django的请求生命周期
{drf,resful,apiview,序列化组件,视图组件,认证组件,权限组件,频率组件,解析器,分页器,响应器,URL控制器,版本控制}
一、CBV源码分析
准备工作:
新建一个Django项目
写一个基于类的视图
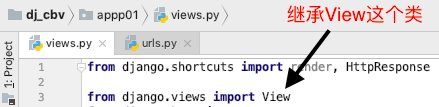
继承,写get,post方法
from django.shortcuts import render, HttpResponse from django.views import View from django.http import JsonResponse # Create your views here. class Test(View): def dispatch(self, request, *args, **kwargs): # codes obj = super().dispatch(self, request, *args, **kwargs) # codes return obj def get(self, request, *args, **kwargs): return HttpResponse('cbv_get') def post(self, request, *args, **kwargs): return HttpResponse('cbv_post')
视图写好之后写路由
把views导过来,
类名.as_view() 直接执行
from django.conf.urls import url from django.contrib import admin from appp01 import views urlpatterns = [ url(r'^admin/', admin.site.urls), # 在这里写的 views.Test.as_view(),实际上就是as_view()里面view的内存地址 url(r'^test/', views.Test.as_view()), ]
分析一下执行的流程:
如果当初放的是函数内存地址不会去执行,请求来了经过路由做分发。但是如果放的是函数加括号直接就执行了(程序一点一运行立马这里就执行),执行Test.as_view的方法,
Test里面没有as_view,所以执行的是父类View里面的as_view方法
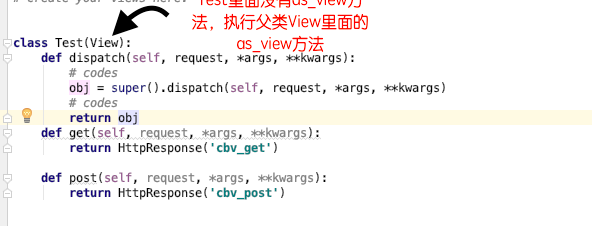
打开父类的View找到as_view方法,类来调用就把类传入,定义了一个view函数,最后返回了这个view,所以在路由层写的实际上就是view(as_view()内部的)这个函数的内存地址。
当请求来了,来了执行的实际上就是view加括号执行。在执行前
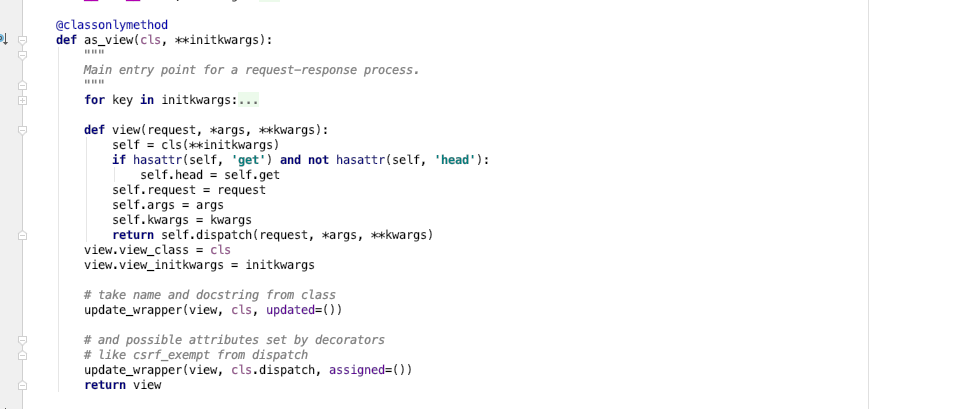
这里面外层函数有个cls(这个cls就是Test这个类,产生了对象赋值给了self。),在内部函数有个对外部作用域的引用,所以这个view就是一个闭包函数。
把请求的request对象赋到了self.request里面
最后返回了一个self.dispatch函数,其实就是在执行这个函数。
这个dispatch函数就是生成的Test这个类的,这个Test类里面没有这个dispatch,所以执行的是View的dispatch。
所以请求来了就是执行dispatch方法
这里面取到请求的小写,判断在不在self.http_method_names中,如果是get请求在这个列表里面
通过getattr反射,self是Test对象,找到get方法,找不到返回错误提示(
self.http_method_not_allowed
)
handler=test对象中get方法的内存地址,
两层判断。
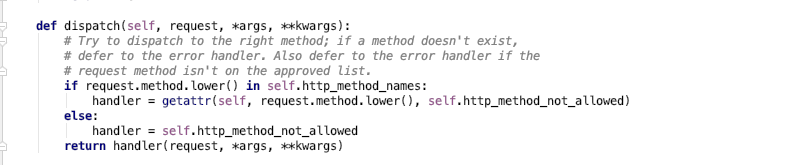
看self.http_method_names源码

self.http_method_not_allowed源码

源码执行的流程?
CBV源码分析
cbv和fbv
1 在views中写一个类,继承View,里面写get方法,post方法
2 在路由中配置: url(r'^test/', views.Test.as_view()),实际上第二个参数位置,放的还是一个函数内存地址
3 当请求来了,就会执行第二个参数(request,参数),本质上执行view()
4 view内部调用了dispatch()方法
5 dispatch分发方法,根据请求方式不同,执行的方法不同
二、resful规范 ----->软件开发的一种规范,好处是方便前台跟后台交互,后台跟后台交互可以直接访问
面向资源架构,面向资源编程。把网络上所有东西都当成资源。
10个规范
1.与后台做交互,通常采用https协议,这样安全
2.域名 有两种格式
https://api.baidu.com 这就说明这是百度提供的这个接口,这种存在跨域问题。
https://www.baidu.com.api/
3.版本 ,接口不能保证不改动
https://www.baidu.com.api/v1
https://www.baidu.com.api/v2
4.路径上所有的东西都是资源,均使用名词来表示。不用动词get,delet。。。
https://www.library.com.api/v1/books/ 拿所有书
https://www.library.com.api/v1/book/ 拿一本书
5.method(请求的方式)来表示增删查改,链接上看不出来只有在请求方式上能看出来增删查改。
https://www.library.com.api/v1/books/ get请求,获取所有书
https://www.library.com.api/v1/books/ post请求,新增一本书
https://www.library.com.api/v1/book/1 delete请求,删除一本id为1的书
https://www.library.com.api/v1/book/1 get请求,获取id为1的这本书
https://www.library.com.api/v1/book/1 put/patch请求,修改id为1的这本书
6.过滤条件
https://www.library.com.api/v1/books?limit=10 只拿前十本书
https://www.library.com.api/v1/books?price=20 只拿价格为20元的书
7.状态码
200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
204 NO CONTENT - [DELETE]:用户删除数据成功。
400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
等价于:{'status':100,}
8.错误处理,返回错误信息,error当做key
{status:101,error:"不可以这样"}
9.返回结果,针对不同操作,服务器向用户返回的结果应该符合以下规范。
GET /collection:返回资源对象的列表(数组)
GET /collection/resource:返回单个资源对象
POST /collection:返回新生成的资源对象
PUT /collection/resource:返回完整的资源对象
PATCH /collection/resource:返回完整的资源对象
DELETE /collection/resource:返回一个空文档
10.返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。
返回结果中提供链接(获取一本书)
{
id:1
name:xxx
price:12
publish:www.xxx.com.api/v1/publish/1
}
三、Django中写resful的接口
路由设计很重要。
urlpatterns = [
url(r'^users/', views.users),
url(r'^user/(?P<id>d+)', views.user),
]
模拟数据库,列表嵌套字典
users_list = [{"id":1,"name":'zrg',"age":18},{"id":2,"name":'yj',"age":19},{"id":3,"name":'xyw',"age":18}]
def users(request): # 返回字典里面写status,如果成功的话。 需要把users_list取到的数据赋给response response = {'status': 100, 'erros': None} # 如果method等于get请求的话获取所有用户,并且返回resful规范 if request.method == 'GET': response['users'] = users_list # 导入JsonResponse,字典里面套了列表所以safe=False return JsonResponse(response, safe=False) # 如果method等于post请求,新增 if request.method == 'POST': # 新增的话,数据取出来添加到users_list里面去 name = request.POST.get('name') age = request.POST.get('age') users_list.append({'id': len(users_list) + 1, 'name': name, 'age': age}) # response['user']={'name':name,'age':age} response['msg'] = '新增成功' return JsonResponse(response)
# 单个的增删改
# 把参数传过来,通过分组来做(有名无名分组)
# 单个的增删改 # 把参数传过来,通过分组来做(有名无名分组) def user(request, id): response = {'status': 100, 'erros': None} if request.method == 'GET': id = int(id) response['user'] = users_list[id] return JsonResponse(response)
用postman提交不会自动补/,在浏览器会自动补/(中间件的原理添加)。
所以在postman这个软件里用就写全的路径!get请求可以重定向,post请求没有重定向这一说。
四、drf写resful的接口 是一个app
drf:Djangorestframework
1.安装
pip3 install Djangorestframework
在pycharm里也可以安装
2.简单使用
要使用先去APP里注册

基于drf写接口,写cbv,视图层# 基于drf写接口,写cbv
# 没有也可以写,有了更好写接口 # 导入rest_framework里面的views from rest_framework.views import APIView from rest_framework.response import Response # Response 也是继承了HttpResponse,这个Response就传一个字典就可以了,会自动序列化。 # 写类继承APIView,写get,post方法 # class DrfTest(views.APIView): # 等同于 class DrfTest(APIView): def get(self, request, *args, **kwargs): response = {'status': 100, 'erros': None} response['users'] = users_list # 传列表传字典 # 用drf的Response,可以通过请求客户端来判断返回数据格式是什么样的,用浏览器返回的是页面。。。 return Response(response) # 返回JsonResponse也可以,有数据,没页面 def post(self, request, *args, **kwargs): name = request.data.get('name')
pass
# 原生Django只能处理form-data 和 urlencode 编码,json处理不了,drf就能处理了,但是取值从大写POST里面取值。
def post(self, request, *args, **kwargs): # 传参 # data方法这里面是所有编码方式都能转成字典 name = request.data.get('name') #从data这个字典里拿到post提交的form-data 和 urlencode ,json格式的数据 print(name) return HttpResponse('ok')
APIVIew源码分析
dispatch方法:
# 传入的request是原生的request对象
# 这个request已经不是原生的request了,但是它内部有个原生的request对象
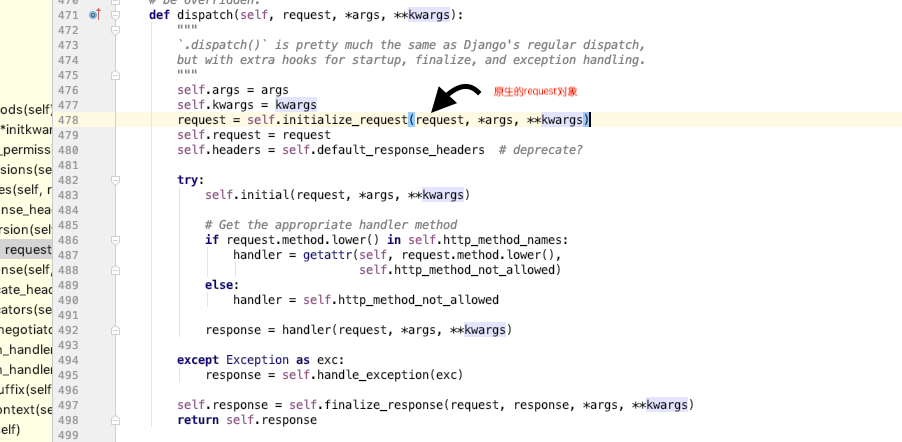
request = self.initialize_request(request, *args, **kwargs)
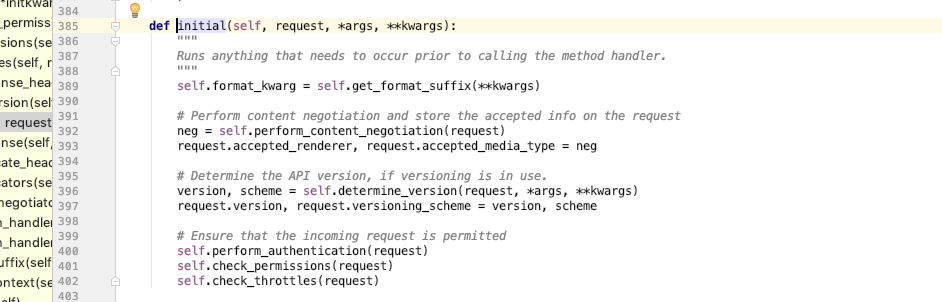
self.initial(request, *args, **kwargs)#这里面有权限,认证,频率
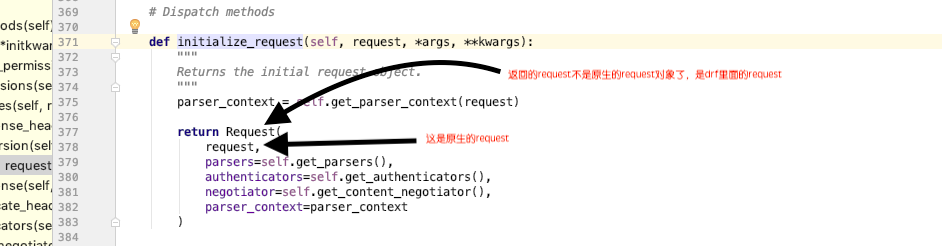
Request源码的分析
as_view,dispatch,self.initialize_request,里面Request
request.data实际上是个方法,才转换数据(如果前端传的formdata,URLencode就从大写post返回,如果json从body体里拿出来转换回来。---->解析器)
也有request.method,触发attr,反射原来的request
request.POST,等价于request._request.POST
request.GET
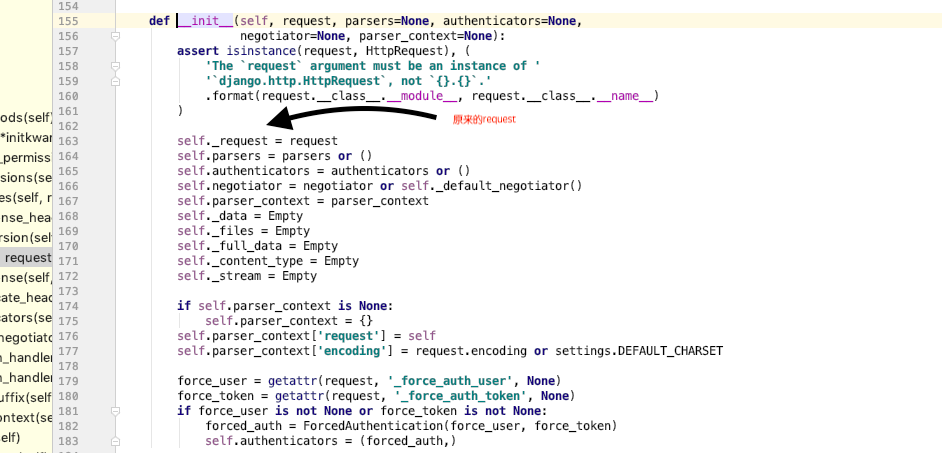
Request源码分析
request.data其实是个方法,被包装成了属性
重写了__getattr__
print(request.GET)
# 就相当于:
print(request.query_params) query_params----->查询的参数
五、drf之序列化组件
序列化:把Python中的对象转成json格式字符串
反序列化:把json格式转换成我樱桃红对象
序列化组件
Serializer
ModelSerialier
class MEta:
model
fields
depth
publish=
全局,局部钩子函数
反序列化:
保存
修改
全局跟局部钩子 看源码底往上走,自己-父类-父类的父类。。。。 self当前序列化的对象
----------------- ------------------- ------------------- -------------
第二步 使用 books_xlh = BookXlh(books_l,many=True)
books_xlh.data就是序列化完成的字典
from django.shortcuts import render # Create your views here. from rest_framework.response import Response from rest_framework.views import APIView from app01 import models from app01.Myxlh import BookXlh # # 写一个获取所有图书的接口 # class Books(APIView): # def get(self,request,*args,**kwargs): # # 所有图书拿出来,转成json格式 # books_l=models.Book.objects.all() # # 用的话,要序列化谁,就写一个序列化类(新建文件夹或py文件),这个类继承一个东西, # # 然后用的时候直接用这个类生成一个对象就可以了。 # # 比如序列化这个book,就单独为这个book写个序列化的类 # # # 用BookXlh需要导入 # # 第一个参数需要序列化的queryset对象,第二个参数many=True(如果序列化多条必须) # books_xlh = BookXlh(books_l,many=True) # # isinstance=单个对象的时候,many=False 比如 books_l=models.Book.objects.all().first # print(books_xlh.data) #是一个字典 # return Response(books_xlh.data) # 优化以上代码 # 写一个获取所有图书的接口 class Books(APIView): def get(self, request, *args, **kwargs): # 字典应该是: response = {'status': 100, 'msg': 'successful'} # 所有图书拿出来,转成json格式 books_l = models.Book.objects.all() # 用的话,要序列化谁,就写一个序列化类(新建文件夹或py文件),这个类继承一个东西, # 然后用的时候直接用这个类生成一个对象就可以了。 # 比如序列化这个book,就单独为这个book写个序列化的类 # 用BookXlh需要导入 # 第一个参数需要序列化的queryset对象,第二个参数many=True(如果序列化多条必须) books_xlh = BookXlh(books_l, many=True) # isinstance=单个对象的时候,many=False 比如 books_l=models.Book.objects.all().first print(books_xlh.data) # 是一个字典 response['books'] = books_xlh.data return Response(response) # 获取一本书的 class Book(APIView): def get(self, request, id): response = {'status': 100, 'msg': '成功了'} book = models.Book.objects.filter(pk=id).first() book_xlh = BookXlh(book, many=False) response['book'] = book_xlh.data return Response(response)
第一步先写一个类(要序列化哪个表模型,就对应着哪个表模型写一个序列化的类):class BookXlh(serializers.Serializer):
# 单独写类 from rest_framework import serializers # from rest_framework.serializers import Serializer from rest_framework.request import Request class BookXlh(serializers.Serializer): # 写序列化哪个字段 id=serializers.CharField() title=serializers.CharField() price=serializers.CharField() # 用BookXlh需要导入
以上如果不指定source,字段名字必须跟数据库名字对应起来。
写路由
"""dj_cbv2 URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/1.11/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.conf.urls import url, include 2. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls')) """ from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^books/', views.Books.as_view()), url(r'^book/(?P<id>d+)', views.Book.as_view()), ]
source
一旦指定了source,字段名跟source的值一定不能重复。
# 单独写类 from rest_framework import serializers # from rest_framework.serializers import Serializer from rest_framework.request import Request class BookXlh(serializers.Serializer): # 写序列化哪个字段 id=serializers.CharField() # title=serializers.CharField() # 尽量让名字不要跟数据库名字重合,通过source=可以改名。 name=serializers.CharField(source='title') price=serializers.CharField() # 拿publish,拿到的是名字 publish_name = serializers.CharField(source='publish.name') publish_id = serializers.CharField(source='publish.pk') # 把出版社所有东西都拿出来 publish_dic=serializers.SerializerMethodField() def get_publisn_dic(self,obj): #obj 就是当前book对象 return {'id':obj.publish.pk,'name':obj.publish.name} #这个字典赋给get_publisn_dic # 用BookXlh需要导入 # 注意: #1、 变量名和source='xx',不能重合 #2、source还支持继续点 #3、source不仅支持字段还支持执行方法 #4、支持写方法,如下,方法一定要传一个参数,就是当前book对象 # # 把出版社所有东西都拿出来 # publish_dic = serializers.SerializerMethodField() # # def get_publisn_dic(self, obj): # obj 就是当前book对象 # return {'id': obj.publish.pk, 'name': obj.publish.name} # 这个字典赋给get_publisn_dic
序列化组件的源码 (source字段后放字段也行,放方法也可以)
publish_dic = serializers.SerializerMethodField()
一定要有个方法跟他对应
def get_publisn_dic(self, obj):
这个方法的返回值就会赋给这个变量publish_dic
这个方法名字也是固定的就是get+字段名
获取作者
先写类并继承
class AuthorXlh(serializers.Serializer): id=serializers.CharField() name=serializers.CharField() age=serializers.CharField()
在book类里,序列化得到。
authors = serializers.SerializerMethodField() def get_authors(self,obj): # 所有作者requeryset对象 authors_list=obj.authors.all() author_xlh=AuthorXlh(instance = authors_list,many=True) return author_xlh.data # 列表推导式 # l1=['name':author.name,'id':author.pk for author in authors_list ]
继承ModelSerializer,这个是跟表模型绑定的序列化。
class BookXlh(serializers.ModelSerializer):
from app01 import models class BookXlh(serializers.ModelSerializer): # 固定写法 class Meta: # 指定表模型 model= models.Book # 要序列化所有字段 fields = '__all__' # 只想序列化title 和 id 这两个字段 # fields = ['title','id'] # 如果想要publish字段显示出版社名字 # 不包含什么字段 # exclude=['title'] #不能和fields连用 不显示title字段 #联表的深度 depth=1 #深度是1 有关联的话往下查一层 # 缺点 全取出来,下几层的参数不可控制 # 全取出来之后,可以覆盖前面的值 ------>相当于重写某些字段 # 多写一个字段 publish = serializers.CharField(source='publish.name') # 作者的详细信息 authors = serializers.SerializerMethodField() def get_authors(self,obj): # 拿到 authors_l=obj.authors.all() # 序列化 author_xlh=AuthorXlh(instance=authors_l,many=True) return author_xlh.data
钩子函数
from app01 import models class BookXlh(serializers.ModelSerializer): # 固定写法 class Meta: # 指定表模型 model= models.Book # 要序列化所有字段 fields = '__all__' # 只想序列化title 和 id 这两个字段 # fields = ['title','id'] # 如果想要publish字段显示出版社名字 # 不包含什么字段 # exclude=['title'] #不能和fields连用 不显示title字段 #联表的深度 # depth=1 #深度是1 有关联的话往下查一层 # 缺点 全取出来,下几层的参数不可控制 title = serializers.CharField(max_length=32, min_length=2, error_messages={'max_length': '太长了'}) # 局部跟全局钩子 # 这个参数是title条件过来的那个参数, def validate_title(self, value): from rest_framework import exceptions if value.startswith('sb'): raise exceptions.ValidationError('不能以sb开头') return value # 全取出来之后,可以覆盖前面的值 ------>相当于重写某些字段 # 多写一个字段 # publish = serializers.CharField(source='publish.name') # # 作者的详细信息 # authors = serializers.SerializerMethodField() # def get_authors(self,obj): # # 拿到 # authors_l=obj.authors.all() # # 序列化 # author_xlh=AuthorXlh(instance=authors_l,many=True) # # return author_xlh.data
增删查改的接口写法
增
# 增加一本书,一般放在books里发请求上 # 新增怎么增?-----> 提交的字典,创建一个对象去保存(快速的方法,通过序列化组件保存----->必须继承自serializers.ModelSerializer),校验通过,默认不能为空 def post(self,request, *args, **kwargs): response = {'status':100,'msg':'新增成功'} book = request.data book_xlh=BookXlh(data=book) #其实data=request.data # 什么数据都没写,默认不能为空 ,但是长度啊什么的没有限制 # 提交的子弹通过校验 if book_xlh.is_valid(): book_xlh.save() response['book'] = book_xlh.data else: response['msg']=book_xlh.errors # return Response(book_xlh.data) return Response(response)
删
# 删除,查出来直接delete def delete(self,request,id): response = {'status': 100, 'msg': '删除成功了'} book = models.Book.objects.filter(pk=id).first().delete() return Response(response)
查就是获取
改
# 获取一本书的 class Book(APIView): def get(self, request, id): response = {'status': 100, 'msg': '成功了'} book = models.Book.objects.filter(pk=id).first() book_xlh = BookXlh(book, many=False) response['book'] = book_xlh.data return Response(response) # 修改书在book里面,put和putch请求都可以 def put(self,request,id): response = {'status': 100, 'msg': '成功了'} book = models.Book.objects.filter(pk=id).first() book_xlh = BookXlh(data=request.data,instance=book) if book_xlh.is_valid(): book_xlh.save() response['book'] = book_xlh.data else: response['msg']=book_xlh.errors return Response(response)
什么是跨域?
什么是幂等性?