Kafka 系列
Kafka从0.9版本开始,Kafka的标语已经从一个“高吞吐量,分布式的消息系统”更改为了“一个分布式的流平台”;
注:不要小看标语的改变,标语的改变其实意味着很多。
流式数据平台所需要具备的特点
-
消息系统
消息系统下有两种消息模式,分别是“队列和发布订阅”两种模式;-
队列模式
队列模式,数据会平均的推送给消费组中的消费成员,多个消费者读取消息队列,每条消息只发送给一个消费者;
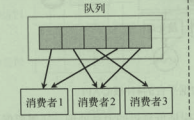
如上述一个消息队列中有6条数据(0,1,2,3,4,5)一个消费组中有三个消费者,那么此时队列中数据会平均的分配给每个消费者,及:1消费者消费队列0数据,2消费者消费队列1数据,3消费者消费队列2数据;然后1消费者再消费队列3数据,2消费者再消费4队列数据,以此类推; 队列模式的坏处是:队列中的数据不能够被重复消费,队列中的1号数据被消费者消费以后,就不能再有其他消费者重复消费该1号数据了,所以如果有其他的消费组想要重复的再消费队列中的0-5的数据,则不能够再重复消费,这个弊端也就导致了大部分情况下都是使用的发布/订阅的消费模型;但是队列模式的好处是:线性扩展消息的处理能力较强,一个队列中的数据可以平均分摊给多个消费者处理,对于系统的消费速度则有较大的提升
-
发布订阅模式
多个消费者订阅主题,主题的每条记录,会发送给所有的消费者;
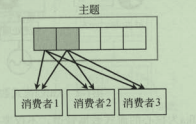
-
-
存储系统
- 任何消息队列要做到“发布消息”和“消费信息”的接耦合,就必须要扮演一个存储系统的角色,将还没有被消费的信息进行保存,否则,如果消息只存在于内存中,则机器宕机或进程重启则内存中数据便会丢失;
-
流处理系统
- 流式处理平台除了要具备消息的读取和写入,还需要具备实时的流式数据的处理能力,对于复杂的业务逻辑处理,采用流处理的方式来实现聚合,链接,以及各种转换操作等将会方便很多;
Kafka
上述说明了流式数据平台所需要的具备的特点,那么Kafka作为一个流式的数据平台,则都具备了上述的那些特征?
- 消费模式 :
- kafka中使用发布/订阅模式时,它可以将消息广播到多个消费组,采用多个消费组结合多个消费者的模式,则可以线性的扩展消息的处理能力,也允许了消息被多个消费组同时订阅;(简单理解则是:kafka中采用消息组的方式,及做到了队列模式的线性消息的扩展能力,也做到了发布/订阅模式中,同一条消息被多个消费组同时订阅消息的能力)
- 存储系统:
- kafka中数据写入到kafka集群的服务器节点时,还将会被复制多份来保证集群出现故障时仍然可用,为了保证可用性,kafka还允许生产者的生产请求在收到应答结果之前,阻塞式的等待一条消息,直到当前消息被完全的复制到多个节点上后,才认为这条消息写入成功;
- 流处理平台:
- kafka streams 为开发者提供了完成的流处理API,并且kafka内部解决了很多流处理应用程序将会面临的问题:处理乱序或迟来的数据,重新处理输入数据,窗口和状态操作等;
kafka的核心API
- 生产者(producer):应用程序发布事件流到kafka的一个或多个主题
- 消费者(consumer):应用程序订阅kafka的一个或多个主题,并处理事件流
- 连接器(connector):将kafka主题和已有的数据源进行连接,数据可以互相导入和导出;
- 流处理(processor):从Kafka主题中消费输入流,经过处理后,产生输出流到输出主题;
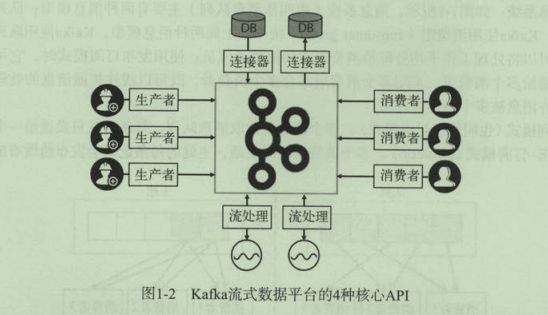
了解了上述的流式处理平台的基本功能和概念后,那么Kafka是如何实现一个“流失处理平台的”?向下看
kafka基本概念
注意,以下是kafka的基本概念,与上述的流式处理平台的概念,则更像是具体实现的关系,kafka中是通过什么样的方式,来实现了上述的流式处理平台的概念的?kafka中的消息是存储到哪里的?kafka中的一组消息是如何平均的分配到消费者中的?等等
分区模型
Kafka的集群是由多个消息代理服务器(broker server)组成,发送到kafka集群的每条消息都会有一个类别的概念,在kafka中用主题(topic)来表示;一个topic相当于一个类别的消息,或者是相当于一组的消息;所以不同应用产生的不同类型的数据,可以设置不同的主题topic,而一个主题一般则都会有多个订阅者(消费者),当生产者发布消息到某个主题时,订阅这个主题的消费者则可以接收到生产者所写入的数据;
kafka中的一组消息是如何存储的?
上述说到了,kafka中的一组消息就是一个主题(topic),那么kafka中的一组消息是如何存储的?这里则是涉及到一个分区(partition)的概念;
kafka集群中为主题都维护了分布式的分区(partition)日志文件(是的,物理意义上就可以直接理解为一个日志文件),每个分区日志文件,都是一个有序的,不可变的记录序列,新的消息会不断的追加到该分区日志中;分区中的每条消息都会按照时间顺序分配到一个递增的顺序编号,kafka中叫做偏移量(offset),这个偏移量就能够唯一的定位到当前分区中的每一条消息了;

如上图所示,每个分区中的偏移量都是从0开始,互相独立,互不影响的,比如我们向一个主题中,生产了一组数据,如果当前生产的一组数据时,没有设置对应的消息的键值,而是只有Message内容,那么此时消息则会均匀的按顺序的分布到不同的分区上,,比如0,1,2三条数据,则会均匀的落入到3个分区文件中,对应的偏移量则也分别是,p0,和p1以及p2分区的偏移量为0的顺序编号;
Kafka的生产者和消费者相对于服务端来说都是客户端,生产者发送消息到服务端的指定主题时有两种确认分区的方式,一种是生产者在生产数据的时候直接指定具体的主题和分区,另外一种则是由kafka服务端自行执行分区策略,根据生产者发布消息时是否有键,来采用不同的分区策略,消息没有键时,则采用轮训的方式对客户端进行负载均衡(及按照轮训的方式将消息按顺序存储到不同分区中),如果消息有键时,根据分区语义来确保相同键的消息,总是被发送分配到同一个分区中;
kafka中采用分区的方式来存储消息的好处是大大的,,,kafka以分区作为最小的粒度,将每个分区分配给消费组中不同的而且是唯一的消费者,并确保一个分区只属于一个消费组中的消费者,即这个消费者就是分区的唯一读取线程,那么,只要分区的消息是有序的,消费者处理的消费顺序就有保证。每个主题有多个分区,不同的消费者消费不同的分区,所以kafka采用分区的这种方式,不但保证了消息的有序性,也做到了消费者的负载均衡;
讨论一下:如果想要使用Kafka保证更好的并发的消费有序的数据,有哪几种采用方式?
假设,每秒需要从主题写入和读取1GB的数据,那么有哪些好的方式?
分区是kafka中的最小单元,一般情况下,对生产者而言,每一个分区的写入是完全可以并行化写入的,kafka生产数据时是可以指定对应的分区的,所以单独开4个线程,每个线程向同一个主题的不同的分区进行写入即可,也就是说,生产者的吞吐量和并行化则是相对更好做到的。
- 生产者一般效率都是较高的,如果生产者向一个主题中写入数据时可以到每秒1GB的吞吐,但是一个消费者每秒只能做到50MB的吞吐量,那么至少需要给当前主题分配20个分区,20个消费者同时消费20个分区,以此达到写入和消费都可以做到每秒1GB的吞吐量
- 分区数量并不是越多越好,维护一个主题下的越多的分区,相比于kafka也是有维护成本的,且主分区的选举也就会浪费更长的时间,所以,另外一种方式则是拆分主题,并不见得说生产者生产这批数据时只能生产到一个主题的20分区中,也可以通过生产到2个主题,各10个分区的来进行拆解,以此来保证更好的吞吐量,消费者消费的时候,直接消费两个主题也是OK的;
可参考文章:
kafka指定分区生产数据和消费数据的方式:
https://blog.csdn.net/
https://blog.csdn.net/u012386386/
生产数据时指定分区的方式是:定义一个 Partitions类 implements Partitioner,然后生产者配置参数中指定该类的路径即可:
props.put("partitioner.class","com.a.p.Partitions");
可参考文章: