1、对数据点进行拟合就是回归。
利用logistics回归分类的主要思想:根据现有数据对分类边界线建立回归公式,以此进行分类。
为了实现回归分类器,可以在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和带入sigmoid函数中,进而得到一个范围在0-1之间的数值。大于0.5的数据被分为1类,小于0.5分为0类。因此,logistics回归也可以看成是一种概率估计。
目前,问题转化为如何求取最佳回归系数,即为优化问题。
2、基于最优化方法的最佳回归系数确定
sigmoid函数的输入记为z,由下面的公式得出:
z=w0*x0+w1*x1+w2*x2+...+wn*xn
采用相量的写法:
z=W*Xt
W表示系数行向量,X表示特征值行向量,Xt表示X的转置矩阵。
2.1、梯度上升法
基本思想:要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。梯度上升算法到达每个点后都会重新估计移动的方向。每次迭代的移动量记为步长a。迭代公式为:
w:=w+a*Dwf(w)
2.2、训练算法:使用梯度上升找到最佳参数
每个数据点包含两个特征:x1、x2
测试用数据集内容如下:总共100条数据
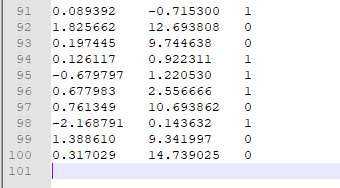
from numpy import *
def loadDataSet():
dataMat=[]
labelMat=[]
f=open('testSet.txt')
for line in f.readlines():
lineArrary=line.strip().split()
dataMat.append([1.0,float(lineArrary[0]),float(lineArrary[1])])
labelMat.append(int(lineArrary[2]))
return dataMat,labelMat #返回的是list
def sigmoid(inx):
return 1.0/(1+exp(-inx))
def gradAscent(dataMatIn,classLabels):
dataMatrix = mat(dataMatIn) # 转换为numpy矩阵数据类型 100*3
labelMat = mat(classLabels).transpose() #转置 100*1
m,n=shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = ones((n, 1)) #3*1
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights) #100*3 3*1 h:100*1
error = (labelMat - h) #100*1
weights = weights + alpha * dataMatrix.transpose() * error #最大似然估计
return weights
测试:
dataArraryay,labelMat=loadDataSet() result=gradAscent(dataArraryay,labelMat) print(result) 输出: [[ 4.12414349] [ 0.48007329] [-0.6168482 ]]
result即为用测试文件训练出的最佳回顾系数。
2.3、分析数据:画出决策边界
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat, labelMat = loadDataSet() #list
dataArrary = array(dataMat) #数组 100*3
n = shape(dataArrary)[0] #100,对应100个训练数据
xcord1 = []
ycord1 = []
xcord2 = []
ycord2 = []
for i in range(n):
if int(labelMat[i]) == 1: #如果此条训练数据是1类
xcord1.append(dataArrary[i, 1]) #dataArrary[i, 1]为第二列数据,作为作图的横坐标
ycord1.append(dataArrary[i, 2]) #纵坐标
else: #0类
xcord2.append(dataArrary[i, 1]) #横坐标
ycord2.append(dataArrary[i, 2]) #纵坐标
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=20, c='red',marker='s') #s表示大小,c表示颜色,marker表示形状,默认是圆,marker='s'表示方形
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0] - weights[1] * x) / weights[2]
# sigmoid函数中,x=0是分解条件,对应y=0.5,所以映射到特征值就应该是:w0*x0+w1*x1+w2*x2=0,其中x0=1,x1代表的是横坐标,x2代表的是纵坐标
#解得:x2=-(w0+w1*x1)/w2 ----> y=-(w0+w1*x)/w2 即为决策边界
ax.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
测试:
dataArraryay,labelMat=loadDataSet() result=gradAscent(dataArraryay,labelMat) plotBestFit(result.getA()) #getA() 矩阵转换成数组,与mat()相反
输出:
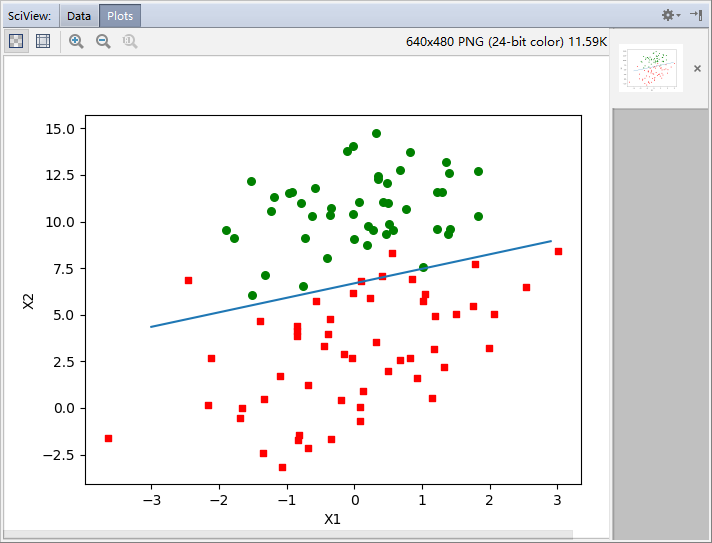
有五个数据分类错误。
2.4、训练算法:随机梯度上升
前面讲的梯度上升算法在每次更新回归系数时都需要遍历整个数据集,算法的空间复杂度较大。
改进方法:一次仅使用一个样本点来更新回归系数,该方法称为随机梯度上升算法。
由于可以在新样本到来时进行增量式更新,因而随机梯度上升算法是一个在线学习算法。与“在线学习”相对应,一次处理所有数据称为“批处理”。
随机梯度上升算法:并不是随机选取一个样本,而是一次选取一个样本用来更新回归系数。
def stocGradAscent0(dataMatrix, classLabels): #随机梯度上升算法,没有使用矩阵,所有变量的数据类型都是数组
dataMatrix = array(dataMatrix)
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix[i] * weights)) #dataMatrix[i]和weights都是1*3的数组,执行的是对应元素相乘
error = classLabels[i] - h #h,error都是数值
weights = weights + alpha * error * dataMatrix[i]
return weights
测试:
dataArraryay,labelMat=loadDataSet() result=stocGradAscent0(dataArraryay,labelMat) plotBestFit(result)
输出:
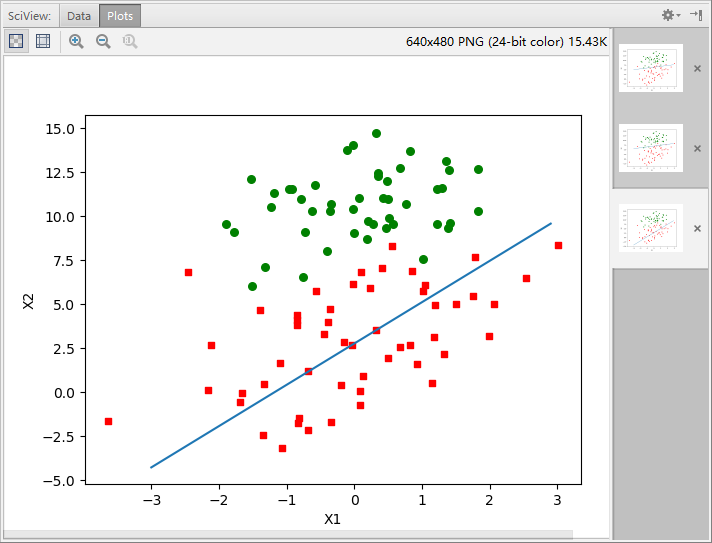
分类器错分了三分之一的样本。
改进的随机梯度上升算法:每次随机选取一个样本,然后剔除此样本,下次选择剩余的样本用来更新回归系数,这样选择一轮样本过程中会选择到所有的样本,然后重复以上过程,并且设置重复的次数。
def stocGradAscent1(dataMatrix, classLabels, numInter = 150): #改进的随机梯度上升算法
dataMatrix = array(dataMatrix)
m,n = shape(dataMatrix)
weights = ones(n)
for j in range(numInter): #默认150次迭代
dataIndex = list(range(m))
for i in range(m): #100次循环
alpha = 4 / (1.0+j+i) + 0.01 #alpha值每次迭代时需要调整
randIndex = int(random.uniform(0, len(dataIndex))) #随机选取更新
h = sigmoid(sum(dataMatrix[randIndex] * weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del dataIndex[randIndex]
return weights
测试:
dataArraryay,labelMat=loadDataSet() result=stocGradAscent1(dataArraryay,labelMat,1000) #迭代1000次 plotBestFit(result)
输出:

分类正确率很高。
3、应用:从疝气病症预测病马的死亡率
3.1、准备数据:处理数据中的缺失值有以下常用方法
使用可用特征的平均值来填补缺失值;
使用特殊值,如-1;
忽略有缺失值的样本;
使用相似样本的均值填补缺失值;
使用另外的机器学习算法预测缺失值。
本例中,在初始数据的预处理阶段需要做两件事情:第一,所有的缺失值用0填充,这样做在更新回归系数的过程中缺失值不会影响对应回归系数的值,而且它对结果的预测不具有任何倾向性,不会对误差项造成影响。第二,如果数据的标签项丢失则将该条数据丢弃。
3.2、用Logistic回归进行分类
def classifyVector(inX, weights): #示例:从疝气病症预测病马的死亡率,输入:数据特征值,最佳回归系数
prob = sigmoid(sum(inX * weights))
if prob > 0.5:
return 1.0
else:
return 0.0
def colicTest():
frTrain = open('horseColicTraining.txt')
frTest = open('horseColicTest.txt')
trainingSet = []
trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split(' ')
lineArr = []
for i in range(21): #数据集每条数据有21个特征
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stocGradAscent1(trainingSet, trainingLabels, 500) #改变500,可以改变分类错误率
errorCount = 0
numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0 #用于测试的数据总数
currLine = line.strip().split(' ')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights)) != int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount) / numTestVec)
print('分类错误率: %f' % errorRate)
return errorRate
def multiTest():
numTests = 10 #重复十次求平均值
errorSum = 0.0
for k in range(numTests):
errorSum += colicTest()
print('%d 次重复迭代后平均错误率为: %f' % (numTests, errorSum / float(numTests)))
测试:
multiTest()
输出:
分类错误率: 0.328358 分类错误率: 0.417910 分类错误率: 0.298507 分类错误率: 0.238806 分类错误率: 0.253731 分类错误率: 0.417910 分类错误率: 0.388060 分类错误率: 0.283582 分类错误率: 0.313433 分类错误率: 0.313433 10 次重复迭代后平均错误率为: 0.325373
分类的平均错误率为:32.5%,调整colicTest()中的迭代次数和stocGradAscent1()中的步长,可以降低平均错误率。
完整代码:


from numpy import * def loadDataSet(): dataMat=[] labelMat=[] f=open('testSet.txt') for line in f.readlines(): lineArrary=line.strip().split() dataMat.append([1.0,float(lineArrary[0]),float(lineArrary[1])]) labelMat.append(int(lineArrary[2])) return dataMat,labelMat def sigmoid(inx): # return longfloat(1.0/(1+exp(-inx))) if inx>=0: #对sigmoid函数的优化,避免了出现极大的数据溢出 return 1.0/(1+exp(-inx)) else: return exp(inx)/(1+exp(inx)) def gradAscent(dataMatIn,classLabels): dataMatrix = mat(dataMatIn) # 转换为numpy矩阵数据类型 100*3 labelMat = mat(classLabels).transpose() #转置 100*1 m,n=shape(dataMatrix) alpha = 0.001 maxCycles = 500 weights = ones((n, 1)) #回归系数初始化为1,3*1 for k in range(maxCycles): h = sigmoid(dataMatrix * weights) #100*3 3*1 h:100*1 error = (labelMat - h) #100*1 weights = weights + alpha * dataMatrix.transpose() * error #最大似然估计 3*100 100*1 =>3*1 return weights # dataArraryay,labelMat=loadDataSet() # result=gradAscent(dataArraryay,labelMat) # print(result) def plotBestFit(weights): import matplotlib.pyplot as plt dataMat, labelMat = loadDataSet() #矩阵 dataArrary = array(dataMat) #数组 100*3 n = shape(dataArrary)[0] #100,对应100个训练数据 xcord1 = [] ycord1 = [] xcord2 = [] ycord2 = [] for i in range(n): if int(labelMat[i]) == 1: #如果此条训练数据是1类 xcord1.append(dataArrary[i, 1]) #dataArrary[i, 1]为第二列数据,作为作图的横坐标 ycord1.append(dataArrary[i, 2]) #纵坐标 else: #0类 xcord2.append(dataArrary[i, 1]) #横坐标 ycord2.append(dataArrary[i, 2]) #纵坐标 fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(xcord1, ycord1, s=20, c='red',marker='s') #s表示大小,c表示颜色,marker表示形状,默认是圆,marker='s'表示方形 ax.scatter(xcord2, ycord2, s=30, c='green') x = arange(-3.0, 3.0, 0.1) y = (-weights[0] - weights[1] * x) / weights[2] # sigmoid函数中,x=0是分解条件,对应y=0.5,所以映射到特征值就应该是:w0*x0+w1*x1+w2*x2=0,其中x0=1,x1代表的是横坐标,x2代表的是纵坐标 #解得:x2=-(w0+w1*x1)/w2 ----> y=-(w0+w1*x)/w2 即为决策边界 ax.plot(x, y) plt.xlabel('X1') plt.ylabel('X2') plt.show() def stocGradAscent0(dataMatrix, classLabels): #随机梯度上升算法,没有使用矩阵,所有变量的数据类型都是数组 dataMatrix = array(dataMatrix) m,n = shape(dataMatrix) alpha = 0.01 weights = ones(n) for i in range(m): h = sigmoid(sum(dataMatrix[i] * weights)) #dataMatrix[i]和weights都是1*3的数组,执行的是对应元素相乘 error = classLabels[i] - h #h,error都是数值 weights = weights + alpha * error * dataMatrix[i] return weights def stocGradAscent1(dataMatrix, classLabels, numInter = 150): #改进的随机梯度上升算法 dataMatrix = array(dataMatrix) m,n = shape(dataMatrix) weights = ones(n) for j in range(numInter): #150次遍历 dataIndex = list(range(m)) for i in range(m): #100次循环 alpha = 4 / (1.0+j+i) + 0.01 #alpha值每次迭代时需要调整 randIndex = int(random.uniform(0, len(dataIndex))) #随机选取更新 h = sigmoid(sum(dataMatrix[randIndex] * weights)) error = classLabels[randIndex] - h weights = weights + alpha * error * dataMatrix[randIndex] del dataIndex[randIndex] return weights def classifyVector(inX, weights): #示例:从疝气病症预测病马的死亡率,输入:数据特征值,最佳回归系数 prob = sigmoid(sum(inX * weights)) if prob > 0.5: return 1.0 else: return 0.0 def colicTest(): frTrain = open('horseColicTraining.txt') frTest = open('horseColicTest.txt') trainingSet = [] trainingLabels = [] for line in frTrain.readlines(): currLine = line.strip().split(' ') lineArr = [] for i in range(21): #数据集每条数据有21个特征 lineArr.append(float(currLine[i])) trainingSet.append(lineArr) trainingLabels.append(float(currLine[21])) trainWeights = stocGradAscent1(trainingSet, trainingLabels, 500) errorCount = 0 numTestVec = 0.0 for line in frTest.readlines(): numTestVec += 1.0 #用于测试的数据总数 currLine = line.strip().split(' ') lineArr = [] for i in range(21): lineArr.append(float(currLine[i])) if int(classifyVector(array(lineArr), trainWeights)) != int(currLine[21]): errorCount += 1 errorRate = (float(errorCount) / numTestVec) print('分类错误率: %f' % errorRate) return errorRate def multiTest(): numTests = 10 #重复十次求平均值 errorSum = 0.0 for k in range(numTests): errorSum += colicTest() print('%d 次重复迭代后平均错误率为: %f' % (numTests, errorSum / float(numTests))) # dataArraryay,labelMat=loadDataSet() # result=stocGradAscent1(dataArraryay,labelMat,1000) multiTest()