一、任务描述
关键短语提取(Keyphrase Extraction),顾名思义,就是给定一篇文本,提取其中的关键短语。这项工作在新闻、学术论文中非常常见。比如,给定如下一篇新闻:

我们能够从中提取到以下一些关键短语,以及相关的权重信息:
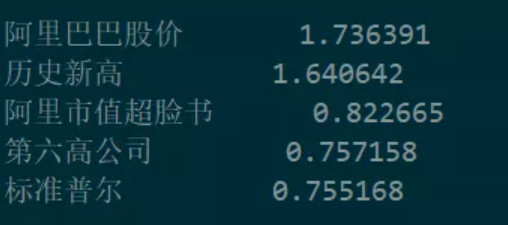
这样的操作很容易让人联想到关键词提取,两者都是从文本中找出概括性的若干个词汇或短语。针对上述文本,我们使用TFIDF方法做关键词提取,得到的结果就是:
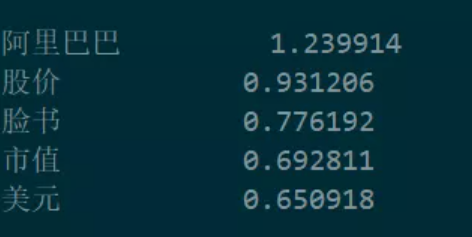
显然,关键短语相较于关键词的优势就是,它更能明显地提供有效信息,从这些关键短语中,我们即使不读新闻,也可以很容易地看出文本的大致主题内容。可以应用在文本检索、文本摘要、信息可视化、文本聚类等各个任务中。
二、两种处理方法——抽取式与生成式
寻找文本的关键短语,根据解决思路,一般分为抽取式和生成式。抽取式,就是从已有的文本中,抽取若干短语作为关键短语;而生成式是近些年才出现的,借助于目前诸如RNN、Bert等深度模型,使用 seq2seq将文本信息编码,使用模型生成若干关键短语。我们本篇主要讨论抽取式关键短语,顺带提及生成式,它包括三个步骤。
-
找到候选短语(Get candidate phrases)
由于文本是由很多词汇顺序构成的,那么最简单的思路,就是把文本中相邻的若干短语拼凑起来,组合成候选短语,并赋给该短语一个权重。
例如,上述例子中,我们按照 n-grams 的思路找到的候选关键短语包括如下这些:
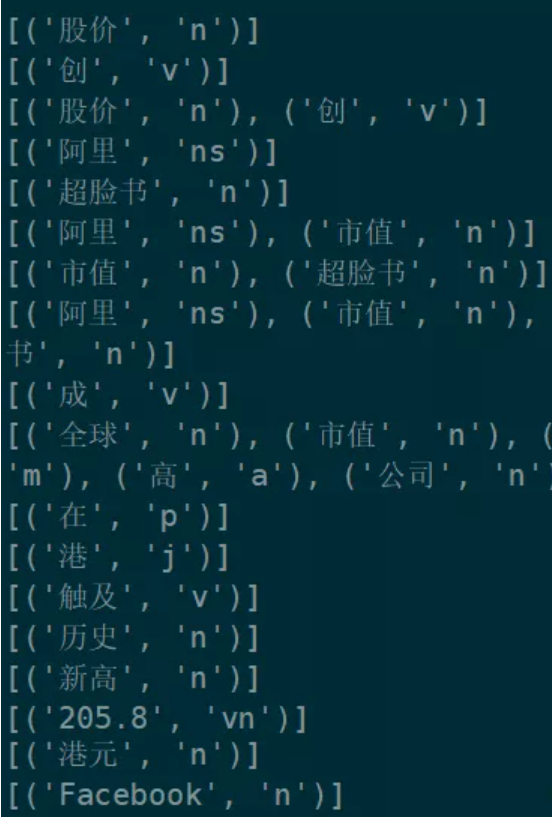
其中,每一行都是一个 n-grams 候选短语实体,其中每一个词都附有相应的词性标识。可以看到,其中包含了很多杂质,比如停用词、虚词等等。此外,根据特定的词性要求,不符合名词、动词短语的也要进行过滤删除。
-
为候选短语赋权重(Caculate weights of candidate phrases)
为一个短语赋予权重,即找到候选短语的某种特征,这是抽取式关键短语的核心环节。
计算一个权重,常见的方法主要包括TFIDF特征(Salton and
Buckley, 1988),text-rank 权重(Mihalcea and Tarau,
2004),主题权重等等。除此之外,也包括Lead-3权重等。
1、关于 TFIDF 和 text-rank 的比较
TFIDF和 text-rank 权重相对好理解,这也是早期关键短语的处理思路。
需要指出的是,text-rank是从谷歌的 page-rank 中延伸出来的,page-rank 效率之所以高,是因为它有数以亿计的网页构成的图做支撑。而text-rank则仅仅是在一篇舆情文本中做计算,一篇文本,最常见的,也就1000字到1万字上下,这样小的规模构成的图,其实并不能真实地反映出词汇之间的关联关系,由此,有人提出了 ExpandRank(Wan and Xiao, 2008b; Wan and Xiao, 2008a),很显然,这样效果会好。
TFIDF相比于text-rank,更倾向于抽取出低频词,比如“乔巴罗”,而 text-rank 由于网络特性,就会容易将此类词汇过滤。当然两种算法在关键词提取中的差异较为明显。在关键短语中,一个短语中的多个词汇,加权计算,实际上缩小了这种差距。根据知乎崔果果的实践经验,这两种方法在关键短语的抽取上,效果差异很小。
2、主题模型的使用
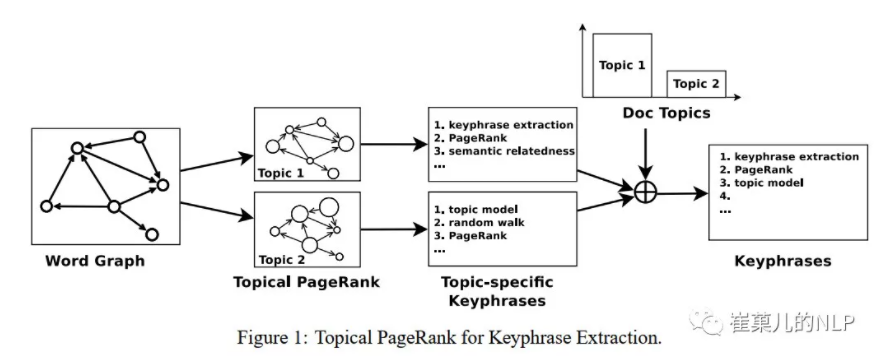
在2010年,刘知远老师的 Automatic Keyphrase Extraction via Topic Decomposition 论文中首次提出了把 LDA 主题模型与text-rank 相结合起来的方法,它巧妙地利用主题模型计算的结果,为text-rank 的迭代计算做了初始化,这样同时拥有了两者的优点。如下图所示。
当然,这种方法处理速度是比较慢的,一般地,迭代一次text-rank 需要对每一个主题都进行计算,假设 LDA 的主题模型有10万个,那么就需要计算 10万次?这太不合理了。然后就有人不断提出简化的方法,Topical Word Importance for Fast Keyphrase Extraction 和 Salience Rank- Efficient Keyphrase Extraction with Topic Modeling 这两篇论文就 LDA 主题数量太多,需要耗费很多计算资源的问题,逐渐简化,直到使用 KL 散度来解决这个主题问题。这个公式非常恰当地契合了问题的需求:

其中,t代表主题,w代表词汇,TS表示一个词汇的主题突出度。与此同时,作者还对这个散度权重做了归一化,这个取值介于0~1之间,越高,那么词汇就越在某些主题中突出,比如“特朗普”非常偏向于美国新闻,取值越低,就越不突出,比如“9月”在各种类型的新闻,文档中都可能出现。根据崔果果的实际操作经验,TS主题突出度方法的效果还是非常美好的。
3、神经网络
既然是寻找特征,那么,神经网络是一把好手,把关键短语抽取的任务建模在神经网络上,当然是可行的,的确也是有人这么做:Keyphrase Extraction Using Deep Recurrent Neural Networks on Twitter。
这篇论文它有几个值得注意的点:关键词提取和关键短语提取是着千丝万缕的联系,在做神经网络建模的时候可以联合建模;另外,不论是 text-rank,还是 LDA,都是对短文本非常敏感的,文章一旦短了,采样就变得稀疏,统计性能就得不到发挥。因此,使用神经网络建模,可以很好的克服上述方法带来的问题。
甚至有人使用神经网络来做生成式的关键短语提取,以解决关键短语不在文本中出现的问题。Deep Keyphrase Generation,神经网络的目的是最大化条件概率,那么,如何输出前k个最优结果,beam-search 是一个非常 nice 的方法。
对于使用神经网络的方法,没有大规模的数据是很难得到理想效果的,也看到一些作者把 text-summarization 任务的数据集也添加进训练中,崔菓儿认为也是不太恰当的。
除此之外,也有人把主题模型和神经网络结合起来做关键短语生成 Topic-Aware Neural Keyphrase Generation for Social Media Language。这个是腾讯的工作,其中的神经网络建模的主题模型还是值得关注的。
对此,崔菓儿并不认为使用神经网络这些方法就是好的,只能说,它进行了一些探索,在泛化能力、数据获取、工业应用代价上,都还有一定距离。
4、其他方法
刘知远老师还提出了一篇相关的论文 Automatic Keyphrase Extraction by Bridging Vocabulary Gap,里面使用到了一个统计概率模型WAM,尽管刘老师起名叫翻译模型,但是跟翻译这个任务没有一毛钱关系,算法的计算流程如下图所示。尽管算法看起来复杂,但是其核心思想就是:文本中的词汇,如果能够进入关键短语,则实际上它以较高的概率存在于文本的标题和摘要中。也就是,这几个任务是相互关联的。
基于大规模的文本的统计计算,就可以在一定程度上克服这带来的Vocabulary Gap问题。

关于这个问题,崔果果的想法是:第一,这是一个监督模型,而且建模比较简单,没有考虑复杂的特征抽取器,完全依赖词频统计,这其实是依赖较大规模的数据才能做到的,这就存在文本数据分布发生变化,模型泛化能力下降的问题;第二,很多时候,对于新闻舆情和学术论文来说,想要抽取他们的关键短语,是已经知道了标题和正文的。那么,直接使用Lead-1算法,把标题的权重加大,即可得到相应的结果,不需要再建模把标题中的特征信息抽取一遍。
-
排序问题
将上述得到的候选短语全部做一个排序,即可得到最终的关键短语啦!一般取阈值,或者top-k来完成
-
计算速度问题
我们做一个对比:
TFIDF 是很久以前提出的方法,至今依然是广泛使用的关键词提取算法。它的处理速度非常快,效率非常高。
相比之下,关键短语抽取的上述论文中的方法,若完全在工业中使用,效率将会非常低。如果使用 LDA 主题模型,比如100万篇文档训练的模型,大约需要消耗10个G 的内存,而使用吉布斯采样的方法做收敛,计算速度也是很慢的。
而如果使用神经网络,则一般需要消耗2G显存,带来微小的工业效果提升。
想象一下,关键词提取每秒处理100篇文本,消耗100M内存,而关键短语提取每秒处理2篇,耗费10G内存与2G显存,是不是听起来非常荒诞?崔果觉得代价有点大~~看来很多论文都是提出了世界观,却没有告诉方法论,导致无法应用。想要真的把这些深度网络模型利用起来,或许还要再等若干年,计算机处理速度更快的时候吧。
-
关键词、关键短语、文本标题、文本摘要
对于一篇文本,从关键词、关键短语、文本标题,到文本摘要,是一个信息压缩逐渐递减的步骤,所以,这些任务之间有很强的相关性。相同的方法都可以应用在其中。
比如,MMR算法是抽取式文本摘要里经典的覆盖文本内容广度的算法,它完全可以应用在关键短语抽取中,避免“白宫”与“美国白宫”这样的短语同时被抽取为关键短语。
就像上面的各种算法,很多抽取或生成关键短语都利用了已有的关键词、文本标题、摘要等信息。
-
一个速度较快的现成工具
这个现成的中文关键短语工具ckpe,它的地址 https://github.com/dongrixinyu/chinese_keyphrase_extractor,使用起来非常方便。
1、考虑到分词与词性标注在这类抽取任务中,F1值是非常重要的,稍微有个错误就会产生错误累积,直接影响最终的结果。所以它使用了北大的 pkuseg分词器与词性标注器。
2、这个算法把基于 tfidf + LDA 的模型做了最大程度的简化,保留了主题突出度,抽取时仅占用35M内存,速度约为7篇每秒。是很适合应用在工业中的方法哟!
3、同时它考虑了短语词性组合、停用词、虚词、首句(标题)权重Lead-1等等因素。
三、改进
由于最近在做一些无监督的关键词短语(实体)抽取工作,其实最大的背景还是没有标注好的实体识别训练数据;所以想到采用无监督的关键短语抽取算法折中去抽取一些实体,于是调研了一波关键短语抽取算法和工具。目前无监督关键短语抽取算法和关键词抽取算法差不多:主要是TFIDF,Textrank 等特征为候选短语的打分。然后抽取得分高的候选短语。
算法流程
关键词短抽取成算法主要分为两部分:1.候选短语抽取;2.候选短语打分 + 候选短语抽取:一般可以采取 "ngram" + 文法规则的做法:比如下方例子中的2gram短语中,[股价_n,创_v ] 中名词(n)后面接动词(v)很显然就不是一个合理的短语,不应该被召回到候选词集合中。而[阿里_ns,市值_n] 中 地名(ns)后面接名词就是个合适候选短语。

- 候选短语打分:通过上述ngram + 文法规则我们召回候选词集合后,之后我们就可以通过 词语的TFIDF,Textrank等权重特征的给短语打分,当然你也可以用一些其他的文本特征给词语打分。总之,最后我们通过各种特征可以计算出每个短语的得分,然后排序后取topk得候选短语就可以得到我们的关键短语了。
引入依存句法分析
依存句法分析这里笔者不做过多的介绍,有兴趣的同学可以去百度一波.但是这里笔者展示一下依存句法分析的结果,通过依存句法分析,我们可以得到一颗如下的依存树,树的每条边记录了连接节点的对于关系,比如 “青年”的定语是“男性”,所以青年和男性是定中关系。具有定中关系的相邻词组就是一个短语,同时被修饰的词通常比较重要(这是笔者的一个假设),所以,笔者认为:具有定中关系的相邻词组是关键词。
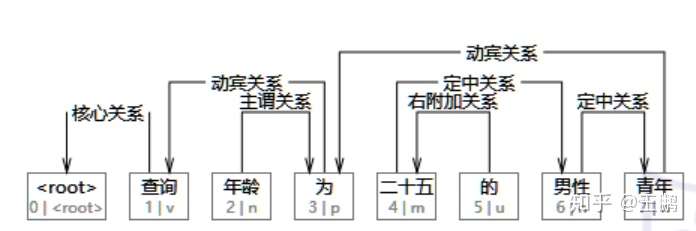
下方是笔者在百度百科中搜索出来的“借款费用”的定义,用依存句法分析了一波,也确实发现具有定中关系的词组组合起来就是关键短语,比如:借款费用,借款利息,外币借款等。
"借款费用是企业因借入资金所付出的代价,包括借款利息、折价或者溢价的摊销、辅助费用以及因外币借款而发生的汇兑差额等" 的依存句法分析结果如下:
1,借款-->定中关系-->2 ,费用
2,费用-->主谓关系-->3 ,是
3,是-->核心关系-->0 ,##核心##
4,企业-->主谓关系-->9 ,付出
5,因-->状中结构-->9 ,付出
6,借入-->介宾关系-->5 ,因
7,资金-->动宾关系-->6 ,借入
8,所-->左附加关系-->9 ,付出
9,付出-->定中关系-->11 ,代价
10,的-->右附加关系-->9 ,付出
11,代价-->动宾关系-->3 ,是
12,,-->标点符号-->3 ,是
13,包括-->并列关系-->3 ,是
14,借款-->定中关系-->15 ,利息
15,利息-->动宾关系-->13 ,包括
16,、-->标点符号-->17 ,折价
17,折价-->并列关系-->15 ,利息
18,或者-->左附加关系-->21 ,摊销
19,溢价-->定中关系-->21 ,摊销
20,的-->右附加关系-->19 ,溢价
21,摊销-->并列关系-->17 ,折价
22,、-->标点符号-->23 ,辅助
23,辅助-->定中关系-->24 ,费用
24,费用-->并列关系-->21 ,摊销
25,以及-->左附加关系-->33 ,差额
26,因-->状中结构-->30 ,发生
27,外币-->定中关系-->28 ,借款
28,借款-->介宾关系-->26 ,因
29,而-->状中结构-->30 ,发生
30,发生-->定中关系-->33 ,差额
31,的-->右附加关系-->30 ,发生
32,汇兑-->定中关系-->33 ,差额
33,差额-->并列关系-->21 ,摊销
34,等-->右附加关系-->13 ,包括
实战部分
实战部分笔者的思路如下: + 首先采用传统的关键词词组抽取算法抽取一下句子中的关键词短语(可以有效抽取一些新词和关键短语),这样防止一些专有名词分词错误,这里你也可以采用实体识别算法。然后将新抽出的新词加入用户词典。 + 然后采用依存句法分析得到句子的依存树,将具有定中关系的相邻词组抽取出来。 关键短语抽取推荐使用:ckpe 这个工具库,作者引入了LDA主题模型去优化关键短语打分,效果不错。 至于依存句法分析:笔者选择的是hanlp。 代码如下:
from pyhanlp import * import ckpe def extract_key_phrase(sentence): key_phrase = [] ckpe_obj = ckpe.ckpe() entity = ckpe_obj.extract_keyphrase(sentence,top_k=10) for i in entity: CustomDictionary.insert(i) print(entity) tree = HanLP.parseDependency(sentence) for word in tree.iterator(): # 通过dir()可以查看sentence的方法 print("%d,%s-->%s-->%d ,%s" % (word.ID, word.LEMMA, word.DEPREL, word.HEAD.ID, word.HEAD.LEMMA)) if word.DEPREL == "定中关系": key_phrase.append(word.LEMMA + word.HEAD.LEMMA) return [ phrase for phrase in key_phrase if phrase in sentence]
输入一下句子: sentence= "借款费用是企业因借入资金所付出的代价,包括借款利息、折价或者溢价的摊销、辅助费用以及因外币借款而发生的汇兑差额等"
extract_key_phrase(sentence)
最后结果如下: + ckpe的抽取结果为:['外币', '差额', '费用', '利息', '代价', '资金', '企业'] + ckpe + 依存树 的结果为: ['借款费用', '借款利息', '辅助费用', '外币借款', '汇兑差额']
结论
所以在关键短语抽取算法中引入依存句法分析似乎有着不错的效果,其实也是利用了句法特征。做为一个nlper 如果能够善于使用词性特征,句法特征等这些传统特征也能够做很酷的事情,比如无监督抽取出这么好效果的关键短语。当然无监督会产生较多的错误,我们可以采用这种算法辅助去标注数据,最终通过有监督的深度模型训练达到最佳效果。
参考
https://link.zhihu.com/?target=https%3A//github.com/dongrixinyu/chinese_keyphrase_extractor
https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s/fBSEtM4gQ6-5jQpy0JaQvw
https://zhuanlan.zhihu.com/p/107663730
四、关键词提取实战
import ckpe ckpe_obj = ckpe.ckpe() text = '我都跟你说了,跟你说多少遍了,就跟你说了,明天中午我跟你说会处理一下的好不好?' key_phrases = ckpe_obj.extract_keyphrase(text) print(key_phrases) import jieba.analyse #textrank keywords_textrank = jieba.analyse.textrank(text) print(keywords_textrank) #tf-idf keywords_tfidf = jieba.analyse.extract_tags(text, withWeight=True) print(keywords_tfidf)
五、详细代码
import os import ckpe import tqdm import pandas as pd from root_path import root import utils.word_process as word_process class ExtractKeys(object): """ 数据清洗:从原始数据总结关键词 """ def __init__(self): self.ckpe_obj = ckpe.ckpe() self.root = os.path.join(root, "confusion_detection") self.raw_data = os.path.join(self.root, "data", "raw_data", "all.txt") self.clean_data_dir = os.path.join(self.root, "data", "clean_data", "class_2_keys.xlsx") def save_dict(self, key_dict: dict): """将生成的关键词表保存到excel""" cls = [] keys = [] for key, value in key_dict.items(): cls.append(key) keys.append(value) dataframe = pd.DataFrame({'cls': cls, "keys": keys}) dataframe.to_excel(self.clean_data_dir, sheet_name='data',index=False, encoding="utf8") def sort_dict(self, key_dict: dict): """对关键词表权值排序,取前十名""" items = {} for key, value in key_dict.items(): result = sorted(value, key = lambda x:x[1]) result = list(set([x[0] for x in result])) result = [x for x in result if len(x)>1] items[key] = result return items def main(self): """主函数""" stop_word_list = word_process.get_stop_list() keys_dict = {} with open(self.raw_data, "r", encoding="utf8") as f: data_lines = tqdm.tqdm(f.readlines(), smoothing=0, mininterval=1.0) data_lines.set_description('正在处理数据...') for line in data_lines: data_tuple = line.split(" ") label = data_tuple[0] sentence = data_tuple[1] if label not in keys_dict: keys_dict[label] = [] else: key_phrases = self.ckpe_obj.extract_keyphrase(sentence, remove_words_list=stop_word_list) keys_dict[label] = list(set(keys_dict[label] + key_phrases)) items = self.sort_dict(keys_dict) self.save_dict(items) if __name__ == '__main__': ExtractKeys().main()