Map对应python中的字典 存储键值对
1: Map与Collection并列存在。用于保存具有映射关系的数据:key-value 2: Map 中的 key 和 value 都可以是任何引用类型的数据 3: Map 中的 key 用Set来存放,不允许重复,即同一个 Map 对象所对应 的类,须重写hashCode()和equals()方法 4: 常用String类作为Map的“键” 5: key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到 唯一的、确定的 value 6: Map接口的常用实现类:HashMap、TreeMap、LinkedHashMap和 Properties。其中,HashMap是 Map 接口使用频率最高的实现类
HashMap:
HashMap是 Map 接口使用频率最高的实现类。 允许使用null键和null值,与HashSet一样,不保证映射的顺序。 所有的key构成的集合是Set:无序的、不可重复的。所以,key所在的类要重写: equals()和hashCode() 所有的value构成的集合是Collection:无序的、可以重复的。所以,value所在的类 要重写:equals() 一个key-value构成一个entry 所有的entry构成的集合是Set:无序的、不可重复的 HashMap 判断两个 key 相等的标准是:两个 key 通过 equals() 方法返回 true, hashCode 值也相等。 HashMap 判断两个 value相等的标准是:两个 value 通过 equals() 方法返回 true
* |---- Map 双列数据,存储key--value * |---- HashMap: 作为Map的主要实现类 * |---- LinkedHashMap:保证在遍历map元素时,可以按照添加顺序实现遍历。 * 原因: 在原有的HaspMap底层结构基础上,添加一对指针,分别指向前一个后一个元素 * 对于频繁遍历的元素操作,此类执行效率高于HaspMap * |---- TreeMap: 可以按照添加的key--value来进行排序,实现排序(此时考虑key来排序) * |---- Hashtable: 古老的实现类,线程安全的效率低 不能存储null的key和value * * * HashMap的底层:数组+链表(jdk7之前) * 数据+链表+红黑树(jdk8)
HashMap的底层实现原理:
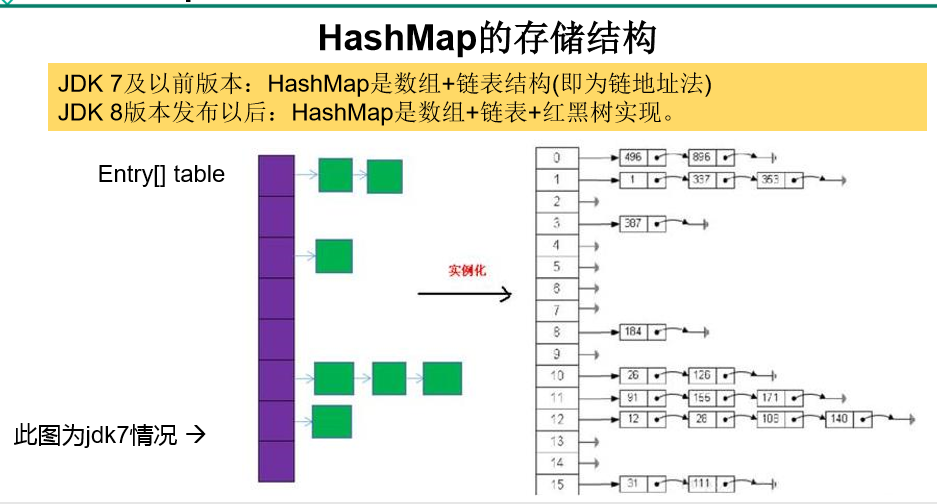
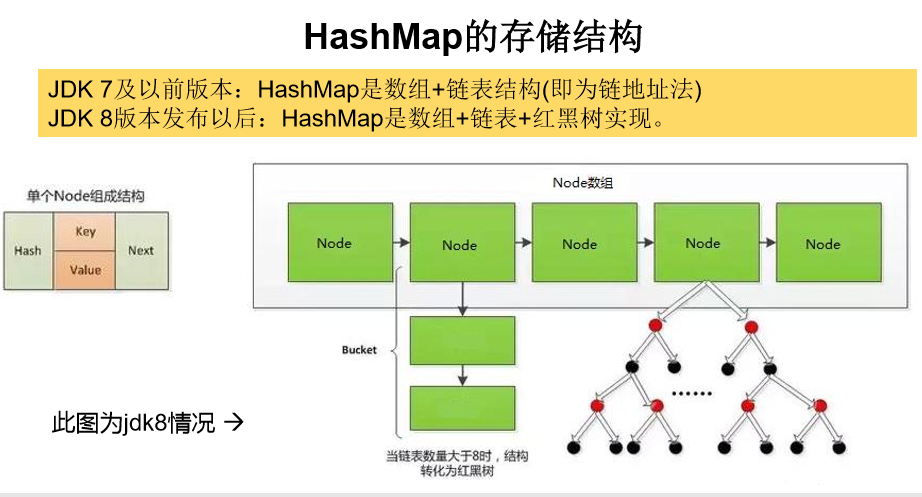
* Jdk7 : * HashMap hashMap = new HashMap(); * 在实例化之后 底层创建了长度为16的一维数组 Entry [] table(因为key和value组成了以一个entry的对象) * ....可能执行了多次put... * map.put(key1,value1); * 首先调用key1所在类的hashcode()计算key1的哈希值,此哈希值经过某种算法计算以后,得到在Entry数组存放的位置 * 如果此位置上的数据为空,那么key1--value1添加成功 ------情况1 * 如果此位置上的数据不为空(意味着此位置上存在一个或者多个以链表形式存在的数据),那么比较key1和已经存在的一个或多个数据的哈希: * 如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1--value1添加成功 ----- 情况2 * 如果key1的哈希值和已经存在的某一个数据(key2---value2)的哈希值相同,继续比较 调用key1所在类的equals(key2) * 进行比较: * 如果equals()返回false:此时key1--value1添加成功 ------》情况3 * 如果equals()返回true:此时就是替换了 将value1替换相同key的value值(key相同 ,而值不同的替换行为) * * * 关于情况2 和情况3:此时key1---value1和原来数据的存储方式是以链表的形式存储 * * 在不断添加内容的过程中是,会涉及到扩容的问题,默认的扩容方式 扩容为原来容量的二倍 并且将原来的数据复制到扩容后的容量中 * * * Jdk8与Jdk7不同的点: * 1: new HashMap()的时候不会创建一个长度为16的数组 * * 2: Jdk8底层的数组是:Node[]而不是Entry[] * * 3: 首次调用put()时,方才创建底层长度为16的数组 * * 4: jdk7的底层结构只有:数组+链表,jdk8底层结构:数组+链表+红黑树 * 当一个数组的某一个索引位置上的元素以链表形式存在的个数 > 8且数组的长度 > 64时, * 此时索引位置上的所有元素改为红黑树存储 * * 为何要用红黑树? * 比如二叉树存储,时有序的 例如小的全部方左边或者右边 那么依次这样排放,查找也方便 * * * * * * HashMap和Hashtable的异同 * * * * Map结构的理解 * * Map中的key是无序的,不可重复的,使用Set存储所有的key --- 如果key是自定义的类,key所在的类要重写hashcode()和equals()方法 * Map中的value是无序的,不可重复的,使用Collection存储所有的value ---- value所在的类重写equals() * 一个键值对key--value构成一个Entry对象 * Map中的Entry对象无序的,不可重复的,使用Set存储所有的entry对象 *
Jdk7:
Jdk8:
Map接口的常用方法
添加、删除、修改操作: Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中 void putAll(Map m):将m中的所有key-value对存放到当前map中 Object remove(Object key):移除指定key的key-value对,并返回value void clear():清空当前map中的所有数据 元素查询的操作: Object get(Object key):获取指定key对应的value boolean containsKey(Object key):是否包含指定的key boolean containsValue(Object value):是否包含指定的value int size():返回map中key-value对的个数 boolean isEmpty():判断当前map是否为空 boolean equals(Object obj):判断当前map和参数对象obj是否相等 元视图操作的方法: Set keySet():返回所有key构成的Set集合 Collection values():返回所有value构成的Collection集合 Set entrySet():返回所有key-value对构成的Set集合
put(key, value)添加元素或者修改元素
HashMap hashMap = new HashMap(); hashMap.put(1,23); hashMap.put(2,"老张"); hashMap.put(3,"老刘");
修改;当key存在时在添加相同的key的键值对就是修改value
hashMap.put(3,"老刘");
hashMap.put(3,"您好"); // 修改操作
keySet(); 获取Map中所有的key构成的Set集合
Set set= hashMap.keySet(); // 获取所有key的set集合 Iterator iterator = set.iterator(); // 转化成迭代器取值 while (iterator.hasNext()){ System.out.println(iterator.next()); }
values(); 获取Map中所有的value构成的Collection集合
Collection collection = hashMap.values(); // 获取所有的value构成的Collection Iterator iteratorOne = collection.iterator(); while (iteratorOne.hasNext()){ System.out.println(iteratorOne.next()); }
entrySet(); 获取map中的所有的键值对构成的Set集合
Set setOne = hashMap.entrySet(); Iterator iteratorTwo = setOne.iterator(); while (iteratorTwo.hasNext()){ System.out.println(iteratorTwo.next()); //2=老张 //3=您好 }
Set setOne = hashMap.entrySet();
Iterator iteratorTwo = setOne.iterator();
while (iteratorTwo.hasNext()){
Object obj = iteratorTwo.next();
// EntrySet集合中的元素都是entry
Map.Entry entry = (Map.Entry)obj;
System.out.println(entry.getKey()+"---->"+entry.getValue()); // 取出entry的key和value
}
HashMap hashMap = new HashMap(); HashMap hashMapOne = new HashMap(); hashMap.put(1,"老王"); hashMap.put(2,"老张"); hashMapOne.put(4,"隔壁小姐姐"); hashMapOne.put(6,"老张在隔壁"); System.out.println(hashMap.containsKey(1)); System.out.println(hashMap.get(2)); hashMap.remove(1); hashMap.putAll(hashMapOne); // 另一个hashMapOne集合添加到此hashMap集合 System.out.println(hashMapOne.isEmpty()); // 判断是否为空 hashMapOne.clear(); System.out.println(hashMap.size()); Set set = hashMap.keySet(); // 获取所有的key Collection list = hashMap.values(); // 获取所有的values Set setOne = hashMap.entrySet(); // 获取所有的entry