在idx_bid_rid_status中存在(不是*查找所有数据),所以能从idx_bid_rid_status直接返回
2、using where

虽然使用了idx_bid_rid_status索引,但是createTime不存在在idx_bid_rid_status索引中,所以回表后才在服务层过滤createTime
3、using index condition

那么,重点来了,根据最左前缀原则,idx_bid_rid_status的索引有效范围只到了bid这个数据,之后就需要会主键索引进行过滤,而这个地方,就是icp优化的地方,通俗点来说,就是idx_bid_rid_status本来就有status这个数据,为啥我还非要会主键去过滤这个数据呢?完全是可以在这个索引上过滤status这个数据的,这就是icp,目的就是近可能减少回表查询的数据量。举个例子,bid=10的数据有100条,其中status > 100的数据有20条,那么使用icp之后,我只需要在主键索引查找80条数据返回即可,不需要查100条数据
有趣的是,mysql中extra不仅仅值单一输出一种,有时候会多种混合输出,如下所示

这个其实就是在二级索引过滤后(使用了icp优化),还需要回表在服务层进行过滤数据(createTime)再返回
那么,看到这篇博客的小伙伴们可以用以上思路去分析分析下面的这个输出,欢迎在评论区中留下你们的分析

Ps 不同版本的mysql explain输出的内容会有差异,本人用的版本是8.0.26