首页
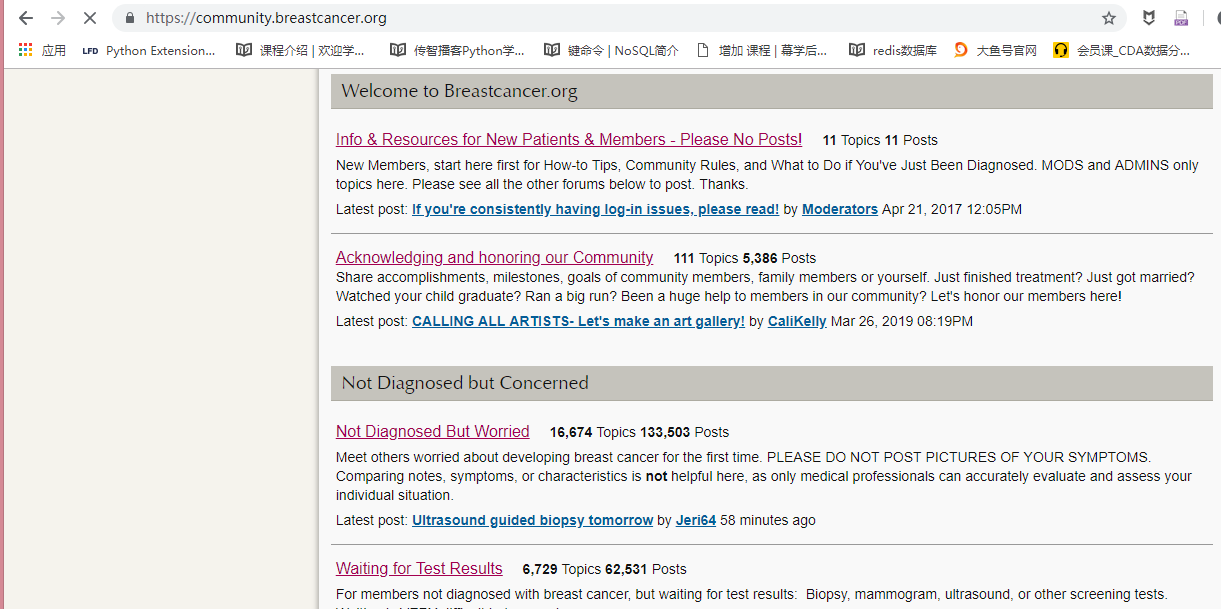
某个社区
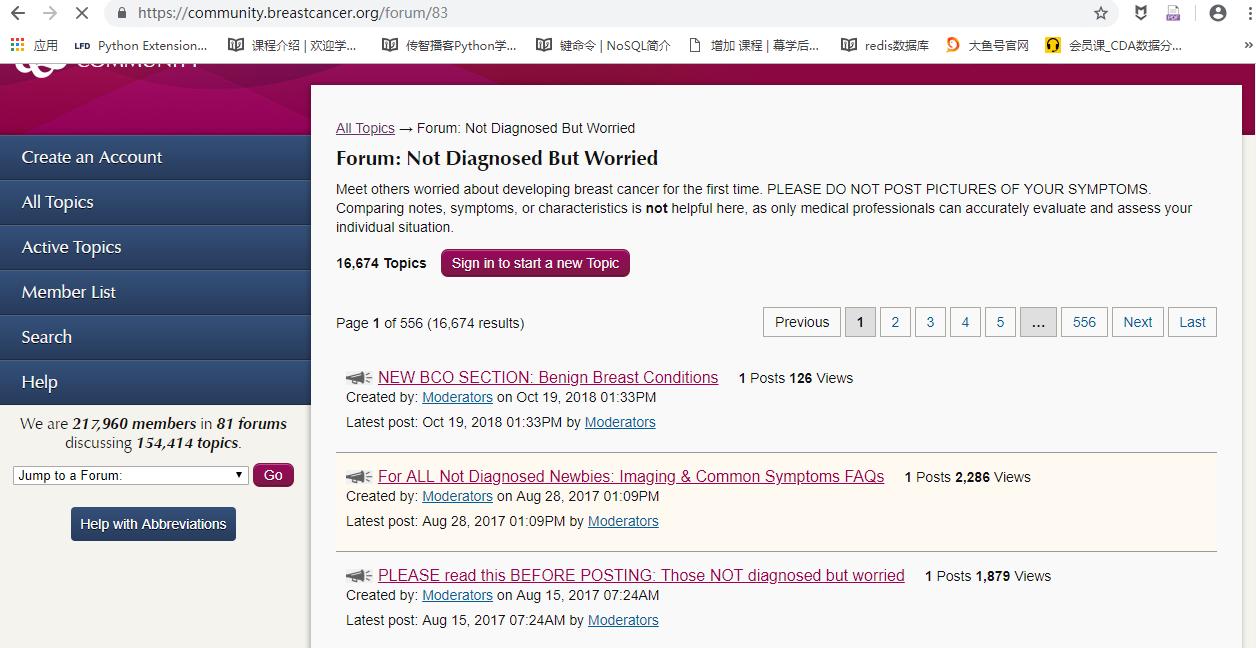
某社区的一个话题
目标:获取这个网站所有话题的所有评论相关信息
python实现
# -*- coding: utf-8 -*-
"""
@Datetime: 2019/3/17
@Author: Zhang Yafei
"""
import functools
import os
import re
import traceback
import time
from concurrent.futures import ThreadPoolExecutor, wait, as_completed, ProcessPoolExecutor
from itertools import chain
from urllib.request import urljoin
import pandas as pd
from lxml import etree
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 控制台输出所有列
pd.set_option('display.max_columns', None)
forum_info = pd.read_csv('all_forum_info.csv')
def timeit(fun):
@functools.wraps(fun)
def wrapper(*args, **kwargs):
start_time = time.time()
res = fun(*args, **kwargs)
print('运行时间为%.6f' % (time.time() - start_time))
return res
return wrapper
class Download(object):
""" 请求的下载 """
def __init__(self, url):
self.url = url
self.forum_topic = '【{}】'.format(forum_info[forum_info.forum_url == url[0]].forum_topic.values[0])
self.dir_path = os.path.join('download', self.forum_topic).replace('/', '-').replace(',', '').replace(':', '-').replace('"', '')
if not os.path.exists(self.dir_path):
os.mkdir(self.dir_path)
self.chrome_options = Options()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
self.browser = None
self.dispatch(pool=True)
def dispatch(self, pool=True):
""" 下载所有社区页面 """
topic_count = int(self.url[1].replace(',', ''))
pages = divmod(topic_count, 30)[0] + 1
remain_pages = self.filter_url(pages)
urls = [self.url[0] + '?page={}'.format(page) for page in remain_pages]
# [self.forum_start(urls), list(map(self.forum_start, self.url))][len(self.url) > 1
if urls and pool:
pool = ThreadPoolExecutor(max_workers=4)
pool.map(self.forum_start, urls, timeout=60)
pool.shutdown()
elif urls:
list(map(self.forum_start, urls))
else:
print(self.dir_path + '共需下载{}页'.format(pages) + ' 下载完成')
def filter_url(self, pages):
has_pages = list(map(lambda x: int(x.strip('.html')), os.listdir(self.dir_path)))
down_pages = list(set(range(1, pages + 1)) - set(has_pages))
if len(down_pages):
print(self.dir_path + '共需下载:{}页'.format(pages) + ' 已下载:{}页'.format(len(has_pages)) + ' 未下载:{}页'.format(len(down_pages)))
return down_pages
def forum_start(self, url, header=False):
if header:
browser = webdriver.Chrome()
else:
browser = webdriver.Chrome(chrome_options=self.chrome_options)
browser.get(url=url)
html = browser.page_source
browser.close()
file_path = os.path.join(self.dir_path, url.split('?page=')[-1] + '.html')
with open(file_path, mode='w', encoding='utf-8') as f:
f.write(html)
print(url + '下载成功')
# def close(self):
# self.browser.close()
class BreastCancer(object):
""" BreastCancer社区评论下载 """
def __init__(self):
self.base_url = 'https://community.breastcancer.org/'
self.all_forum_columns = ['hgroup', 'forum_topic', 'forum_url', 'count_topic', 'count_post']
self.all_forum_file = 'all_forum_info.csv'
self.all_topic_columns = ['forum', 'topic_url', 'founder', 'count_posts', 'count_views', 'created_time', 'file_path']
self.all_topic_file = 'all_topic_info.csv'
if not os.path.exists(self.all_topic_file):
self.write_to_file(columns=self.all_topic_columns, file=self.all_topic_file, mode='w')
def download_forums_index(self):
"""
下载社区首页
"""
browser = webdriver.Chrome()
browser.get(url=self.base_url)
html = browser.page_source
with open('download/community.html', mode='w', encoding='utf-8') as f:
f.write(html)
browser.close()
def parse_forums_index(self):
""" 解析社区首页 获取所有社区页面id """
# 创建csv文件, 写入表头
if not os.path.exists(self.all_forum_file):
data = pd.DataFrame(columns=self.all_forum_columns)
data.to_csv(self.all_forum_file, index=False)
# 读取html文件,提取有用信息,写入到文件尾部
with open('download/community.html', encoding='utf-8') as f:
response = f.read()
response = etree.HTML(response)
rowgroups = response.xpath('//div[@class="rowgroup"]')
list(map(self.get_all_forums_ids, rowgroups))
def get_all_forums_ids(self, response):
"""
获取所有:
hgroup、
forum_topic(社区主题)、
url(社区页面地址)、
count_topic(话题数量)、
count_post(评论数量)
"""
hgroup = response.xpath('.//h2/text()')[0]
forums = response.xpath('.//li')
data_list = []
for forum in forums:
forum_topic = forum.xpath('h3/a/text()')[0]
forum_url = urljoin('https://community.breastcancer.org/', forum.xpath('h3/a/@href')[0])
count_topic = forum.xpath('.//span[@class="count_topic"]/strong/text()')[0]
count_post = forum.xpath('.//span[@class="count_post"]/strong/text()')[0]
data_dict = {'hgroup': hgroup, 'forum_topic': forum_topic, 'forum_url': forum_url,
'count_topic': count_topic,
'count_post': count_post}
data_list.append(data_dict)
df = pd.DataFrame(data=data_list)
# 固定输出列的顺序
df = df.loc[:, self.all_forum_columns]
df.to_csv(self.all_forum_file, index=False, header=False, mode='a')
print(hgroup + '数据解析完成')
def get_all_forum_page(self, pool=True):
""" 获取所有社区url 并下载所有社区相关页面 """
df = pd.read_csv(self.all_forum_file)
forum_urls = df.apply(lambda x: (x.forum_url, x.count_topic), axis=1)
if pool:
# 多线程下载
# BreastCancer.thread_pool_download(forum_urls)
# 多进程
BreastCancer.process_pool_download(forum_urls)
else:
# 单线程下载
list(map(Download, forum_urls))
@staticmethod
def thread_pool_download(urls):
""" 多线程下载 """
pool = ThreadPoolExecutor(max_workers=4)
tasks = [pool.submit(Download, url) for url in urls]
wait(tasks)
# pool.map(Download, urls)
pool.shutdown()
@staticmethod
def process_pool_download(urls):
""" 多进程下载 """
pool = ProcessPoolExecutor(max_workers=4)
pool.map(Download, urls)
pool.shutdown()
def get_topic_info(self, response):
""" 获取所有话题相关信息 """
topic_url = urljoin(self.base_url, response.xpath('./h3/a/@href')[0])
count_posts = response.xpath('./p[1]/span[1]/strong/text()')[0]
count_views = response.xpath('./p[1]/span[2]/strong/text()')[0]
founder = response.xpath('./p[2]/a/text()')[0]
created = response.xpath('./p[2]')[0].xpath('string(.)').replace('
', '').replace(' ', '')
created_time = re.search('on(.*)', created).group(1)
data_dict = {'topic_url': topic_url, 'founder': founder,
'count_posts': count_posts, 'count_views': count_views,
'created_time': created_time
}
return data_dict
@staticmethod
def get_file_path_list(row):
forum_topic = '【{}】'.format(row.forum_topic)
dir_path = os.path.join('download', forum_topic).replace('/', '-').replace(',', '').replace(':', '-').replace(
'"', '')
file_path_list = list(map(lambda file: os.path.join(dir_path, file), os.listdir(dir_path)))
return file_path_list
@timeit
def start_parse_forum_page(self, pool=False):
""" 开始解析社区页面 """
file_path_lists = forum_info.apply(BreastCancer.get_file_path_list, axis=1).tolist()
file_path_lists = functools.reduce(lambda x, y: x + y, file_path_lists)
# 每次解析前过滤已解析的页面
file_path_lists = self.filter_file_path(file_path_lists)
if pool:
pool = ThreadPoolExecutor(max_workers=4)
pool.map(self.parse_forum_page, file_path_lists)
pool.shutdown()
else:
list(map(self.parse_forum_page, file_path_lists))
def filter_file_path(self, file_path_list):
parse_file = pd.read_csv(self.all_topic_file).file_path.unique()
file_list = set(file_path_list) - set(parse_file)
print('共{}个页面'.format(len(set(file_path_list))), '
已解析{}个页面'.format(len(set(parse_file))))
return list(file_list)
def parse_forum_page(self, file_path):
""" 解析社区页面具体功能实现 """
with open(file_path, encoding='utf-8') as f:
response = f.read()
response = etree.HTML(response)
try:
forum = response.xpath('//div[@id="section-content"]/h1/text()')[0]
forum = re.search('Forum: (.*)', forum).group(1)
topics = response.cssselect('#section-content > ul.rowgroup.topic-list > li')
data_list = list(map(self.get_topic_info, topics))
for data_dict in data_list:
data_dict['forum'] = forum
data_dict['file_path'] = file_path
BreastCancer.write_to_file(data=data_list, file=self.all_topic_file, columns=self.all_topic_columns, mode='a')
print(file_path + '解析完成')
except Exception:
traceback.print_exc()
print(file_path + '解析错误')
return
@staticmethod
def write_to_file(file, data=None, columns=None, mode=None, index=False, header=False):
if mode == 'w':
data = pd.DataFrame(columns=columns)
data.to_csv(file, index=False)
elif mode == 'a':
df = pd.DataFrame(data=data)
df = df.loc[:, columns]
df.to_csv(file, mode=mode, index=index, header=header)
@staticmethod
def all_forum_stat():
all_hgroup_count = forum_info.hgroup.nunique()
all_forum_count = forum_info.forum_topic.nunique()
all_topic_count = pd.to_numeric(forum_info.count_topic.str.replace(',', ''), downcast='integer').sum()
all_post_count = pd.to_numeric(forum_info.count_post.str.replace(',', ''), downcast='integer').sum()
all_topic_pages = forum_info.apply(lambda x: divmod(int(x.count_topic.replace(',', '')), 30)[0] + 1,
axis=1).sum()
print('共有hgroup:{}个'.format(all_hgroup_count))
print('共有社区:{}个'.format(all_forum_count))
print('共有话题:{}个'.format(all_topic_count))
print('共有评论:{}个'.format(all_post_count))
print('共需下载:{}个页面'.format(all_topic_pages))
if __name__ == '__main__':
breastcancer = BreastCancer()
# breastcancer.all_forum_stat()
# 1. 下载社区首页
# breastcancer.parse_forums_index()
# 2. 获取所有社区页面url
# breastcancer.get_all_forums_ids()
# 3. 下载所有社区页面
# breastcancer.get_all_forum_page(pool=False)
# 4. 解析所有社区页面
breastcancer.start_parse_forum_page()