1.下载一中文长篇小说,并转换成UTF-8编码。
2.使用jieba库,进行中文词频统计,输出TOP20的词及出现次数。
3.排除一些无意义词、合并同一词。
4.对词频统计结果做简单的解读。
import jieba
content=open(r'C:UsersAdministratorAppDataLocalProgramsPythonPython36挪威的森林.txt','r',encoding='utf-8')
forest=content.read()
content.close()
words=list(jieba.cut(forest))
s=set(words)
dic={}
for i in s:
if(i==" "):
continue
if(i==""):
continue
if len(i)==1:
continue
else:
dic[i]=words.count(i)
lis=list(dic.items())
lis.sort(key=lambda x:x[1],reverse=True)
for i in range(20):
print(lis[i])
运行结果为:
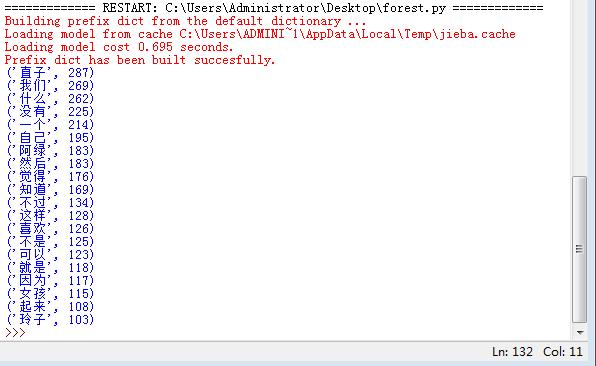
解读:通过对《挪威的森林》的词频统计,因为“喜欢”,“我们”,“女孩”,“自己”诸如此类词语的高频出现,我们可以隐约知道这部小说应该主要讨论关于爱情的故事。