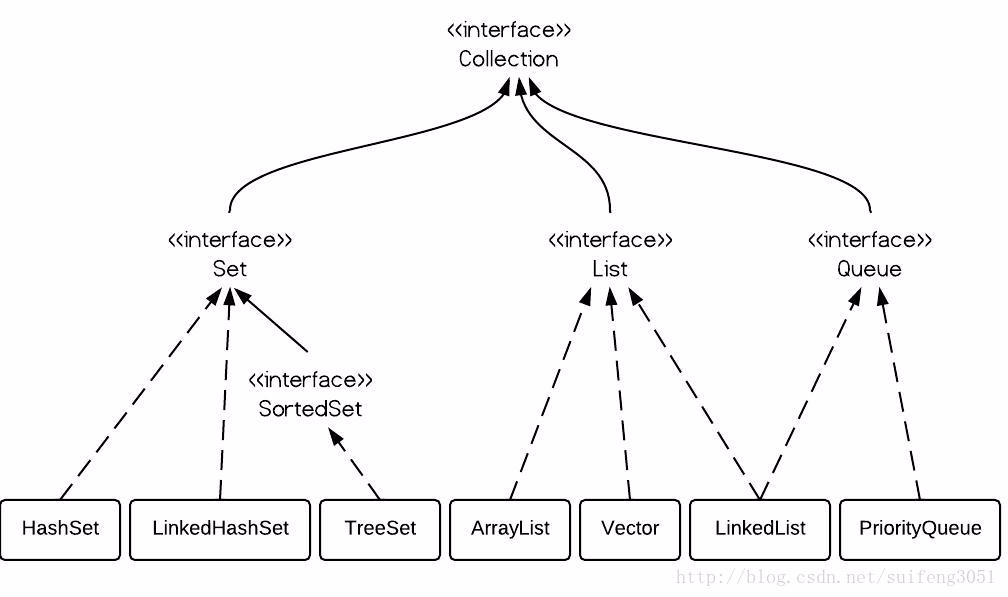
Collection<E>/集合
Collection与Collections
- Collection是所有集合类的根接口;
- Collections是提供集合操作的工具类;
集合类和数组不同,
- 数组元素可以为基本数据类型值/对象引用;
- 集合元素只能为对象引用;
Java的集合类由Collection接口和Map接口派生,
- Set代表无序集合,无序不可重复;
- List代表有序集合,有序可重复;
- Map集合存储键值对;
toArray(T[] array)/集合转数组
<T> T[] toArray(T[] a);
集合转数组时,必须使collection的toArray(T[] array)方法,传入类型完全一样的数组,大小应为list.size();
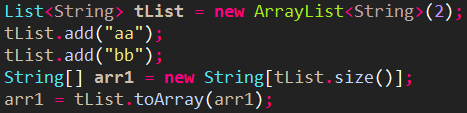
直接使用toArray无参方法,返回值只能是Object[]类,进行类型强转会出现ClassCastException错误;
Iterator<E>/迭代器
public interface Iterable<E> { // Iterable泛型接口Iterator<E> iterator(); // 由继承接口的集合类负责实现,返回一个迭代器}
Iterator用于遍历/迭代访问集合中的元素,只能单向移动;
Iterator遍历方式一:
Iterator it = CollectionInstance.iterator(); // Iterator应与指定集合绑定while(it.hasNext()) // 如果集合尚未迭代完毕,返回ture{collectionElementType cet = (collectionElementType)it.next();// next()方法返回集合下一个元素it.remove();// remove()方法删除上一次调用next方法返回的集元素}
Iterator遍历方式二:
// foreach循环遍历for(CollectionType obj : Collection) {...}
Set<E>/无序集合/集
Set集合中对象不可重复,因此当试图添加两个相同元素时,add()方法返回false/元素不可加入;
Set集合中对象必须重写hashCode()方法和equals()方法;
HashSet<E>/散列集
按照Hash算法存储结合元素—>具有良好的存取/查找性能;
- 添加元素时,调用hashCode()方法计算对象的hashCode值;
- 根据hashCode值决定对象的存储位置—>元素存储顺序和添加顺序可能不一致(LinkedHashSet可保证);
- HashSet判断元素相等的标准:equal()方法相等/hashCode()方法返回值相同;
- Hash算法/哈希/散列:通过计算元素的hashCode值获取元素的存储位置—>价值在于存取/查找速度快
- 与数组相比,HashSet索引不需要连续,可自由增加HashSet长度;
LinkedHashSet<E>
HashSet的子类,LinkedHashSet也是根据元素的hashCode值决定其存储位置;
同时使用链表维护元素的添加次序—>性能略低于HashSet的性能;
TreeSet<E>/树集
TreeSet实现SortSet接口,
TreeSet采用红黑树(red-black tree)存储集合元素,排序规则支持自然排序/定制排序;
TreeSet存储对象必须实现Comparable接口;
List<E>/列表
Java中所有链表底层都是双向链接(doubly linked);
List额外提供listIterator()方法,该方法返回一个ListIterator对象,用于遍历List;
ListIterator的set(obj)方法用新元素obj覆盖next()/previous()返回的上一个元素,可以双向移动;
ListIteritor lit = listInstance.listIterator();// 正向顺序迭代Listwhile(lit.hasNext()){System.out.println(lit.next());}// 反向逆序迭代Listwhile(lit.hasPrevious()){System.out.println(lit.previous());}
ArrayList<E>/数组列表
ArrayList底层有数组支持,通常作为默认首选;当程序频繁进行插入/删除操作时,选用LinkedLIst;如果元素数量固定,可选择真正数组/List/备选;
ArrayList/Vector辨析
—>ArrayList与Vector用法几乎相同,JDK1.0推出Vector/JDK2.0将Vector改为实现List接口;
—>Vector缺点较多,尽量避免使用;
—>Vector是线程安全的,但是Collections工具类可使得ArrayList线程安全;
—>Vector拥有子类Stack,性能较差,可用ArrayDeque替代;
LinkedList<E>/链表实现/双端队列实现
LinkedList底层由双向链表实现,执行插入/删除操作时性能较好,避免使用get(index)遍历LinkedList(随机查找时均从头开始查找,性能低下);
- 实现List接口。可根据索引随机访问集合元素(ArrayDeque不支持);
- 实现Deque接口。可当作双向队列使用—>可实现"栈"/普通队列;
Queue<E>/队列
Queue接口中定义的主要方法:

// 入队boolean add(Object e): 入队/成功返回true/失败抛出IllegalStateExceptionboolean offer(Object e):入队/失败返回false/适用于固定容量的队列// 获取队首Object peek(): 获取队首/不删除/队列为空返回null值Object element(): 获取队首/不删除/队列为空抛出异常- // 弹出队首
Object poll(): 弹出队首/队列为空返回null值Object remove(): 弹出队首/队列为空抛出异常
Deque接口/双端队列
Deque接口是Queue接口的子接口,表示双向队列;
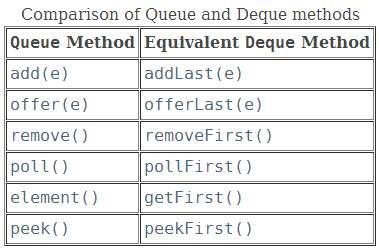
Deque接口定义的部分双向队列操作,部分方法可模拟“栈”的实现/Java中已集成操作栈方法:
- "push":添加元素到队首,addFirst(e);
- "pop":弹出队首元素,removeFirst();
- "peek":获取栈顶,peekFirst();
ArrayDeque<E>/栈实现/Deque实现
ArrayDeque实现“栈”,LIFO(后入先出):

ArrayDeque实现普通队列,FIFO(先入先出):
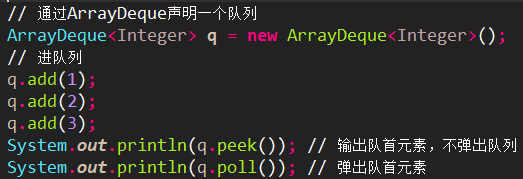
PriorityQueue<E>/优先队列
PQ采用堆结构实现,不允许插入null元素,有自然排序和定制排序两种方式,使用时再补充:
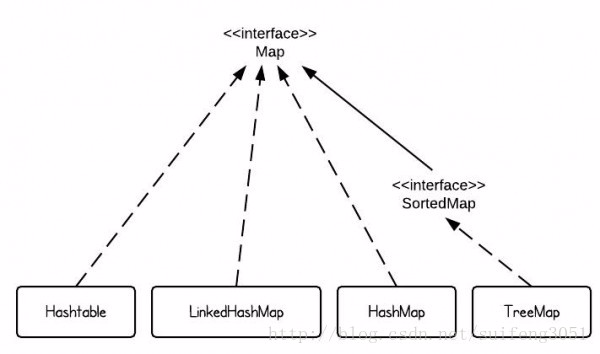
Map/字典/关联数组/映射表
Map用于保存具有映射关系的数据;
key和value可以为任何引用类型,Map通过key索引/操作value,如果自定义对象作为Map的键,该对象必须重写hashCode和equals(键的唯一性);
key不可重复,并且同一个key只索引一个value;
key不可重复,并且同一个key只索引一个value;
- Set<K> keySet():获取Map的键集,从键集中进行一次删除键操作,等价于从Map中删除对应键值对;
- Collection<K> values():获取Map的值集合,从值集合中进行一次删除值操作,等价于从Map中删除对应一项键值对;
- Set<Map.Entry<K, V>> entrySet():获取Map的键/值对集,Entry<K, V>表示一对键值对,是静态内部类Map.Entry对象;
遍历Map
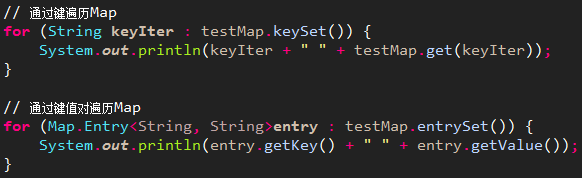
KeySet()遍历实质:遍历两次,第一次转为Iterator对象,第二次从Map中去除key对应的value;
entrySet()遍历实质:只遍历一次就把K,V放入entry中,效率较KeySet()更高;
Map各实现类性能比较
- HashMap为快速查询而设计,HashMap通常比Hashtable快,一般应多采用HashMap;
- TreeMap为排序而设计,TreeMap通常比HashMap慢;
- LinkedHashMap维护键值对添加顺序,LinkedHashMap比HashMap较慢;
HashMap/散列映射表
Hashmap对key进行散列
HashMap与Hashtable
HashMap允许key为null值/最多只有一个,value值可为null/不限制;
与Vector类似,Hashtable类推出较早,尽量避免使用—>Collections工具类可使得HashMap线程安全;
HashMap判断两个key相等的标准—>equals()方法返回true/两个key的hashCode值相等;
判断两个value相等的标准—>equals()方法返回true;
—>使用自定义类作为key值时,重写equals方法/hashCode方法时—>应使equals()返回true时,hashCode()返回值也相同;
LinkedHashMap/链式散列映射表
LinkedHashMap使用双向链表维护键值对的插入顺序,性能略低于HashMap;
IdentityHashMap/标识散列映射表
IdentityHashMap中,键的散列值(hashCode)不通过ashCode()方法计算,通过Sytem.identityHashCode()方法计算;
进行对象比较时,IdentityHashMap类使用“==”判断,不使用equals()方法;
WeakHashMap/弱散列映射
WeakHashMap的键为弱引用/WeakReference,回收后自动删除对应键值对;
TreeMap/树映射表
TreeMap根据key的整体顺序对元素进行排序,组织成红黑树形式;