hdfs的读:
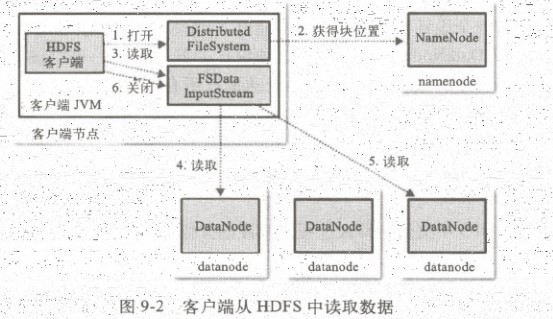
首先客户端通过调用fileSystem对象中的open()函数读取他需要的的数据,fileSystem是DistributedFileSystem的一个实例,
DistributedFileSystem会通过rpc协议和nameNode通信,来确定请求文件块所在的位置。对于每个返回的块都包含, 该块所在的dataNode的地址,然后这些返回的dataNode,会按照hadoop定义的集群拓扑结构得出dataNode与客户端的距离,然后进行排序。如果客户端本身就是一个dataNode,那么他将从本地读取文件
DistributedFileSystem会返回给客户端一个支持文件定位的输入流对象FSDataInputStream,这个对象有个子类DFSdataInputStream,这个对象管理nameNode和dataNode之间的io
当以上步骤完成后,DFSdataInputStream会调用父类DataInputStream的read()方法。DFSdataInputStream包含文件开始部分数据块的dataNode地址,他会先调用最近的块包含的dataNode节点,然后重复的调用read函数,直到这个块上的数据读取完毕。当最后一个块读取完后,DFSdataInputStream会关闭链接,并查找下一个距离客户端最近的包含块的dataNode
客户端按照DFSdataInputStream的打开和dataNode连接返回数据流的顺序读取该块,它也会调用nameNode检索下一组包含块的dataNode的位置,当所有的dataNode的块都读取完后,他会再调用FSDataInputSetream的close()函数
hdfs也考虑到读取节点失败的情况,他是这样处理的:如果客户端和所连接的dataNode出现故障的时候,他会读取下一个里客户端最近的一个dataNode,并记录上一个dataNode的失败信息,这样他就不会继续连接这个块,客户端还会验证从dataNode传过来的数据校验和,如果发现损坏的块,客户端将会寻找下一个块,向nameNode报告这个信息,nameNode将会保存更新这个文件
这里注意下:当客户单跟nameNode进行连接时,nameNode只是返回客户端请求包含块的dataNode地址,并不是返回请求块的数据,这样做好处是:可以使hdfs扩展到更大规模的客户端并行处理,这是因为数据的流动是在nameNode间分散进行处理,nameNode只返回dataNode的地址,同时也减轻了nameNode的压力,这样就避免了随着客户端的增加nameNode成了颈瓶
hdfs的写:
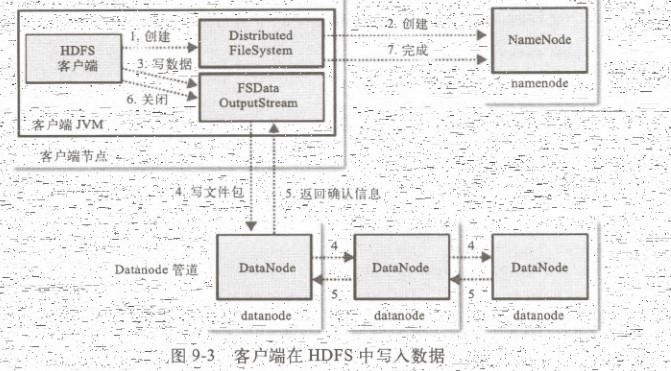
客户端会DistributedFileSystem对象的一个create()函数,这个对象会通过rpc协议与nameNode进链接,在nameNode的文件命名空间中创建一个新文件,这是的文件还未和dataNode进行关联
nameNode会通过多种验证判断新的文件不存在文件系统中,并且客户端拥有创建文件的权限,当所有校验都通过后,才会创建文件。失败就抛出一个ioException异常,成功就会返回一个支持文件定位的输出流FSDataOuputStream对象,这个对象包含了一个DFSdataOutputStream对象,这个对象是用来供客户端写入数据用的,客户端可以用他来处理nameNode和dataNode之间的通信
DFSDataOutputStrean会将文件分割成包,放入数据队列中,dataStream向nameNode请求这些新的文件包分配合适的dataNode