读《OneData建设探索之路:SaaS收银运营数仓建设》 后感。
版权声明:本文为CSDN博主「乔治大哥」的原创文章
原文链接:https://blog.csdn.net/qq_41946557/article/details/103002772
1. 什么是OneData
首先OneData是一种方法论,是由阿里巴巴提出的一种数据建设标准。
即建立企业统一的数据公共层,从设计、开发、部署和使用上保障了数据口径的规范和统一,实现数据资产全链路管理,提供标准数据输出。

2. 为什么要用OneData(背景)
想象一下,在业务需求和数据量越来越多的情况下,一个数据质量有问题的数据仓库会给开发带来什么后果呢?
-
缺乏统一的业务和技术标准,如:开发规范、指标口径和交付标准不统一。
-
缺乏有效统一的数据质量监控,如:列值信息不完整和不准确,SLA时效无法保障等。
-
业务知识体系散乱不集中,导致不同研发人员对业务理解存在较大的偏差,造成产品的开发成本显著增加。
-
数据架构不合理,主要体现在数据层之间的分工不明显,缺乏一致的基础数据层,缺失统一维度和指标管理。
所以,前期具有可扩展性的规划就显得尤其重要,这时候OneData就起作用了。
3. 如何实现OneData
3.1. OneData的特性和需要达到的效果
统一性:各需求统一文档管理格式和路径、统一文档模板和应用迭代。
唯一性:码、码值、指标、维度命名唯一。
规范性:字段、表名等统一命名规范。
高扩展效果:快速支撑多个业务,满足临时需求等个性化需求,这里的高扩展性不止是数据的高可用和扩展性,也要考虑人员接到陌生需求时是否能够快速了解业务需求,快速上手。
强复用效果:数据分层,分主题,数据沉淀降低ETL成本。
低成本效果:数据合理分层...降低硬件成本,统一规范化业务逻辑,降低人员成本。

3.2 OneData实践之业务统一
数据来源于业务并支撑着业务的发展。因此,数仓建设的基石就是对于业务的把控,数仓建设者即是技术专家,但是业务知识沉淀在各个需求里,而且不同的人负责不同的业务,就会导致业务知识体系分散。针对这些问题,我们提出统一业务,构建全局知识库,进而保障对业务认知的一致性。


3.3 OneData实践之统一设计模型
规范化模型分层、数据流向和主题划分,从而降低研发成本,增强指标复用性,并提高业务的支撑能力。
3.3.1 模型分层
优秀可靠的数仓体系,往往需要清晰的数据分层结构,即要保证数据层的稳定又要屏蔽对下游的影响,并且要避免链路过长。

3.3.2 模型数据流向
重构前,存在大量的烟囱式开发(基于单个项目设计流程)、分层应引用不规范性及数据链路混乱、血缘关系很难追溯和SLA时效难保障等问题。
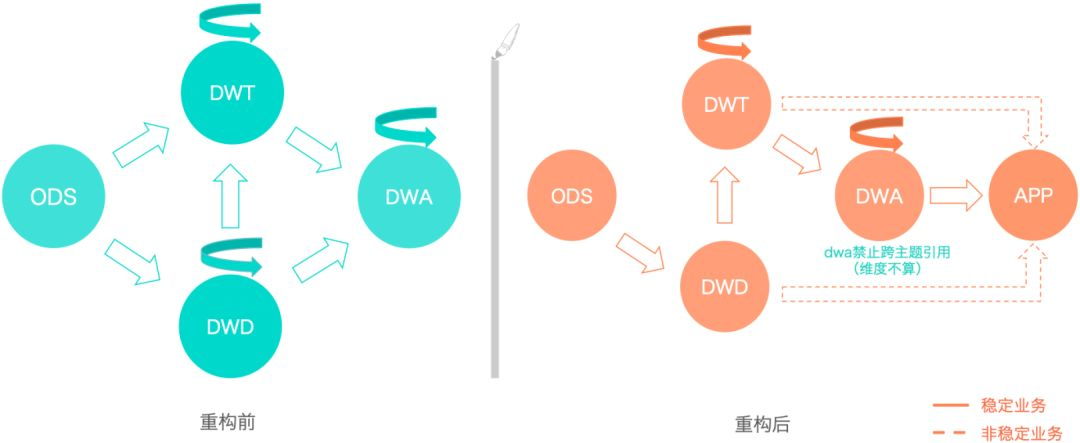
重构之后,稳定业务按照标准的数据流向进行开发,即ODS-->DWD-->DWA-->APP。非稳定业务或探索性需求,可以遵循ODS->DWD->APP或者ODS->DWD->DWT->APP两个模型数据流。在保障了数据链路的合理性之后,又在此基础上确认了模型分层引用原则:
正常流向:ODS>DWD->DWT->DWA->APP,当出现ODS >DWD->DWA->APP这种关系时,说明主题域未覆盖全。应将DWD数据落到DWT中,对于使用频度非常低的表允许DWD->DWA。
-
尽量避免出现DWA宽表中使用DWD又使用(该DWD所归属主题域)DWT的表。
-
同一主题域内对于DWT生成DWT的表,原则上要尽量避免,否则会影响ETL的效率。
-
DWT、DWA和APP中禁止直接使用ODS的表, ODS的表只能被DWD引用。
-
禁止出现反向依赖,例如DWT的表依赖DWA的表。
3.4 主题划分
传统行业如银行、制造业、电信、零售等行业中,都有比较成熟的主题划分,如BDWM、FS-LDM、MLDM等等。但从实际调研情况来看,主题划分太抽象会造成对业务理解和开发成本较高,不适用互联网行业。因此,结合各层的特性,我们提出了两类主题的划分:面向业务、面向分析。
-
面向业务:按照业务进行聚焦,降低对业务理解的难度,并能解耦复杂的业务。我们将实体关系模型进行变种处理为实体与业务过程模型。实体定义为业务过程的参与体;业务过程定义是由多个实体作用的结果,实体与业务过程都带有自己特有的属性。根据业务的聚合性,我们把业务进行拆分,形成了七大核心主题。
-
面向分析:按照分析聚焦,提升数据易用性,提高数据的共享与一致性。按照分析主体对象不同及分析特征,形成分析域主题在DWA进行应用,例如销售分析域、组织分析域。
4.实现细节(此处是美团技术团队的规范细节,可参考)
模型是整个数仓建设基石,规范是数仓建设的保障。
4.1 词根
词根是维度和指标管理的基础,划分为普通词根与专有词根,提高词根的易用性和关联性。
-
普通词根:描述事物的最小单元体,如:交易-trade,金额-amount。
-
专有词根:具备约定成俗或行业专属的描述体,如:美元-USD。
4.2 表命名规范
- 表名、字段名采用一个下划线分隔词根(示例:clienttype->client_type)。
- (PS:我们公司采用的字段命名全是中文拼音首字母,刚进公司时还觉得有点low,但是当我实际了解业务时,就能理解了,业务实在复杂,字段中文名可能几十个字,这样命名效率高,但是文档得写清楚,做到有案可查)
- 每部分使用小写英文单词,属于通用字段的必须满足通用字段信息的定义。
- 表名、字段名需以字母为开头。
- 表名、字段名最长不超过64个英文字符。
- 优先使用词根中已有关键字(数仓标准配置中的词根管理),定期Review新增命名的不合理性。
- 在表名自定义部分禁止采用非标准的缩写。
4.3 不同分层模型的表命名规范一致
表名称 = 类型 + 业务主题 + 子主题 + 表含义 + 存储格式 + 更新频率 +结尾,如下图所示:
口径可以不同,规范即可。
4.4 指标命名规范
结合指标的特性以及词根管理规范,将指标进行结构化处理。
4.5 清洗规范
确认了字段命名和指标命名之后,根据指标与字段的部分特性,我们整理出了整个数仓可预知的清洗规范,比如金额类型:number(22.2) ,日期类型:YYYY-MM-DD: