如何使用

概述
- ConcurrentHashMap:
线程安全;
其将整个Hash桶进行了分段segment,也就是将这个大的数组分成了几个小的片段segment,而且每个小的片段segment上面都有锁存在,那么在插入元素的时候就要先找到应该插入到哪一个片段segment,然后再在这个片段上面进行插入,而且这里还需要获取segment锁(即锁分段技术);
ConcurrentHashMap让锁的粒度更精细一些,并发性能更好; -
SynchronizedMap:
线程安全;
通过synchronized关键字进行同步控制;
所有单个的操作都是线程安全的,但是多个操作组成的操作序列却可能导致数据争用,因为在操作序列中控制流取决于前面操作的结果。这也被称作是:有条件的线程安全性;
效率低;
两者源码对比
哈希表声明:通过下面两图对比可以发现,两者的区别在于volatile关键字
- ConcurrentHashMap:

- SynchronizedMap:

put()方法:
- ConcurrentHashMap:
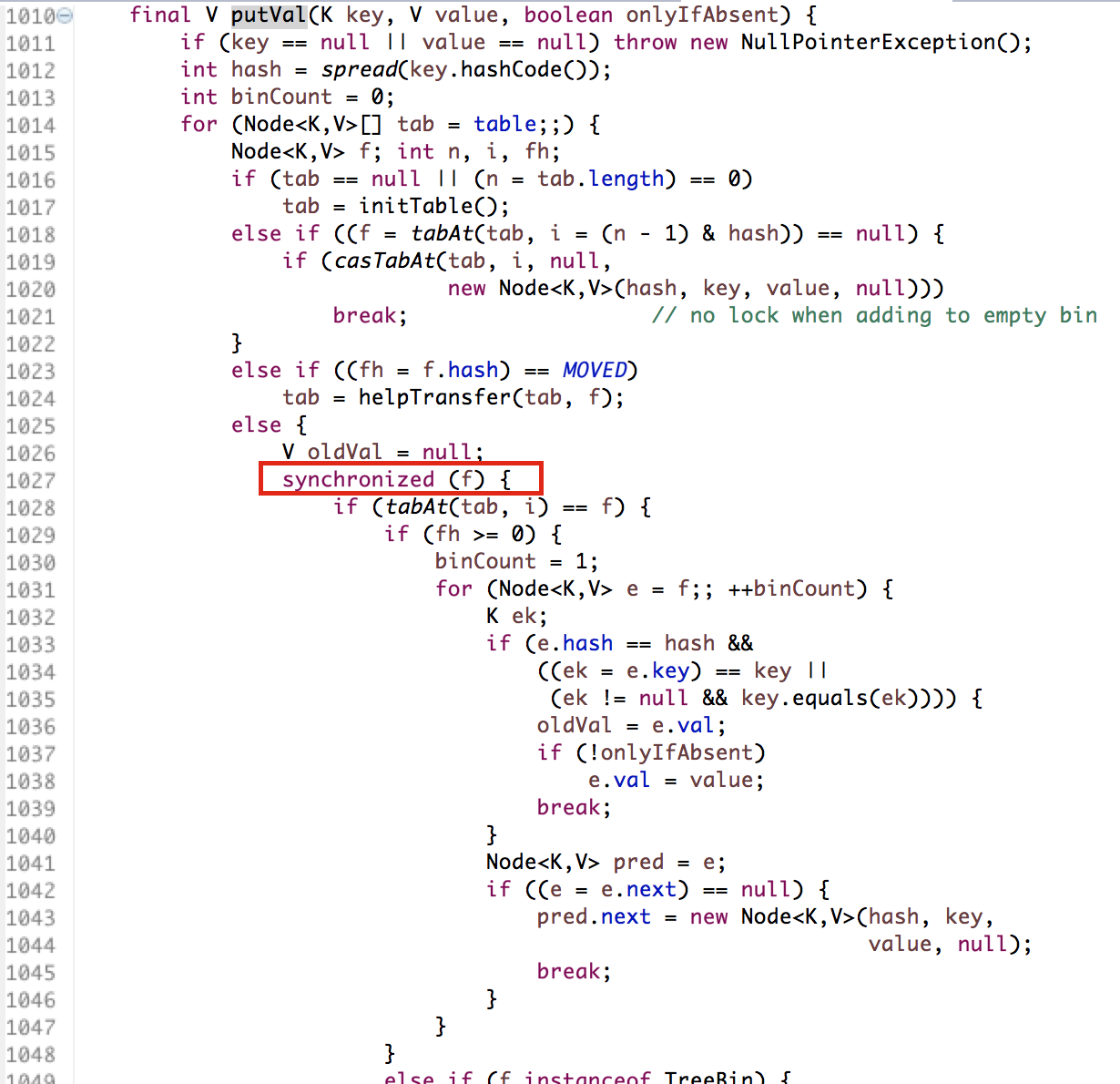
- SynchronizedMap:
![]() get()方法:
get()方法:
- ConcurrentHashMap:

- SynchronizedMap:
![]()
ConcurrentHashMap详解
- 与HashTable容器对比:HashTable容器在竞争激烈的并发环境下表现出效率底下的原因是所有访问HashTable的线程都必须竞争同一把锁(其实现是在对应的方法上添加了synchronized关键字进行修饰),那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
- get()方法:其高效之处在于整个get过程不需要加锁,除非读到的值是空的才会加锁重读。get方法里将要使用的共享变量都定义成volatile,如用于统计当前Segement大小的count字段和用于存储值的HashEntry的value。定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被线程写,就是写入的值不依赖于原值),在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。
- put()方法:首先定位到Segment,然后在Segment里进行插入操作。插入操作需要经历两个步骤,第一步判断是否需要对Segment里的HashEntry数组进行扩容,第二步定位添加元素的位置然后放在HashEntry数组里。
- 具体实现:在ConcurrentHashMap的实现中使用了一个包含16个锁的数组,每个锁保护所有散列桶的1/16,其中第N个散列桶由第(N mod 16)个锁来保护。假设散列函数具有合理的分布性,并且关键字能够实现均匀分布,那么这大约能把对于锁的请求减少到原来的1/16。正是这项技术使得其能够支持多达16个并发的写入器。
- 缺点:当ConcurrentHashMap需要扩展映射范围,以及重新计算键值得散列值要分布到更大的桶集合中时,就需要获取分段锁集合中所有的锁(要获取内置锁的一个集合,采用的唯一方式是递归)。