首先,在网上找的信息说PHP代码执行的顺序是这样的,第一步是词法分析,第二步是语法分析,第三步是转化为opcode,第四部也就是顺序执行这些opcode了。
聪明如各位看到这里,再返回上面看一下这张图片,肯定就会有不一样的感觉了。咱们借用一句话来阐述这几个步骤:当PHP拿到一段代码后,经过词法解析、语法解析等阶段后,源程序会被翻译成一个个指令(opcodes),然后ZEND虚拟机顺次执行这些指令完成操作。
我们都知道,PHP本身是用C实现的,因此最终调用的也是C的函数,实际上,我们可以把PHP看做一个C开发的软件。既然如此,那么PHP的代码执行的核心也就是翻译出来的一条一条指令,在这里就是opcode。
那么,我们就可以把opcode看成是PHP代码执行的最基本单位。所以PHP代码执行的本质也就可以理解为,我们的代码最终被翻译为一组opcode处理函数,完事之后再顺序执行。
有了这些认知之后,我们就来看下这个opcode究竟是什么鬼。本质上一个opcode由两个参数(op1,op2)、返回值和处理函数组成。它的官方解释就是PHP脚本编译后的中间语言,类似于java中的bytecode或者是.net中的MSL。
它的作用就是如下:
1、编译原理的中间过程会产生一种中间代码(语言),PHP由Zend引擎(C语言编写)编译后的中间代码为Opcode然后再交由Zend引擎处理,如同C语言编译后汇编代码然后再交由汇编。
2、生成的Opcode作为一种中间语言,可以帮助实现PHP源程序代码的不开源,如果你不想别人知道你的PHP代码是怎么写的,那你可以直接使用APC截取生成Opcode缓存文件,然后使用自己的PHP扩展加密程序对Opcode文件进行加密和解密,在Zend引擎对Opcode进行解析前进行解密然后再执行。
1、php-fpm 是如何处理web请求的?有什么问题?
我们用的 PHP 主要用于 web 开发,通过 nginx、apache 等服务端程序调用 php-fpm 处理服务端的业务逻辑,处理完后 php 撤消内存并返回结果。一个 web 请求就要加载一次 php 的全部文件,需要的系统资源开销很大,这是目前 php-fpm 的缺点之一;并且因为 php-fpm 在一次请求结束就释放内存,无法做连接池,也不合适 service 端的开发。我们用的 PHP 主要用于 web 开发,通过 nginx、apache 等服务端程序调用 php-fpm 处理服务端的业务逻辑,处理完后 php 撤消内存并返回结果。一个 web 请求就要加载一次 php 的全部文件,需要的系统资源开销很大,这是目前 php-fpm 的缺点之一;并且因为 php-fpm 在一次请求结束就释放内存,无法做连接池,也不合适 service 端的开发。
下面是 php-fpm 的运行流程,各位可以参考一下:
1 http://www.test.cc 2 | 3 Nginx 4 | 5 路由到 http://www.test.cc/index.php 6 | 7 加载nginx的fast-cgi模块 8 | 9 fast-cgi监听127.0.0.1:9000地址 10 | 11 www.test.com/index.php请求到达127.0.0.1:9000 12 | 13 php-fpm 监听127.0.0.1:9000 14 | 15 php-fpm 接收到请求,启用worker进程处理请求 16 | 17 php-fpm 处理完请求并撤消内存,返回给nginx 18 | 19 nginx 将结果通过http返回给浏览器
2.swoole是如何解决php-fpm遇到的问题的?
swoole如何避免文件的反复加载:
swoole是完全的长驻内存的,长驻内存一个最大的好处就是可以性能加速。在fpm模式下,我们处理一个请求,通常会有一些空消耗,比如框架共用文件加载,配置文件加载,那么在swoole中,可以在onworkerstart的时候提前一次性把一些必要的文件和配置加载好,不必每次receive重复加载一遍,这样能提升不小的性能。
常驻内存
常驻内存。传统 PHP框架或者单文件,在处理每个请求之前,都要做一遍加载框架文件、配置的操作,请求完成之后会释放所有资源和内存,无须担心内存泄漏。但是如果请求数量上升,并发很高的时候,快速创建资源,又马上释放,会导致 PHP 程序运行效率急剧下降。而使用 Swoole 则没有这个问题:PHP的代码加载到内存后,拥有更长的生命周期,这样建立的数据库连接和其他大的对象,不被释放。每次请求只需要处理很少的代码,而这些代码只在第一次运行时,被 PHP 解析器编译,驻留内存。以后都是直接载入 OPCODE ,让 Zend 引擎直接运行。另外,之前PHP不能实现的,如数据库连接池,缓存连接池都可以在Swoole引擎下实现。系统的运行效率会大大提高。
swoole如何实现高并发
1 请求到达 Main Reactor 2 | 3 Main Reactor 根据 Reactor 的情况,将请求注册给对应的 Reactor 4 (每个 Reactor 都有 epoll,用来监听客户端的变化) 5 | 6 客户端有变化时,交给 worker 来处理 7 | 8 worker 处理完毕,通过进程间通信(比如管道、共享内存、消息队列)发给对应的 reactor 9 | 10 reactor 将响应结果发给相应的连接 11 | 12 请求处理完成
因为reactor基于epoll,所以每个reactor可以处理很多个连接请求。 如此,swoole就轻松的处理了高并发。
swoole如何实现异步I/O
swoole的worker进程有2种类型:一种是普通的worker进程,一种是task worker进程。
worker进程是用来处理普通的耗时不是太长的请求;task worker进程用来处理耗时较长的请求,比如数据库的I/O操作。
我们以异步Mysql举例:
1 耗时较长的Mysql查询进入worker 2 | 3 worker通过管道将这个请求交给taskworker来处理 4 | 5 worker再去处理其他请求 6 | 7 task worker处理完毕后,处理结果通过管道返回给worker 8 | 9 worker 将结果返回给reactor 10 | 11 reactor将结果返回给请求方
如此,通过worker、task worker结合的方式,我们就实现了异步I/O。
总结一下 swoole 的技术特点:
1 常驻内存,避免重复加载带来的性能损耗,提升海量性能; 2 基于epoll,轻松支持高并发; 3 协程异步I/O,提高对I/O密集型场景并发处理能力; 4 支持多种通信协议,方便地开发 Http、WebSocket、TCP、UDP 等应用
3.swoole与php-fpm对比有哪些优缺点?
优点
1 常驻内存的 cli 运行模式,不用每次请求加载一次项目代码 2 大大提高了对连接请求的并发能力 3 协程异步I/O,提高对I/O密集型场景并发处理能力 4 支持多种通信协议,能搭建 TCP/UDP/UnixSocket 服务器 5 原生支持毫秒定时器
缺点
1 相关文档较少 2 不支持 xdebug,不支持手动 dump,不熟悉相关工具的话,不太方便调试 3 入门难度高,多数 phper 不了解 TCP/IP 网络协议、多进程 / 多线程、异步 io 等
3.进程的基本知识
对于一个进程来说,它的核心内容分为两个部分,一个是它的内存,这个内存是这进程创建之初从系统分配的,它所有创建的变量都会存储在这一片内存环境当中
一个是它的上下文环境我们知道进程是运行在操作系统的,那么对于程序来说,它的运行依赖操作系统分配给它的资源,操作系统的一些状态。
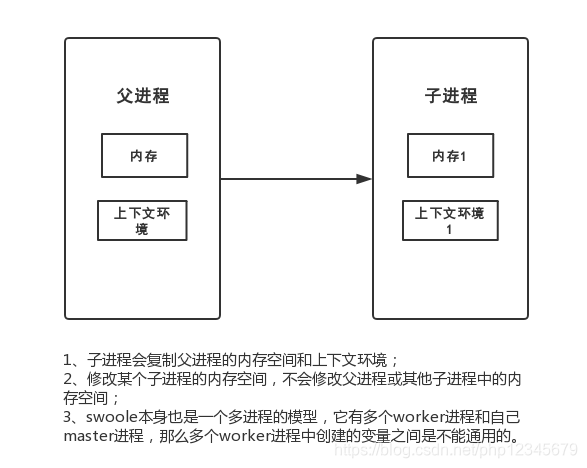
Swoole的进程结构
Swoole的高效不仅仅于底层使用c编写,他的进程结构模型也使其可以高效的处理业务,我们想要深入学习,并且在实际的场景当中使用必须了解,下面我们先看一下结构图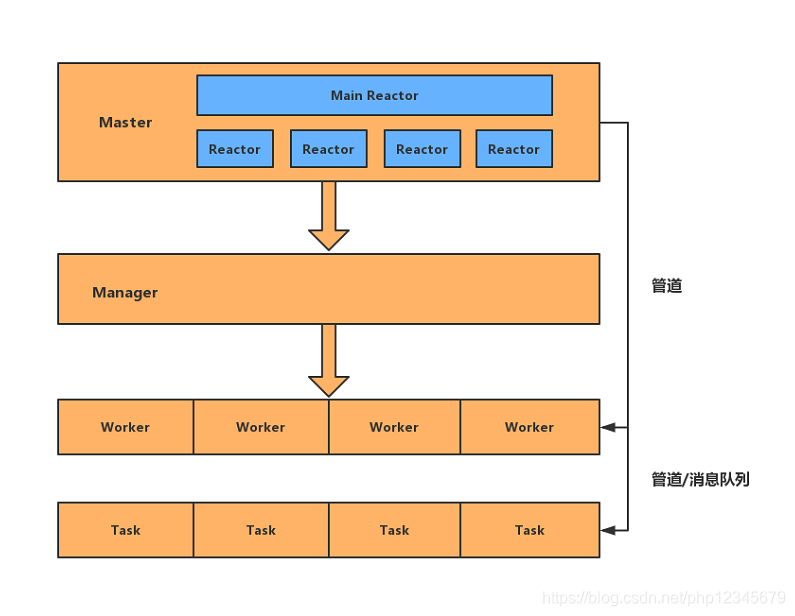
首先先介绍下swoole的这几种进程分别是干什么的:
1)Master进程:主进程
第一层,Master进程,这个是swoole的主进程,这个进程是用于处理swoole的核心事件驱动的,那么在这个进程当中可以看到它拥有一个MainReactor[线程]以及若干个Reactor[线程],swoole所有对于事件的监听都会在这些线程中实现,比如来自客户端的连接,信号处理等。
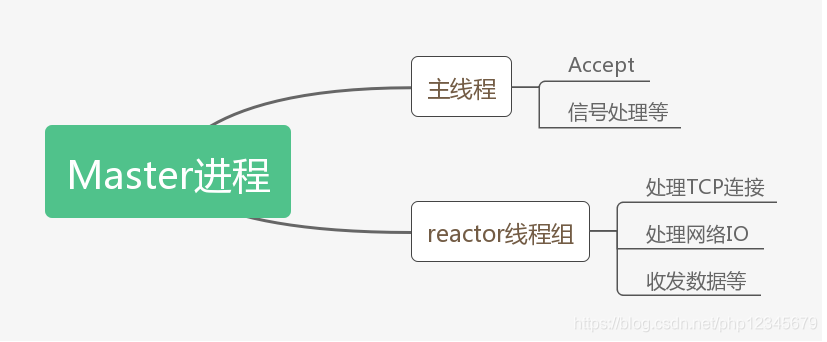
MainReactor(主线程)
1 主线程会负责监听server socket,如果有新的连接accept, 2 主线程会评估每个Reactor线程的连接数量。 3 将此连接分配给连接数最少的reactor线程,做一个负载均衡。
Reactor线程组
1 Reactor线程负责维护客户端机器的TCP连接、处理网络IO、收发数据 2 完全是异步非阻塞的模式。 3 swoole的主线程在Accept新的连接后,会将这个连接分配给一个固定的Reactor线程, 4 在socket可读时读取数据,并进行协议解析,将请求投递到Worker进程。在socket可写时将数据发送给TCP客户端。
心跳包检测线程(HeartbeatCheck)
1 Swoole配置了心跳检测之后,心跳包线程会在固定时间内对所有之前在线的连接 2 发送检测数据包
UDP收包线程(UdpRecv)
1 接收并且处理客户端udp数据包
2)Manger进程:管理进程
Swoole在运行中会创建一个单独的管理进程,所有的worker进程和task进程都是从管理进程Fork出来的。管理进程会监视所有子进程的退出事件,当worker进程发生致命错误或者运行生命周期结束时,管理进程会回收此进程,并创建新的进程。换句话也就是说,对于worker、task进程的创建、回收等操作全权有“保姆”Manager进程进行管理。
再来一张图梳理下Manager进程和Worker/Task进程的关系。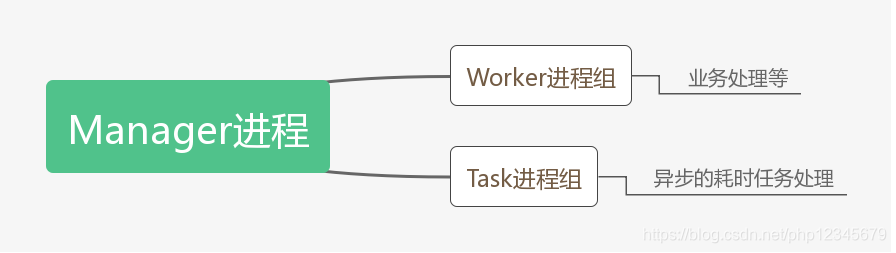
3)Worker进程:工作进程
worker 进程属于swoole的主逻辑进程,用户处理客户端的一系列请求,接受由Reactor线程投递的请求数据包,并执行PHP回调函数处理数据生成响应数据并发给Reactor线程,由Reactor线程发送给TCP客户端可以是异步非阻塞模式,也可以是同步阻塞模式。
4)Task进程:异步任务工作进程
taskWorker进程这一进程是swoole提供的异步工作进程,这些进程主要用于处理一些耗时较长的同步任务,在worker进程当中投递过来。
进程查看及流程梳理
当启动一个Swoole应用时,一共会创建2 + n + m个进程,2为一个Master进程和一个Manager进程,其中n为Worker进程数。m为TaskWorker进程数。
默认如果不设置,swoole底层会根据当前机器有多少CPU核数,启动对应数量的Reactor线程和Worker进程。我机器为1核的。Worker为1。
所以现在默认我启动了1个Master进程,1个Manager进程,和1个worker进程,TaskWorker没有设置也就是为0,当前server会产生3个进程。
在启动了server之后,在命令行执行ps -ajft|grep server.php查看当前产生的进程
这三个进程中,所有进程的根进程,也就是例子中的21915进程,就是所谓的Master进程;而21917进程,则是Manager进程;最后的21919进程,是Worker进程。
swoole事件处理流程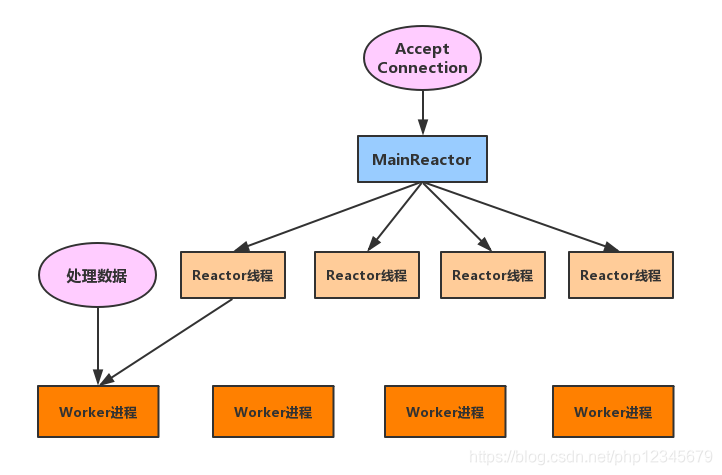
swoole使用的是reactor事件处理模式,一个请求经历的步骤如下
1 服务器主线程等待客户端连接。 2 Reactor线程处理接连socket,读取socket上的请求数据(Receive),将请求封装好后投递给work进程。 3 Work进程就是逻辑单元,处理业务数据。 4 Work进程结果返回给Reactor线程。 5 Reactor线程将结果写回socket(Send)。
转载 http://wangzhenkai.com/article/16
参考 https://juejin.im/entry/6844903842404892680