1、闭包: 保护数据安全、保护数据干净性。
2、闭包的定义:在嵌套函数内、使用非全局变量(且不使用本层变量)
将嵌套函数返回
闭包的目的:要接受被装饰的函数和被装饰函数需要的参数
3、闭包举例子:
def func():
a = 10
def foo():
print(a)
return foo
f = func()
f()
结果:10
4、验证闭包函数:__closure__
def func():
a = 10 #自由变量
def foo():
print(a) #打印a有一个绑定关系
return foo
f = func()
print(f.__closure__)
结果:(<cell at 0x0000000001E285E8: int object at 0x00000000525A8190>,)
5、函数体执行完以后将函数体开辟的空间都释放掉了
6、模拟买车求平均价版一:
lst = []
def buy_car(price):
lst.append(price)
arg = sum(lst) / len(lst)
print(arg)
buy_car(120000) #周一
buy_car(240000) #周二
buy_car(10000000) #周三
buy_car(5500000) #周四
buy_car(120000) #周五
buy_car(50000000) #周六
buy_car(5000000) #周日
结果: 120000.0
180000.0
3453333.3333333335
3965000.0
3196000.0
10996666.666666666
10140000.0
7、版二:查看闭包函数里面的自由变量__code__.co_freevars:
def buy_car():
lst = []
def func(price):
lst.append(price)
arg = sum(lst) / len(lst)
print(arg)
return func
f = buy_car()
print(f.__code__.co_freevars)
f(1)
f(2)
f(3)
f(4)
f(5)
结果:('lst',)
1.0
1.5
2.0
2.5
3.0
8、查看闭包函数里面的局部变量__code__.co_varnames:
def buy_car():
lst = []
def func(price):
lst.append(price)
arg = sum(lst) / len(lst)
print(arg)
return func
f = buy_car()
print(f.__code__.co_freevars)
print(f.__code__.co_varnames)
f(1)
f(2)
f(3)
f(4)
f(5)
结果:('lst',)
('price', 'arg')
1.0
1.5
2.0
2.5
3.0
9、没有将嵌套的函数返回也是一个闭包、但是这个闭包不是一个可使用的闭包:
def func():
a = 10
def foo():
print(a)
print(foo.__closure__)
func()
# 结果:(<cell at 0x00000000021785E8: int object at 0x00000000592F8190>,)
10、闭包就是需要打开两次而已:
11、以下也是一个闭包:
def wrapper(a,b):
#a = 1 #隐形传参/隐形定义变量和后续的隐形接收传参
#b = 2
def inner():
print(a)
print(b)
return inner
a = 2
b = 3
ret = wrapper(a,b)
print(ret.__closure__)
# 结果:(<cell at 0x0000000001E185E8: int object at 0x00000000592F8090>, <cell at 0x0000000001E18618: int object at 0x00000000592F80B0>)
12、闭包的应用场景:
1、装饰器
2、防止数据被误改动
装饰器的本质就是闭包
13、生成器的本质就是迭代器:
14、开放封闭原则:
1、对扩展开放--支持增加新功能
2、对修改源代码是封闭,对调用方式是封闭的
15、装饰(在原有的基础上额外添加功能)器--工具:
16、装饰器运行图:
17、语法糖:语法糖必须放在被装饰的函数正上方
语法糖的本质就是index = run_time(index)
函数名可以当做另一个函数参数
函数名可以当做另一个函数的返回值
函数名可以当做值赋值给变量
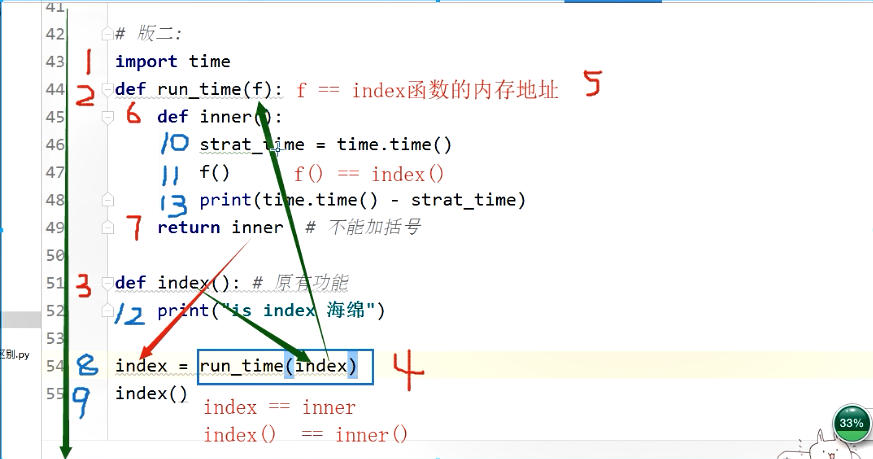
import time
def run_time(f):
def inner():
start_time = time.time() #被装饰函数之前
f()
print(time.time() - start_time) #被装饰函数之后
return inner
@run_time
def index():
print("is index 海绵")
index()
18、有参装饰器:
import time
def run_time(f): #f接收的是被装饰的函数名
def inner(*args,**kwargs): #被装饰的函数需要的参数
print("外挂开启")
f(*args,**kwargs)
print("外挂关闭")
return inner
@run_time
def index(user,pwd,hero):
print("打开游戏")
print(f"登录{user}和{pwd}")
print(f"选择英雄:{hero}")
print("游戏中")
print("游戏结束")
index("meet","123456","草丛伦")
19、有参装饰器有返回值时:
def run_time(f): #f接收的是被装饰的函数名
def inner(*args,**kwargs): #被装饰的函数需要的参数
print("外挂开启")
ret = f(*args,**kwargs)
print("外挂关闭")
return ret
return inner
@run_time
def index(user,pwd,hero):
print("打开游戏")
print(f"登录{user}和{pwd}")
print(f"选择英雄:{hero}")
print("游戏中")
return "游戏结束"
print(index("meet","123456","草丛伦"))
20、标准版装饰器:
def wrapper(func):
def inner(*args,**kwargs):
"""执行被装饰函数前的操作"""
func(*args,**kwargs)
"""执行被装饰函数后的操作"""
return inner
@wrapper
def index():
print("is index")
index()
21、将来有可能会问:
语法糖要接受的变量就是语法糖下面的函数名、参数就是语法糖下面的函数名、调用的方式就是看调用的哪个语法糖
def func(args):
print("新加了一个功能")
return args
@func #index = func(index)
def index():
print(2)
index()
结果: 新加了一个功能
2
22、作业题:
# 1、用内置函数或者和匿名函数结合做出
# 2、用map来处理下述l,然后用list得到一个新的列表,列表中每个人的名字都是sb结尾
l=[{'name':'alex'},{'name':'y'}]
print(list(map(lambda x:x["name"] + "sb",l)))
# 3、用filter来处理,得到股票价格大于20的股票名字
# shares={
# 'IBM':36.6,
# 'Lenovo':23.2,
# 'oldboy':21.2,
# 'ocean':10.2,
# }
# print(list(filter(lambda i:shares[i] > 20,shares)))
# 4、有下面字典,得到购买每只股票的总价格,并放在一个迭代器中。
# 结果:list一下[9110.0, 27161.0,......]
# portfolio = [
# {'name': 'IBM', 'shares': 100, 'price': 91.1},
# {'name': 'AAPL', 'shares': 50, 'price': 543.22},
# {'name': 'FB', 'shares': 200, 'price': 21.09},
# {'name': 'HPQ', 'shares': 35, 'price': 31.75},
# {'name': 'YHOO', 'shares': 45, 'price': 16.35},
# {'name': 'ACME', 'shares': 75, 'price': 115.65}]
print(list(map(lambda i:i["shares"] * i["price"],portfolio)))
# 5、还是上面的字典,用filter过滤出单价大于100的股票。
print(list(filter(lambda x:x["price"] > 100,portfolio)))
# 6、有下列三种数据类型,
# l1 = [1,2,3,4,5,6]
# l2 = ['oldboy','alex','wusir','太白','日天']
# tu = ('**','***','****','*******')
# 写代码,最终得到的是(每个元祖第一个元素>2,第三个*至少是4个。)
# [(3, 'wusir', '****'), (4, '太白', '*******')]
# 7、有如下数据类型(实战题):
# l1 = [{'sales_volumn': 0},
# {'sales_volumn': 108},
# {'sales_volumn': 337},
# {'sales_volumn': 475},
# {'sales_volumn': 396},
# {'sales_volumn': 172},
# {'sales_volumn': 9},
# {'sales_volumn': 58},
# {'sales_volumn': 272},
# {'sales_volumn': 456},
# {'sales_volumn': 440},
# {'sales_volumn': 239}]
# 将l1按照列表中的每个字典的values大小进行排序,形成一个新的列表。
print(sorted(l1,key=lambda x:x["sales_volumn"]))
# 8、有如下数据结构,通过过滤掉年龄大于16岁的字典
# lst = [{'id':1,'name':'alex','age':18},
# {'id':1,'name':'wusir','age':17},
# {'id':1,'name':'taibai','age':16},]
print(list(filter(lambda x:x["age"] > 16,lst)))
# 9、有如下列表,按照元素的长度进行升序
# lst = ['天龙八部','西游记','红楼梦','三国演义']
print(sorted(lst,key = len))
# 10、有如下数据,按照元素的年龄进行升序
# lst = [{'id':1,'name':'alex','age':18},
# {'id':2,'name':'wusir','age':17},
# {'id':3,'name':'taibai','age':16},]
print(sorted(lst,key=lambda x:x["age"]))
# 11、看代码叙说,两种方式的区别
# lst = [1,2,3,5,9,12,4]
# lst.reverse() #原地修改
# print(lst)
# print(list(reversed(lst))) #新开辟了一个列表
# 12、求结果(面试题)
# v = [lambda :x for x in range(10)] #首先这个一整体是列表推导式
# print(v)
#结果是10个函数的内存地址:[<function <listcomp>.<lambda> at 0x000000000221AB70>, <function <listcomp>.<lambda> at 0x000000000221AA60>, <function <listcomp>.<lambda> at 0x000000000221AC80>, <function <listcomp>.<lambda> at 0x000000000221ABF8>, <function <listcomp>.<lambda> at 0x000000000221AD08>, <function <listcomp>.<lambda> at 0x000000000221AD90>, <function <listcomp>.<lambda> at 0x000000000221AE18>, <function <listcomp>.<lambda> at 0x000000000221AEA0>, <function <listcomp>.<lambda> at 0x000000000221AF28>, <function <listcomp>.<lambda> at 0x0000000002223048>]
# print(v[0])
#从10个函数内存地址里面拿到第一个函数的内存地址:[<function <listcomp>.<lambda> at 0x000000000221AB70>
# print(v[0]()) #第一个函数的内存地址加括号运行不用加参数、因为lambda函数里面没有形参、x是for循环的最后一个数9
# 13、求结果(面试题)
# v = (lambda :x for x in range(10))
# print(v) #生成器的内存地址
# print(v[0]) #报错生成器对象不可订阅
# print(v[0]()) #报错生成器对象不可订阅
# print(next(v)) #函数的内存地址
# print(next(v)()) #运行结果是1
# 14、map(str,[1,2,3,4,5,6,7,8,9])输出是什么? (面试题)
#结果:<map object at 0x00000000021C77B8> #
# 15、有一个数组[34,1,2,5,6,6,5,4,3,3]请写一个函数,找出该数组中没有重复的数的总和(上面数据没有重复的总和为1+2+34=40)(面试题)
#for循环写法:
lst = [34,1,2,5,6,6,5,4,3,3]
num = 0
for i in lst:
if lst.count(i) == 1:
num += i
print(num)
#sum求和:
print(sum([x for x in lst if lst.count(x) == 1]))
#filter过滤:
print(sum(list(filter(lambda x:lst.count(x) == 1,lst))))
# 16、求结果:(面试题)
# def num():
# return [lambda x:x**i for i in range(4)]
# print([m(2)for m in num()])
# 结果:[8, 8, 8, 8]
# 17、看代码写结果:
# def wrapper(f):
# def inner(*args, **kwargs):
# print(111)
# ret = f(*args, **kwargs)
# print(222)
# return ret
# return inner
# def func():
# print(333)
# print(444)
# func()
# print(555)
# 18、编写装饰器, 在每次执行被装饰函数之前打印一句’每次执行被装饰函数之前都得先经过这里’。
def wrapper(f):
def innder(*args,**kwargs):
print("每次执行被装饰函数之前都得先经过这里")
ret = f(*args,**kwargs)
print("嘿嘿嘿")
return innder
@wrapper #func = wrapper(func)
def func():
print("i am name 张达")
func()
# 19、为函数写一个装饰器,把函数的返回值 + 100然后再返回。
def wrapper(func):
def inner(*args,**kwargs):
return func(*args,**kwargs) + 100
return inner
@wrapper
def func():
return 7
result = func()
print(result)
# 23、请实现一个装饰器,每次调用函数时,将被装饰的函数名以及调用被装饰函数的时间节点写入文件中。可用代码如下:
def wrapper(func):
def inner(*args,**kwargs):
import time
struct_time = time.localtime()
time_str = time.strftime("%Y-%m-%d %H:%M:%S",struct_time) #获取当前时间节点
with open("info","a",encoding="utf-8") as f:
f.write(f"时间:{time_str} 函数名:{func.__name__} ")
func(*args,**kwargs)
print("写入成功!")
return inner
@wrapper
def func():
print(func.__name__) #现在看到的func已经是inner了
print("我被执行了")
func()
# inner
# 我被执行了
# 写入成功!