前段时间接到一个公司关于解析pacp文件的培训(我是被培训的),在完成了一部分的功能后决定把一些关于pcap文件的了解记录到博客中。
初识Pcap文件
在开始读取pcap文件之前,先让我们来看看Pcap文件的大概结构。

如上图所示在一个Pcap文件中存在1个Pcap文件头和多个数据包,其中每个数据包都有自己的头和包内容。
下面我们先看看PCAP文件头每个字段是什么意思:
magic为文件识别头,pcap固定为:0xA1B2C3D4。(4个字节)
magor version为主版本号(2个字节)
minor version为次要版本号(2个字节)
timezone为当地的标准时间(4个字节)
sigflags为时间戳的精度(4个字节)
snaplen为最大的存储长度(4个字节)
linktype为链路类型(4个字节)
常用类型:
0 BSD loopback devices, except for later OpenBSD
1 Ethernet, and Linux loopback devices
6 802.5 Token Ring
7 ARCnet
8 SLIP
9 PPP
10 FDDI
100 LLC/SNAP-encapsulated ATM
101 “raw IP”, with no link
102 BSD/OS SLIP
103 BSD/OS PPP
104 Cisco HDLC
105 802.11
108 later OpenBSD loopback devices (with the AF_value in network byte order)
113 special Linux “cooked” capture
114 LocalTalk
1 Ethernet, and Linux loopback devices
6 802.5 Token Ring
7 ARCnet
8 SLIP
9 PPP
10 FDDI
100 LLC/SNAP-encapsulated ATM
101 “raw IP”, with no link
102 BSD/OS SLIP
103 BSD/OS PPP
104 Cisco HDLC
105 802.11
108 later OpenBSD loopback devices (with the AF_value in network byte order)
113 special Linux “cooked” capture
114 LocalTalk
们需要靠第一个Packet包确定。 最后,Packet数据部分的格式其实就是标准的网路协议格式了可以任何网络教材上找得到。
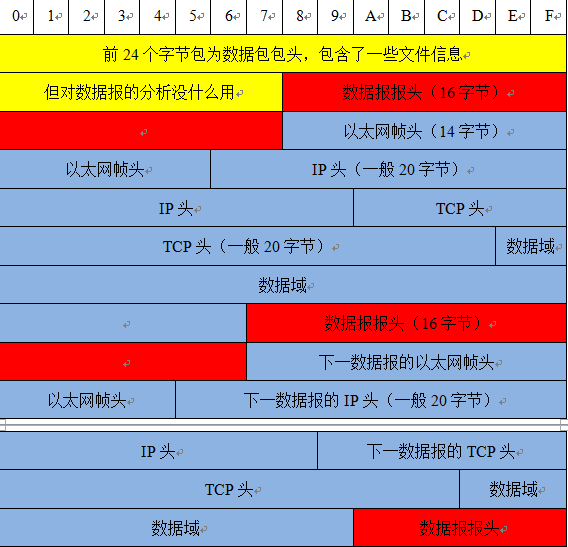
数据包头则依次为:时间戳(秒)、时间戳(微妙)、抓包长度和实际长度,依次各占4个字节。
解开文件包的 第一步代码 实现
#include<stdio.h> #include<memory.h> #include<stdlib.h> #include<math.h> /* #pragma pack(push) //保存对齐状态 #pragma pack(4)//设定为4字节对齐 相当于 #pragma pack (push,4) */ #pragma pack( push, 1) //1 字节对其方式 // 为了保证在windows和linux下都能正常编译,放弃使用INT64或者_int_64 //typedef short _Int16; //typedef long _Int32; typedef char Byte; // Pcap文件头 struct __file_header { int iMagic; short iMaVersion; short iMiVersion; int iTimezone; int iSigFlags; int iSnapLen; int iLinkType; }; // 数据包头 struct __pkthdr { int iTimeSecond; int iTimeSS; int iPLength; int iLength; }; #pragma pack( pop)// 回复对其方式 int main() { struct __pkthdr data; struct __file_header header; FILE* pFile = fopen( "sousuo.pcap", "rb"); if( pFile == 0) { printf( "打开pcap文件失败"); return 0; } fseek( pFile, 0, SEEK_END);//将文件指针定位到文件末尾 long iFileLen = ftell( pFile); //ftell 函数获得文件到大小 长度 fseek( pFile, 0, SEEK_SET);//将文件指针定位到文件到开头 Byte* pBuffer = (Byte*)malloc( iFileLen); fread( (void*)pBuffer, 1, iFileLen, pFile);//这样 效率 有点低啊 ! /*size_t fread( void *buffer, size_t size, size_t count, FILE *stream ) buffer 是读取的数据存放的内存的指针(可以是数组,也可以是新开辟的空间,buffer就是一个索引) size 是每次读取的字节数 count 是读取次数 strean 是要读取的文件的指针*/ fclose( pFile); memcpy( (void*)&header, (void*)(pBuffer) , sizeof(struct __file_header));//copy Pcap文件头到缓冲区 int iIndex = sizeof(struct __file_header); int iNo = 0; while(iIndex <= iFileLen) { memcpy( (void*)&data, (void*)(pBuffer + iIndex) , sizeof(struct __pkthdr));//copy 数据包头 到缓冲区 char strPath[51]; sprintf( strPath, "export%d-%d.pcap", iNo++, (int)data.iTimeSecond);//将数据包中 iTimeSecond 放到strPath中 strPath[50] = '�'; FILE* pwFile = fopen( strPath, "wb"); fwrite((void*)&header, 1, sizeof(struct __file_header), pwFile);// 将header中 Pcap文件头 写到 pwFile指向的文件处 fwrite( (void*)(pBuffer + iIndex), 1, sizeof(struct __pkthdr) + data.iPLength, pwFile);//将来 pkthder 后面的真正的数据写到文件中 fclose( pwFile);//最后每个文件的构成是 __file_header + __pkthdr.头部结束的data部分 看图会比较好 iIndex += sizeof(struct __pkthdr) + data.iPLength;//步长 } free( pBuffer); printf( "成功导出%d个文件", iNo - 1); return 1; }
下次 将 服务器上的 注释 更好的 代码 放上来 明天继续解析报文