hash code的原因只有一个:效率。理论的说法它的复杂度只有O(1)。试想我们把元素放在线性表里面,每次要找一个元素必须从头一个一个的找它的复杂度有O(n)。如果放在平衡二叉树,复杂度也有O(log n)。
为啥很多地方说“覆写equals的时候一定要覆写hashCode”。说到这里我知道很多人知道有个原则:如果a.equals(b)那么要确保
a.hashCode()==b.hashCode()。为什么?hashCode和我写的程序的业务逻辑毫无关系,为啥我要override?
要我说如果你的class永远不可能放在hash code为基础的容器内,不必劳神,您真的不必override hashCode() :)
说得准确一点放在HashMap和Hashtable里面如果是作为value而不是作为key的话也是不必override
hashCode了。至于HashSet,实际上它只是忽略value的HashMap,每次HashSet.add(o)其实就是
HashMap.put(o, dummyObject)。
那为什么放到Hash容器里面要overide hashCode呢?因为每次get的时候HashMap既要看equals是不是true也要看hash code是不是一致,put的时候也是要看equals和hash code。
如果说到这里您还是不太明白,咱就举个例子:
譬如把一个自己定义的class
Foo{...}作为key放到HashMap。实际上HashMap也是把数据存在一个数组里面,所以在put函数里面,HashMap会调
Foo.hashCode()算出作为这个元素在数组里面的下标,然后把key和value封装成一个对象放到数组。等一下,万一2个对象算出来的
hash
code一样怎么办?会不会冲掉?先回答第2个问题,会不会冲掉就要看Foo.equals()了,如果equals()也是true那就要冲掉了。万一
是false,就是所谓的collision了。当2个元素hashCode一样但是equals为false的时候,那个HashMap里面的数组的这
个元素就变成了链表。也就是hash code一样的元素在一个链表里面,链表的头在那个数组里面。
回过来说get的时候,HashMap也先调key.hashCode()算出数组下标,然后看equals如果是true就是找到了,所以就涉及了equals。
假设如果有个key为a的元素在HashMap里面的情况:
1:如果这时候用equals为true但是hashCode不等的b作为get参数的话,这个时候b算出来的数组下标一定不是a所在的下标位置。
2:如果这时候用equals为false但是hashCode相等的b作为get参数的话,这个时候b算出来的数组下标是对了,但是用equals来寻找相符的key就找不到a了。
以上2种情况要么就是get找不到符合的元素返回null,要么就是返回一个hashCode和equals恰好都符合b的另外的元素,这就产生了混乱。混乱的根本就是错误实现hashCode和equals。
.NET程序员都知道,如果我们重写一个类的Equals方法而没有重写GetHashCode,则VS会提示警告 :“***”重写 Object.Equals(object o)但不重写 Object.GetHashCode() 。
但是,为什么重写Equals一定要同时重写GetHashCode呢?
微软的解释是:
GetHashCode 基于适合哈希算法和诸如哈希表的数据结构的当前实例返回一个值。 两个相等的同类型对象必须返回相同的哈希代码,才能确保以下类型的实例正确运行:
-
HashTable
-
Dictionary
-
SortDictionary
-
SortList
-
HybredDictionary
-
实现 IEqualityComparer 的类型
链接:http://msdn.microsoft.com/zh-cn/library/vstudio/ms182358.aspx
举个例子:
重写一个Person类

public class Person { public int Id { get; set; } public string Name { get; set; } public int Age { get; set; } /// <summary> /// 重写Equals,如果Name与Age相等,就认为类相等 /// </summary> /// <param name="obj"></param> /// <returns></returns> public override bool Equals(object obj) { if (obj == null) return false; if (obj is Person) { var person = obj as Person; return person.Age == this.Age && person.Name == this.Name; } else return false; } }
写一个测试方法:
public static void Main(string[] args) { Person person1 = new Person() { Id = 1, Name = "AA", Age = 21 }; Person person2 = new Person() { Id = 2, Name = "AA", Age = 21 }; Console.WriteLine("person1与person2是否相等:" + person1.Equals(person2)); Console.Read(); }
结果:
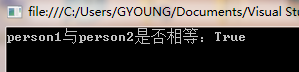
返回的结果是true,这好像是我们的重写方法成功了。那我们继续写一个测试方法吧。
ICollection<Person> list = new HashSet<Person>(); list.Add(person1); Console.WriteLine("List是否包含person1:"+list.Contains(person1)); Console.WriteLine("List是否包含person2:" + list.Contains(person2));
结果:

这时,就出问题了。既然person1与person2相等,list它包含person1,那也应该包含person2吧。原因就是我们没有重写GetHashCode方法,相同的对象没有返回相等的HashCode。
我们重新改变一下Person,让它重写GetHashCode方法。
public class Person { public int Id { get; set; } public string Name { get; set; } public int Age { get; set; } /// <summary> /// 重写Equals,如果Name与Age相等,就认为类相等 /// </summary> /// <param name="obj"></param> /// <returns></returns> public override bool Equals(object obj) { if (obj == null) return false; if (obj is Person) { var person = obj as Person; return person.Age == this.Age && person.Name == this.Name; } else return false; } public override int GetHashCode() { return this.Name.GetHashCode()^this.Age.GetHashCode(); } }
再运行两个测试方法:
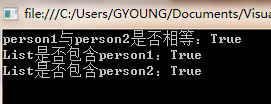
现在,方法都返回true了。
还有一个例子,如果将Person类当作键值放在字典中也会有问题,可以参见:http://book.51cto.com/art/201109/292340.htm。
重写GetHashCode的原则很简单,只要能保证两个相等的同类型对象返回相同的哈希代码就OK了。
还找到一个说得比较好的地方,里面第二个评论很精彩。http://blog.csdn.net/chenyuxu0/article/details/5886771