先贴出导出方法:
@SuppressWarnings("unused")
public static <T> SXSSFWorkbook export1(HttpServletResponse response, String fileName, String[] excelHeader,
List<T> dataList) throws Exception {
response.setContentType("application/x-download");
response.setCharacterEncoding("utf-8");// 处理编码问题
response.setHeader("Content-Disposition",
"attachment;filename=" + new String(fileName.getBytes("gbk"), "iso8859-1") + ".xls");// 表头编码问题
XSSFWorkbook wb = new XSSFWorkbook();
SXSSFWorkbook sxssfWorkbook = new SXSSFWorkbook(wb, 100);
SXSSFSheet sheet = sxssfWorkbook.createSheet();
// Sheet sheet = sxssfWorkbook.getSheetAt(0);
// 标题数组
String[] titleArray = new String[excelHeader.length];
// 字段名数组
String[] fieldArray = new String[excelHeader.length];
for (int i = 0; i < excelHeader.length; i++) {
String[] tempArray = excelHeader[i].split("#");
titleArray[i] = tempArray[0];
fieldArray[i] = tempArray[1];
}
// 在sheet中添加标题行
sheet.trackAllColumnsForAutoSizing();
Row row = sheet.createRow(0);// 行数从0开始
// 自动设置宽度
sheet.autoSizeColumn(0);
// 设置表格默认列宽度
sheet.setDefaultColumnWidth(20);
// 为标题行赋值
for (int i = 0; i < titleArray.length; i++) {
// 需要序号就需要+1 因为0号位被序号占用
Cell titleCell = row.createCell(i);
titleCell.setCellValue(titleArray[i]);
sheet.autoSizeColumn(i + 1); // 0 号被序号占用
}
Map<String, Method> map = new HashMap<String, Method>();
for (int index = 1; index < dataList.size(); index++) {
row = sheet.createRow(index);
// 利用反射 根据传过来的字段名数组,动态调用对应的getxxx()方法得到属性值
long start = System.currentTimeMillis();
for (int i = 0; i < fieldArray.length; i++) {
// 需要序号 就需要 i+1
Cell dataCell = row.createCell(i);
String fieldName = fieldArray[i];
// 取得对应的getxxx()方法 实体类命名一定要用驼峰才能分割成功
String getMethodName = "get" + fieldName.substring(0, 1).toUpperCase() + fieldName.substring(1);
Method getMethod = map.get(getMethodName);
if(getMethod == null){
// Class<? extends Object> tCls = t.getClass();// 泛型为Object以及所有Object的子类
getMethod = dataList.get(index).getClass().getMethod(getMethodName);// 通过方法名得到对应的方法
getMethod.setAccessible(true);
map.put(getMethodName, getMethod);
}
Object value = getMethod.invoke(dataList.get(index));// 动态调用方法,得到属性值
if (value != null) {
dataCell.setCellValue(value.toString());// 为当前列赋值
}
}
long end = System.currentTimeMillis();
System.out.println("循环花费的时间:"+(end-start)+" milliseconds");
}
OutputStream outputStream = response.getOutputStream();// 打开流
sxssfWorkbook.write(outputStream);// HSSFWorkbook写入流
sxssfWorkbook.close();// HSSFWorkbook关闭
outputStream.flush();// 刷新流
outputStream.close();// 关闭流
return sxssfWorkbook;
}
这里的是自定义字段导出的,其中excelHeader是通过#分割的,例如“用户名#username”的数组。
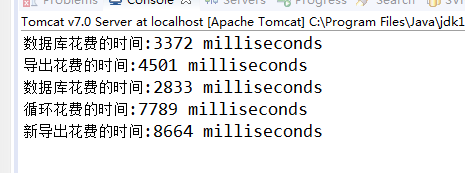
上面两条数据是十万条数据调用网上大神封装的方法,导出只需要4.5秒;
而我的才2万条数据却需要8.6秒;
不是一个量级的,所以我在想,哪里还可以再优化。
这里反射最好使用缓存,我已使用map来代替缓存了;重点也在反射的循环中,需要花费7.8秒的时间;
public static <T> SXSSFWorkbook export2(HttpServletResponse response, String fileName, String[] excelHeader, List<T> dataList) throws Exception { response.setContentType("application/x-download"); response.setCharacterEncoding("utf-8");// 处理编码问题 response.setHeader("Content-Disposition", "attachment;filename=" + new String(fileName.getBytes("gbk"), "iso8859-1") + ".xls");// 表头编码问题 XSSFWorkbook wb = new XSSFWorkbook(); SXSSFWorkbook sxssfWorkbook = new SXSSFWorkbook(wb, 100); SXSSFSheet sheet = sxssfWorkbook.createSheet(); // Sheet sheet = sxssfWorkbook.getSheetAt(0); // 标题数组 String[] titleArray = new String[excelHeader.length]; // 字段名数组 String[] fieldArray = new String[excelHeader.length]; for (int i = 0; i < excelHeader.length; i++) { String[] tempArray = excelHeader[i].split("#"); titleArray[i] = tempArray[0]; fieldArray[i] = tempArray[1]; } // 在sheet中添加标题行 sheet.trackAllColumnsForAutoSizing(); Row row = sheet.createRow(0);// 行数从0开始 // 自动设置宽度 sheet.autoSizeColumn(0); // 设置表格默认列宽度 sheet.setDefaultColumnWidth(20); // 为标题行赋值 for (int i = 0; i < titleArray.length; i++) { // 需要序号就需要+1 因为0号位被序号占用 Cell titleCell = row.createCell(i); titleCell.setCellValue(titleArray[i]); sheet.autoSizeColumn(i + 1); // 0 号被序号占用 } Map<String, Method> map = new HashMap<String, Method>(); long start = System.currentTimeMillis(); MethodAccess ma = MethodAccess.get(MemberInfo.class); for (int index = 0; index < dataList.size(); index++) { row = sheet.createRow(index); // 利用反射 根据传过来的字段名数组,动态调用对应的getxxx()方法得到属性值 for (int i = 0; i < fieldArray.length; i++) { // 需要序号 就需要 i+1 // String fieldName = fieldArray[i]; // 取得对应的getxxx()方法 实体类命名一定要用驼峰才能分割成功 String getMethodName = "get" + fieldArray[i].substring(0, 1).toUpperCase() + fieldArray[i].substring(1); // int index1 = ma.getIndex(getMethodName); // Method getMethod = map.get(getMethodName); // MethodAccess ma = MethodAccess.get(GenericsUtils.getSuperClassGenricType(dataList.get(index).getClass())); /*if(getMethod == null){ getMethod = dataList.get(index).getClass().getMethod(getMethodName);// 通过方法名得到对应的方法 map.put(getMethodName, getMethod); }*/ Object value = ma.invoke(dataList.get(index), getMethodName); if (value != null) { row.createCell(i).setCellValue(value.toString());// 为当前列赋值 } } } long end = System.currentTimeMillis(); System.out.println("循环花费的时间:"+(end-start)+" milliseconds"); OutputStream outputStream = response.getOutputStream();// 打开流 sxssfWorkbook.write(outputStream);// HSSFWorkbook写入流 sxssfWorkbook.close();// HSSFWorkbook关闭 outputStream.flush();// 刷新流 outputStream.close();// 关闭流 return sxssfWorkbook; }

这是导出5万多数据,查询需要6.6秒,新引用ReflectASM结果需要23.5秒导入,而之前缓存的反射却只需要21.3秒。
实际上ReflectASM就是把类的各个方法缓存起来,然后通过case选择,直接调用,
也许我的map比ReflectASM速度更快?