逻辑回归(Logistic Regression),简称LR。它的特点是能够使我们的特征输入集合转化为0和1这两类的概率。一般来说,回归不用在分类问题上,因为回归是连续型模型,而且受噪声影响比较大。如果非要应用进了;来,可以使用逻辑回归。了解过线性回归之后再来看逻辑回归可以更好的理解。
Logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)将作为假设函数来预测。g(z)可以将连续值映射到0和1上。Logistic回归用来分类0/1问题,也就是预测结果属于0或者1的二值分类问题。
映射函数为:
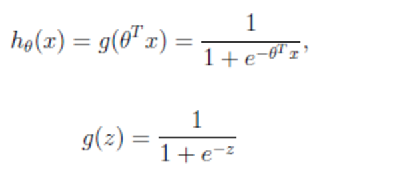
映射出来的效果如下如:
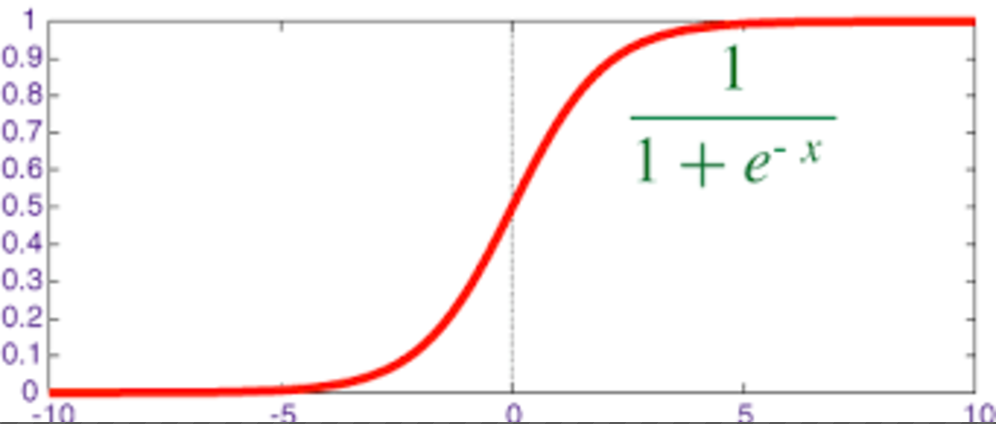
输出:[0,1]区间的概率值,默认0.5作为阀值
注:g(z)为sigmoid函数
逻辑回归的损失函数、优化
与线性回归原理相同,但由于是分类问题,损失函数不一样,只能通过梯度下降求解。
对数似然损失函数:
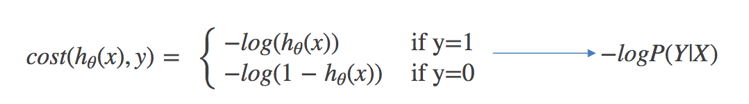
完整的损失函数:
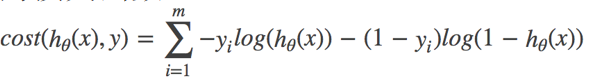
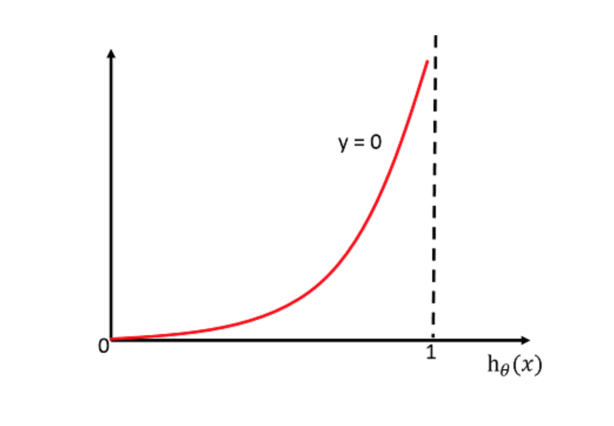
cost损失的值越小,那么预测的类别准确度更高
当y=1时:
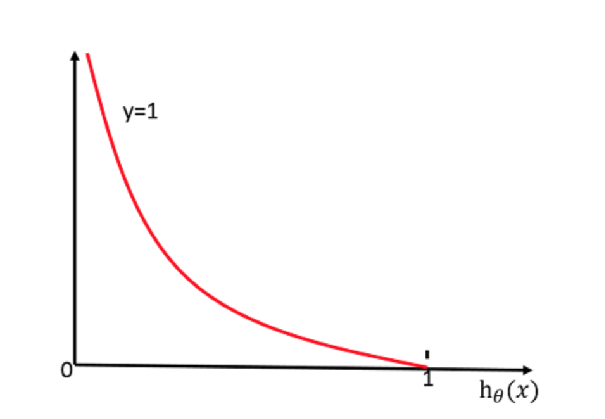
y=0时:
sklearn逻辑回归API
sklearn.linear_model.LogisticRegression(penalty=‘l2’, C = 1.0)
- Logistic回归分类器
- coef_:回归系数
良/恶性乳腺癌肿案例
原始数据的下载地址为:https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/
column = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin', 'Normal Nucleoli',
'Mitoses', 'Class']
# 读取数据
data = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",
names=column)
# print(data)
# 缺失值进行处理
data.replace(to_replace="?", value=np.nan, inplace=True)
data.dropna(inplace=True)
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(data[column[1:10]], data[column[10]])
# 标准化处理
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 逻辑回归预测
lg = LogisticRegression(C=1.0)
lg.fit(x_train, y_train)
print(lg.coef_)
y_predict = lg.predict(x_test)
print("准确率:", lg.score(x_test, y_test))
print("精准率和召回率:", classification_report(y_test, y_predict, labels=[2, 4], target_names=["良性", "恶性"]))
LogisticRegression总结
应用:广告点击率预测、电商购物搭配推荐
优点:适合需要得到一个分类概率的场景
缺点:当特征空间很大时,逻辑回归的性能不是很好(看硬件能力)