对于join buffer实现,于是做了以下实验:

从sql的执行计划中我们可以看到mysql使用using join buffer算法来优化改sql的查询,那么他的原理是什么?又是怎么样来实现的?在sql中注意到我加了hint提示符straight_join让,强制mysql按照查询中出现的顺序来连接表,意思是让t1表作为驱动表,t1中有多少记录,那么就要对t2表关联多少次(由于t2表为为我们子查询中的结果集,mysql在处理子查询的时候,把他子查询的结果放到临时表中,把临时表当做普通通进行处理,也就是执行计划中出现derived2,注意这里的临时表不在有id的索引了);
那么t2表就被多次的扫描,如果t2表的结果集非常的大,那么就会造成性能上的问题,所以mysql在这里对其进行了优化,采用Block Nested-Loop Join (BNL),具体算法描述为:
for each row in t1 matching range {
for each row in t2 matching reference key {
store used columns from t1, t2 in join buffer if buffer is full {
flush_buffer();
}
empty buffer
}
}
flush_buffer() {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
}
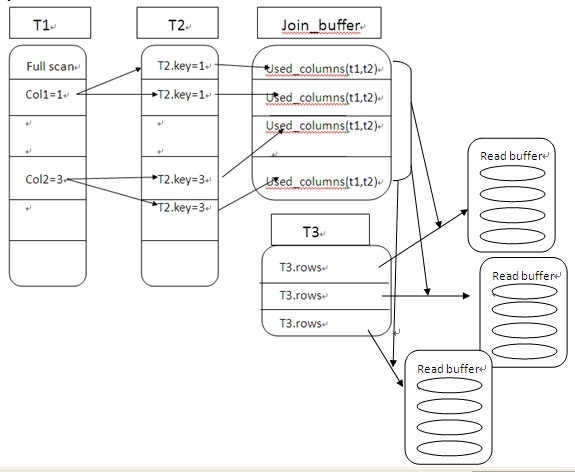
从图中可以看到把t1和t2的结果集放到join buffer中,而不用每次t1和t2关联后马上有和t3关联,这也是没有必要的,然后只需一次扫描t3即可完成这个查询;需要注意的是join buffer中只保留查询结果中出现的列值,它的大小不依赖于表的大小,我们在伪代码中看到当join buffer被填满后,mysql将会flush buffer。
注意:Join Buffer 只有当我们的 Join 类型为 ALL(如示例中),index,rang 或者是 index_merge 的时候 才能够使用