GAN_李弘毅讲解:

上式中,xi从data中sample的一部分,现在的目的就是最大化 这个似然函数,使得Generator最可能产生data中的这些sample;
这个似然函数,使得Generator最可能产生data中的这些sample;


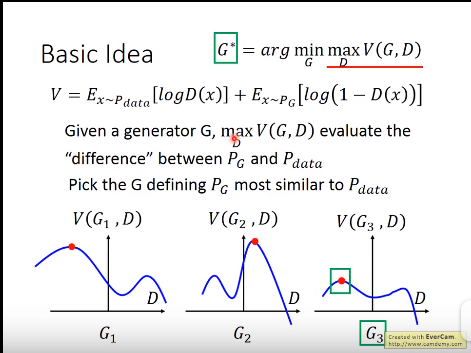
上式中之所以如此设计V函数,是为了后面与KL以及cross entropy结合起来;

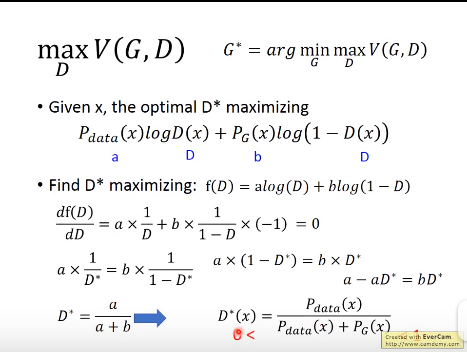
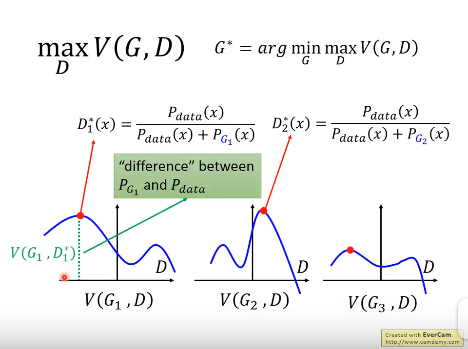


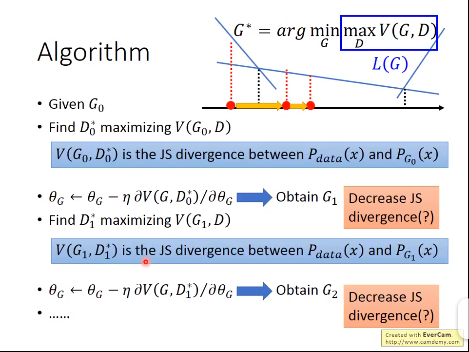
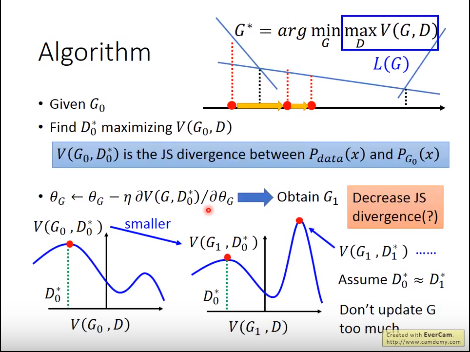
问题一:上图存在的一个问题:G迭代的过多造成G1下的D*得到的两种数据的分布差异更大了;




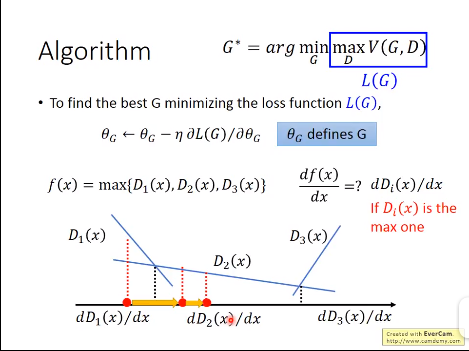
使用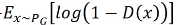 优化在前期的话由于梯度较小,学习较慢,所以改为了下面那种形式;
优化在前期的话由于梯度较小,学习较慢,所以改为了下面那种形式;


问题二:由于采用JSD距离,可以发现当data与G产生的数据没有重叠时,两者的距离始终为log2,当两者离得更近时依然如此,这样子当train的时候Loss不变就没有动力进行训练;下面有一种改善方法:

如上所示:加入噪声,使得两个分布之间有overlap,使得可以产生JSD进行训练,同时保证Loss随着训练不断下降;
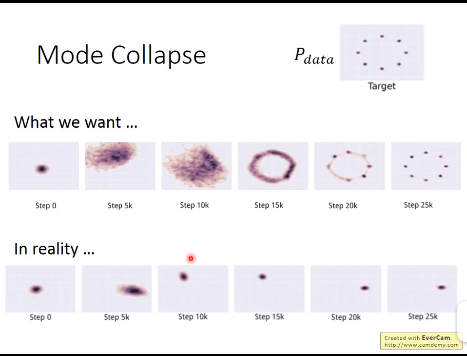
问题三:G产生的数据与data之间形成了一种“猫捉老鼠“的游戏,下图是一种解决方式,暂时还没看懂;
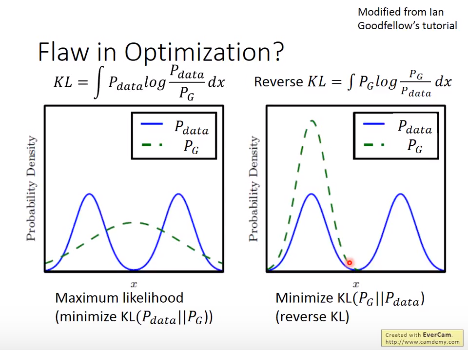
GAN的一些发展:
