线性分类器

1.线性分类器得分函数
CIFAR-10:一共有10个类别,几千张图片的分类任务
给你一张图片,然后得出每个类别的分数是多少,结果是一个得分向量score-vector
我们把[32,32,3]的图片看成x,线性分类器就是给出权重W,得到10个得分
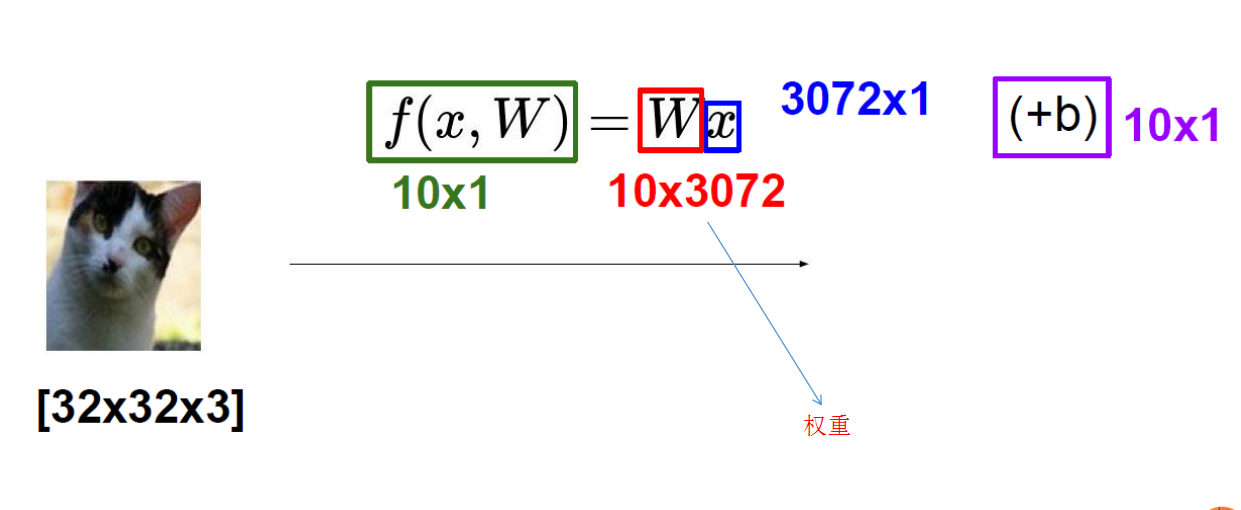
简单一点,我们把32*32*3的矩阵拉成一个3072*1的向量,最后我们想得到10维的得分向量,那么我们的权重W就得是10*3072的矩阵,相乘后得到10*1的向量
f是一个函数,它所做的事情非常简单,就是就输入矩阵映射成为得分向量,决定这个得分函数的就是W,我们希望得到最合适的一组W。
识别图像---其实就是分类问题
图片识别是计算机视觉的核心任务
每个图片是由像素组成的
200*200*3=12000个像素值(特征)
单通道:灰度值【0~255】
一个像素点只有一个值
三通道:RGB
一个像素点有三个值组成
图像数字化三要素:长度,宽度,通道数
给你一张图片,也就是一个矩阵,让你完成一个任务,识别图像中的内容找出分类,一共有10个类别几千张图片
把你输入的矩阵x,通过f,映射为一个得分向量
把图像做一个reshape,将其拉成一个一维3072*1的向量。
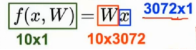
为了得到一个10*1的矩阵(向量),要配给W一个10*3072,所以10*3072 与 3072*1 相乘,得到一个10*1的列向量,就认为是一个10维的得分向量
实例:

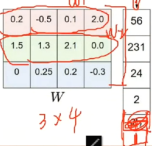
我们输入一个图像,拉伸后成为1维,为了方便,简单为4*1的向量,得分向量为3个分类,3*1,于是我们的W就要是一个3*4的矩阵,线性分类器嘛,有偏置项b(wile增加灵活性),最后我们得到y=W*x+b的线性函数(得分函数,y就是得分向量)。
上面的W在dog类别中得分最高,这显然不是我们想要的,我们想要的是在正确的类别上有较高的得分,在错误的类别得分较低,所以我们要做的是修正这个W,使我们输入一张图片后,在正确的类别上得分最高。
2、线性分类器的理解---空间划分
Wx+b是空间的点
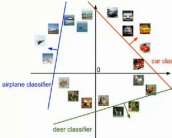
上面的例子中,有3个类别,我们可以把W的第一行+b看做是决定第一个类别的最终得分,W的第二行+b决定第二个类别的分数,以此类推,我们三个不同的W和b其实就是对于空间中进行了划分,相当于三个直线(确切说是超平面,)然后我们输入不同的x,其实就是空间中的不同区域。
线性分类器的理解---模板匹配(模板指的是W中的某一行)
W的每一行可以看做是其中一个类别的模板
每类得分,实际上是像素点和模板匹配度
模板匹配的方式是内积运算
没有b的情况:
注意哈:有些写成了y=wx,没有偏置项b,可能是这样处理的---将偏置项的值装到了W矩阵的最后一列,然后在x向量中增加一个1,也就是:
3、损失函数 LossFunction/CostFunction--衡量吻合程度
给定W,可以由像素映射到类目得分
可以调节参数(权重)W,使得映射的结果和实际类别吻合
损失函数是用来衡量吻合程度的。
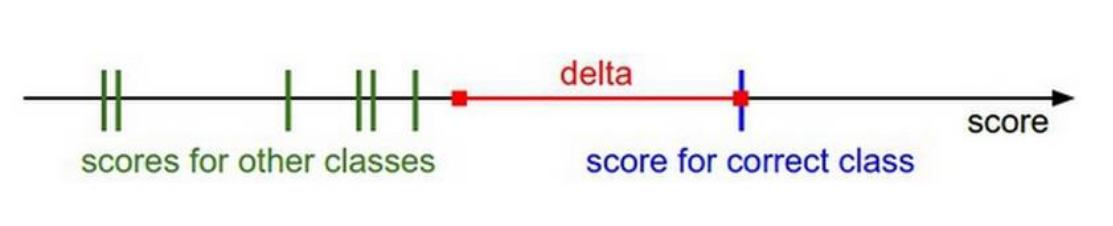
损失函数1:hinge loss支持向量机SVM损失
给你一套试卷,要求你在正确题目的得分要比其他任何错误题目的得分要高出来一个值Δ,你要是所有的都高出了Δ,好,不动,要是没有高出,那就加一个惩罚值(你缺的多少就惩罚多少)
具体:
对于训练集上第i张图片数据xi
在W下会有一个得分结果向量f(xi,W)
第j类的得分为f(xi,W)j
则在该样本上损失我们由下列公式计算得到


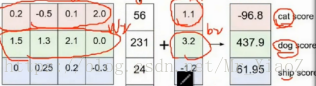
现在我们由三个类别,而得分函数计算某张图片的得分为f(xi,W)= [13,-7,11],而实际的结果是第一类yi=0,假设Δ=10(在正确的类别上的得分比错误上的类别高出至少10分),上面的公式把错误类别(j不等于yi)都遍历一遍,求值加和:


我们看一下这种情况:
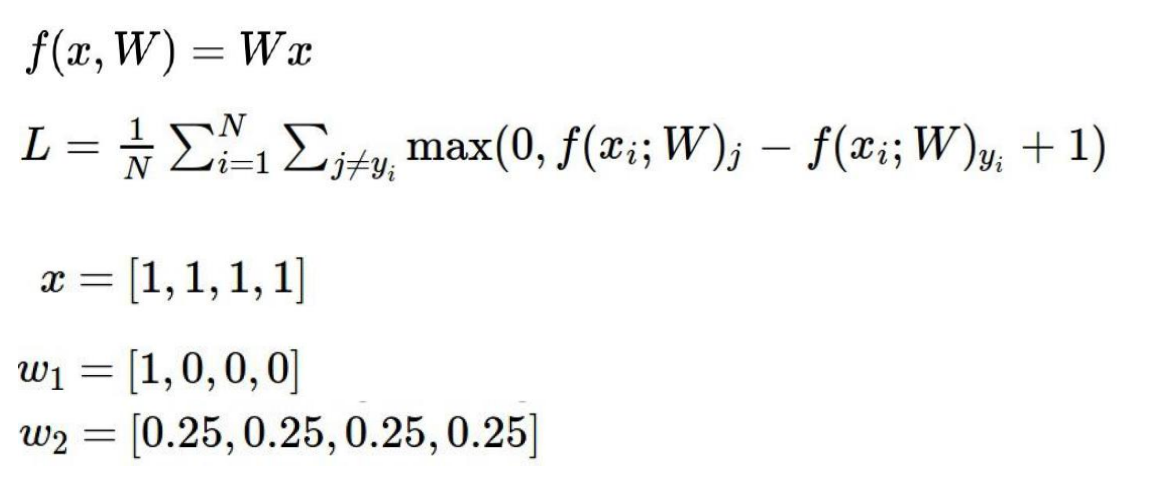
f(x,w1)=1*1+1*0+1*0+1*0=1
f(x,w2)=1*0.25*4 = 1
我们发现不同的权重结果竟然相同,那么这种情况下我们应该选择哪种参数呢?或者说哪个参数更好呢?其实我们可以猜到,第二种效果更好,因为他考虑到了所有的x,第一种的话他只考虑到了第一个参数,这样的话很容易出现过拟合的情况,即训练集上效果非常好,但测试集上效果却不好。因此第二种更好,但是有没有一种什么方法让我们把第二种挑出来呢?当然是有的,那就是加入一个正则化惩罚项
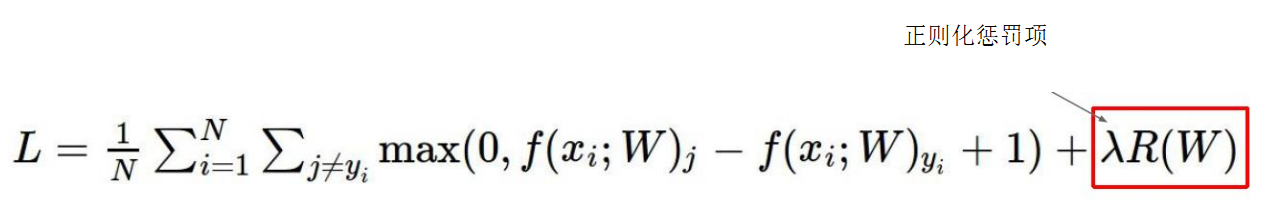
L(W1)的正则化惩罚 = 1^2+0^2 + 0+0=1
L(w2)的正则化惩罚 = (1/4)^2 + (1/4)^2 + (1/4)^2 + (1/4)^2 = 1/4
这样w2的正则化惩罚就会更小,w1的惩罚会更大,我们就会更认可w2,总体损失函数就会更小,我们就会选择w2了。
最后除以N是因为要避免样本个数对结果的影响,样本个数对于模型的好坏是没有影响的。
softMax(归一化的分类概率)
损失函数2:cross-entropy(交叉熵)
做一个归一化,在A、B、C、D四个选项中选择他们的概率有多高,我自己有一份标准答案(概率向量),评估你得到的概率和我的标准答案(概率)之间的距离
对于训练集中的第i张图片数据xi
在W下会有一个得分结果向量fyi
则损失函数记做:
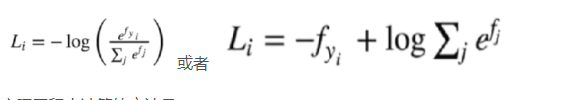
其输入值是一个向量,向量中元素为任意实数的
评分值
输出一个向量,其中每个元素值在0到1之间,且
所有元素之和为1
实际工程中计算的方法是

因为e的指数次方是得分,如果太高的话容易溢出
其实softmax损失就是将之前的得分换成了概率。
softmax实例

2种损失函数的对比
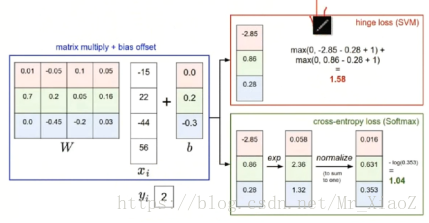
SVM的随机函数有一个缺点,当错误类别和正确类别的得分非常接近时,比如说正好相差△,那么损失函数结果为0,但其实分类结果并不好,但是softmax的话对于每一个分类结果都会对值进行e次幂,这样差距就会放大很多,在经过softmax概率变换,就会得到最优的结果。softmax分类器是一种永不知满足的分类器。
最优化
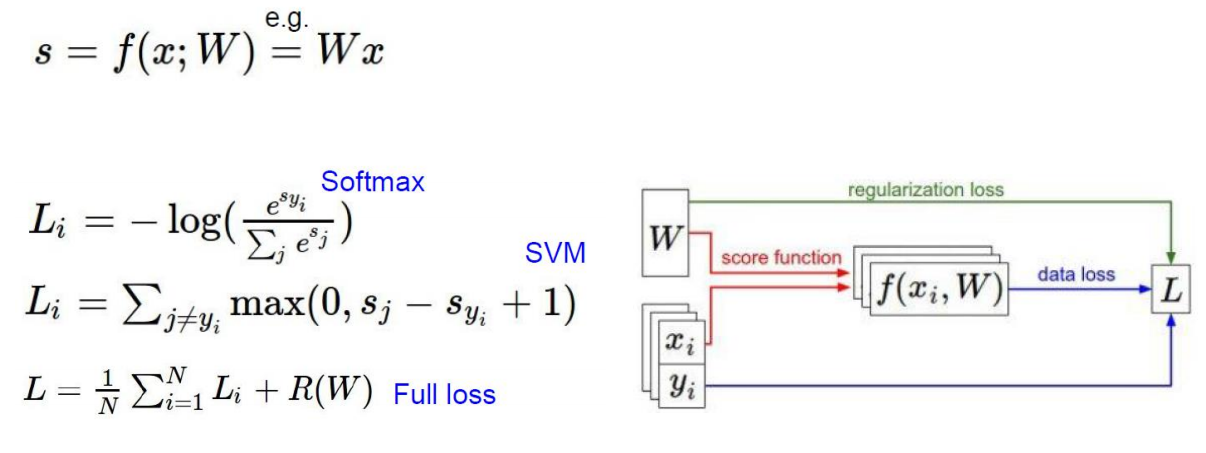
矩阵相乘W*x+b得到了得分向量,然后我们首先是hingeloss(SVM),就是算正确类别的得分要比错误类别的得分高出一个Δ,然后高了没问题,没高就补充缺少的分数,交叉熵损失就是将得分向量转化为了概率(转换公式),然后做一个归一化,我自己有一个标准答案,然后评估你的概率和标准答案之间的距离。注意点,交叉熵损失要对目标值one-hot编码。
4.最优化和梯度下降
当我们通过分类器获得一个预测值,我们会求得一组参数,那么我们怎么知道这个参数时好是坏呢?这就引入了损失函数,损失函数越小说明预测值和真实值越接近。但是,我们知道了如何评判参数的好坏,我们应该如何得到最优参数解呢?我们知道,一次求解肯定是不够的,能得到最优参数的概率微乎其微,所以我们就要通过多次迭代求得最优解。这使就引出了梯度下降,梯度下降是一种通过迭代多次求解参数的方式。我们可以理解成计算机是一个蒙着眼睛的人,他要寻找山坡的最低点,而最低点就是最优解,使得损失函数最小的值。

因为我们的目标是得到最优解,因此我们要告诉计算机最优解是什么样子的,或者说告诉它你走那个方向是正确的。这个方向就是我们对参数进行求导的结果,我们知道导数的几何意义就是某个函数在这个点的切线的斜率,因此,根据这个特性,我们可以知道梯度下降的方向,知道方向以后,还有一个问题,就是我应该走多快呢?或者说一步走多远呢?我们可以想象,步子太大的话可能会越过最低点,到达另一个山头。因此,通常情况下,我们会选择一个小的学习率,慢慢的寻找最优解。
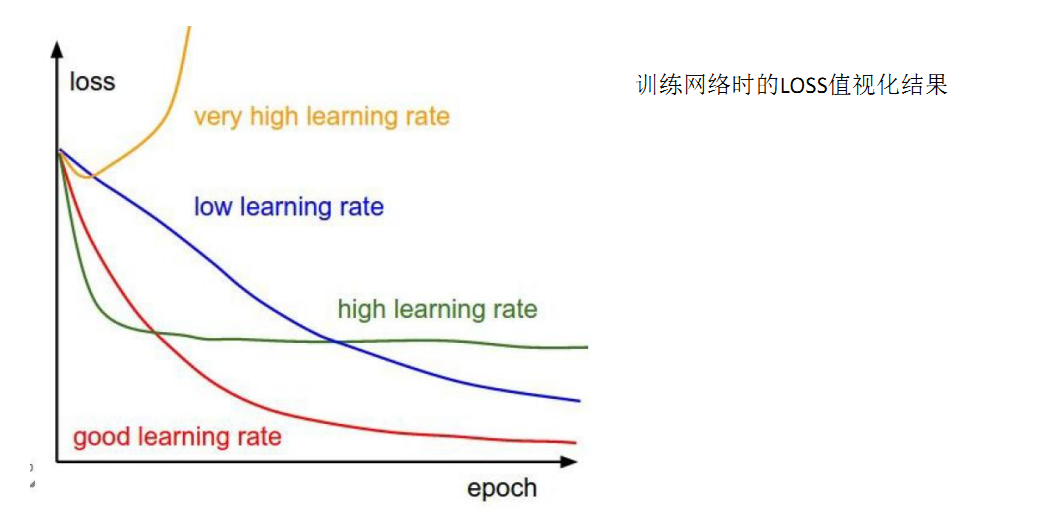
通过测试我们也可以知道,学习率对于结果有很大的影响。
反向传播
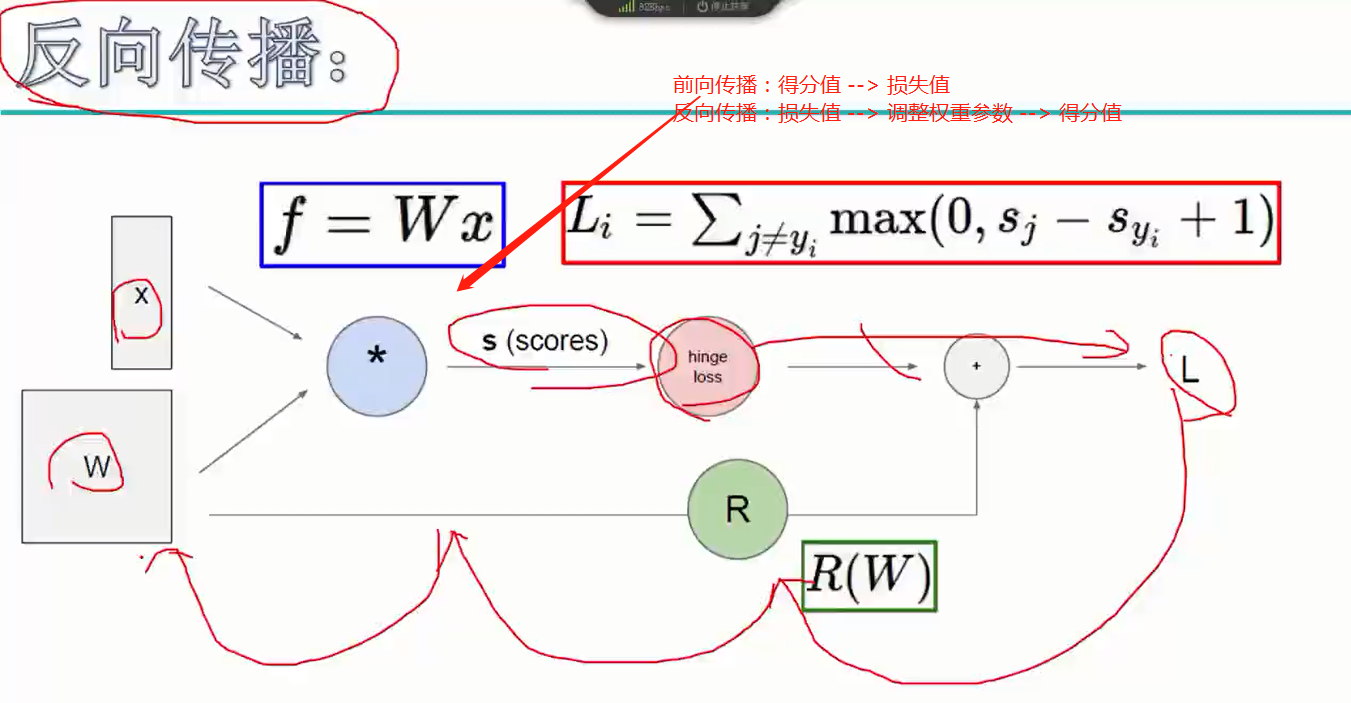
正向传播链式法则
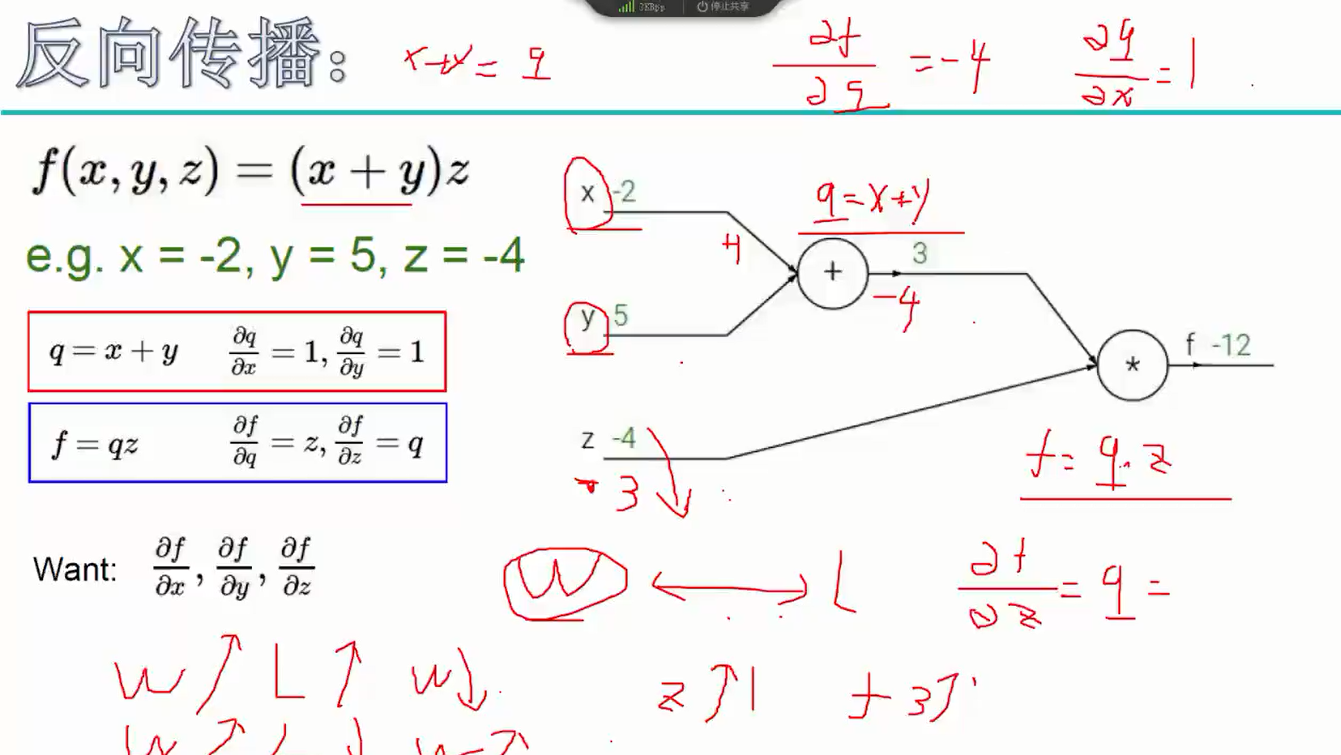
神经网络就是一系列反向传播的过程。
关于softmax和cross entrop的详细解读,推荐这篇文章 https://blog.csdn.net/u014380165/article/details/77284921