分布式事务就是为了保证不同数据库的数据一致性。 TCC
CAP 定理,又被叫作布鲁尔定理。对于设计分布式系统(不仅仅是分布式事务)的架构师来说,CAP 就是你的入门理论。
C (一致性) A (可用性) P (分区容错性)
对于 CP 来说,放弃可用性,追求一致性和分区容错性,我们的 ZooKeeper 其实就是追求的强一致。
BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写,是对 CAP 中 AP 的一个扩展。
有这样一个需求:
小明有两个账户,分别位于A、B两个数据库中,小明需要将A中的资金转到B中。
我们如何实现?
按照下面的方式实现看看有没有问题。
- 连接数据库A,获取connA连接
- connA打开事务
- A库资金减少100
- 连接库B,获取connB连接
- connB打开事务
- B库资金增加100
- connA.commit()
- connB.commit()
上面操作,正常情况是没有问题。
第7步执行成功之后,网络出问题了,第8步会提交失败,此时的结果是:A库资金减少了100,B库资金却没有增加;这是一个网络问题导致了我们业务失败了,网络因素是程序不可控的一些因素,还有其他的比如运行到7之后,系统突然断电了,也会出现同样的结果。造成了数据错误,对业务影响也是比较大的。
分布式事务可以这么理解:一个业务操作中,会包含很多子业务的,每个子业务都是独立的事务,我们需要考虑的是如何保证这些子业务都成功,或者都失败。
什么是最终一致性?
就拿上面的转账来说,A库的资金减少了,由于网络问题,操作B库的connB连接断开了,导致B库资金没有增加;网络问题是可以恢复了,如果网络恢复了,系统能够给B中资金加上,这样最终数据也是正确的;这中间有段时间AB库的资金是不一致的(A库减少了100,B库应该增加100却没有增加,数据是不一致的),但是最终某个时间点数据变为一致了。能够将不一致的时间降到最低是系统需要考虑的问题。
分布式事务中,我们可以接受数据在某个时间段之内不一致,但是数据最终在某个时间点是一致的。
常见解决方案
- 可靠消息模式
- TCC模式实现(Try-Confirm-Cancel)
分布式事务系列中主要讲这2种方案,这两种方案基本上可以解决大多数常见的分布式事务的问题,所以咱们必须把这两种方式拿下。
下面我们介绍一下使用可靠消息如何实现?
可靠消息模式实现转账操作
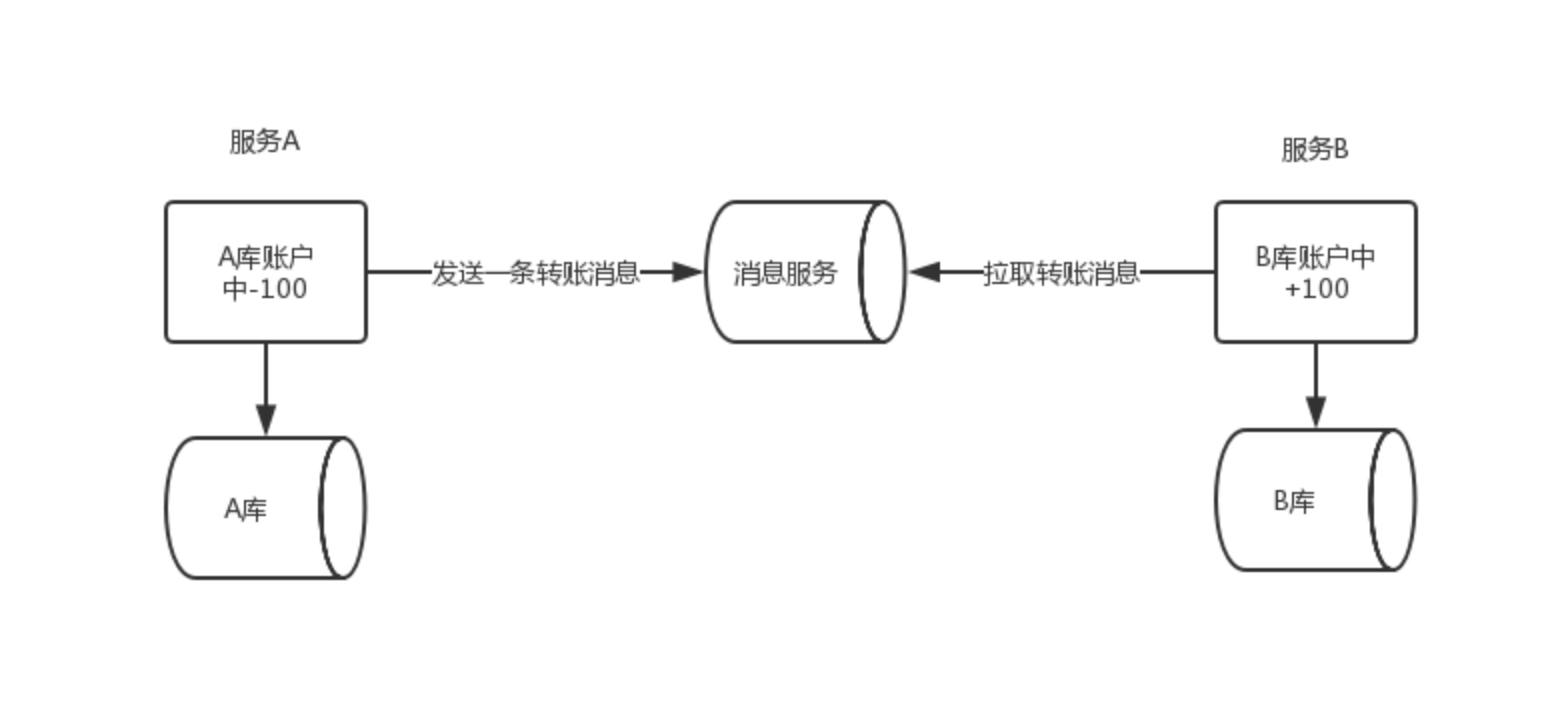
- 常见的使用最多的解决方案:异步消息处理分布式事物、tcc模式
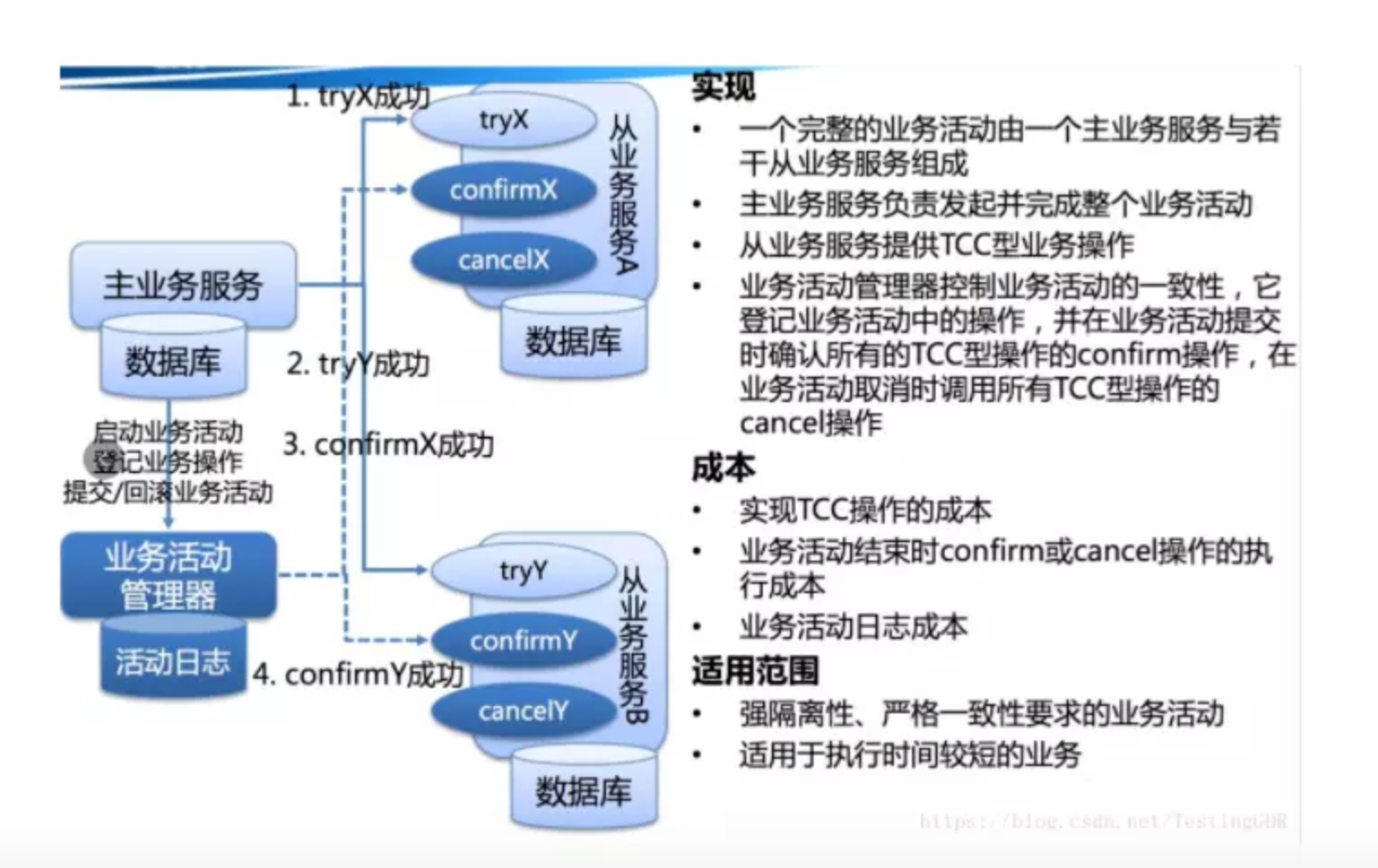
对于 TCC 的解释:
Try 阶段:尝试执行,完成所有业务检查(一致性),预留必需业务资源(准隔离性)。
Confirm 阶段:确认真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源,Confirm 操作满足幂等性。要求具备幂等设计,Confirm 失败后需要进行重试。
Cancel 阶段:取消执行,释放 Try 阶段预留的业务资源,Cancel 操作满足幂等性。Cancel 阶段的异常和 Confirm 阶段异常处理方案基本上一致。
举个简单的例子:如果你用 100 元买了一瓶水, Try 阶段:你需要向你的钱包检查是否够 100 元并锁住这 100 元,水也是一样的。
如果有一个失败,则进行 Cancel(释放这 100 元和这一瓶水),如果 Cancel 失败不论什么失败都进行重试 Cancel,所以需要保持幂等。
如果都成功,则进行 Confirm,确认这 100 元被扣,和这一瓶水被卖,如果 Confirm 失败无论什么失败则重试(会依靠活动日志进行重试)。
对于 TCC 来说适合一些:
强隔离性,严格一致性要求的活动业务。
执行时间较短的业务。
探讨一下实现幂等性的几种方式
对于同一笔业务操作,不管调用多少次,得到的结果都是一样的。

悲观锁方式
select * from t_order where order_id = trade_no for update;重点在于for update,对for update,做一下说明:
1.当线程A执行for update,数据会对当前记录加锁,其他线程执行到此行代码的时候,会等待线程A释放锁之后,才可以获取锁,继续后续操作。
2.事物提交时,for update获取的锁会自动释放。
CAS是英文单词Compare And Swap的缩写,翻译过来就是比较并替换。
CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。
更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B。
CAS的缺点:
1.CPU开销较大
在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复,会给CPU带来很大的压力。
2.不能保证代码块的原子性
CAS机制所保证的只是一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证3个变量共同进行原子性的更新,就不得不使用Synchronized了。
3.ABA问题
这是CAS机制最大的问题所在。
什么是ABA问题?怎么解决?我们下一期来详细介绍。

什么是幂等性?
对于同一笔业务操作,不管调用多少次,得到的结果都是一样的。

普通方式:
过程如下:
1.接收到支付宝支付成功请求
2.根据trade_no查询当前订单是否处理过
3.如果订单已处理直接返回,若未处理,继续向下执行
4.开启本地事务
5.本地系统给用户加钱
6.将订单状态置为成功
7.提交本地事务
jvm加锁方式
方式1中由于并发出现了问题,此时我们使用java中的Lock加锁,来防止并发操作,过程如下:
分析问题:
Lock只能在一个jvm中起效,如果多个请求都被同一套系统处理,上面这种使用Lock的方式是没有问题的,不过互联网系统中,多数是采用集群方式部署系统,同一套代码后面会部署多套,如果支付宝同时发来多个通知经过负载均衡转发到不同的机器,上面的锁就不起效了。此时对于多个请求相当于无锁处理了,又会出现方式1中的结果。此时我们需要分布式锁来做处理。
方式4(乐观锁方式)
依靠数据库中的乐观锁来实现。
1.接收到支付宝支付成功请求
2.查询订单信息
select * from t_order where order_id = trade_no;
3.判断订单是已处理
4.如果订单已处理直接返回,若未处理,继续向下执行
5.打开本地事物
6.给本地系统给用户加钱
7.将订单状态置为成功,注意这块是重点,伪代码:
update t_order set status = 1 where order_id = trade_no where status = 0;
//上面的update操作会返回影响的行数num
if(num==1){
//表示更新成功
提交事务;
}else{
//表示更新失败
回滚事务;
}
注意:
update t_order set status = 1 where order_id = trade_no where status = 0; 是依靠乐观锁来实现的,status=0作为条件去更新,类似于java中的cas操作;关于什么是cas操作,可以移步:什么是 CAS 机制?
执行这条sql的时候,如果有多个线程同时到达这条代码,数据内部会保证update同一条记录会排队执行,最终最有一条update会执行成功,其他未成功的,他们的num为0,然后根据num来进行提交或者回滚操作。
悲观锁方式
使用数据库中悲观锁实现。悲观锁类似于方式二中的Lock,只不过是依靠数据库来实现的。数据中悲观锁使用for update来实现,过程如下:
1.接收到支付宝支付成功请求
2.打开本地事物
3.查询订单信息并加悲观锁
select * from t_order where order_id = trade_no for update;
4.判断订单是已处理
5.如果订单已处理直接返回,若未处理,继续向下执行
6.给本地系统给用户加钱
7.将订单状态置为成功
8.提交本地事物
重点在于for update,对for update,做一下说明:
1.当线程A执行for update,数据会对当前记录加锁,其他线程执行到此行代码的时候,会等待线程A释放锁之后,才可以获取锁,继续后续操作。
2.事物提交时,for update获取的锁会自动释放。
方式3可以正常实现我们需要的效果,能保证接口的幂等性,不过存在一些缺点:
1.如果业务处理比较耗时,并发情况下,后面线程会长期处于等待状态,占用了很多线程,让这些线程处于无效等待状态,我们的web服务中的线程数量一般都是有限的,如果大量线程由于获取for update锁处于等待状态,不利于系统并发操作。
唯一约束方式
依赖数据库中唯一约束来实现。
我们可以创建一个表:
CREATE TABLE `t_uq_dipose` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`ref_type` varchar(32) NOT NULL DEFAULT '' COMMENT '关联对象类型',
`ref_id` varchar(64) NOT NULL DEFAULT '' COMMENT '关联对象id',
PRIMARY KEY (`id`),
UNIQUE KEY `uq_1` (`ref_type`,`ref_id`) COMMENT '保证业务唯一性'
) ENGINE=InnoDB;
对于任何一个业务,有一个业务类型(ref_type),业务有一个全局唯一的订单号,业务来的时候,先查询t_uq_dipose表中是否存在相关记录,若不存在,继续放行。
过程如下:
1.接收到支付宝支付成功请求
2.查询t_uq_dipose(条件ref_id,ref_type),可以判断订单是否已处理
select * from t_uq_dipose where ref_type = '充值订单' and ref_id = trade_no;
3.判断订单是已处理
4.如果订单已处理直接返回,若未处理,继续向下执行
5.打开本地事物
6.给本地系统给用户加钱
7.将订单状态置为成功
8.向t_uq_dipose插入数据,插入成功,提交本地事务,插入失败,回滚本地事务,伪代码:
try{
insert into t_uq_dipose (ref_type,ref_id) values ('充值订单',trade_no);
提交本地事务:
}catch(Exception e){
回滚本地事务;
}
说明:
对于同一个业务,ref_type是一样的,当并发时,插入数据只会有一条成功,其他的会违法唯一约束,进入catch逻辑,当前事务会被回滚,最终最有一个操作会成功,从而保证了幂等性操作。
关于这种方式可以写成通用的方式,不过业务量大的情况下,t_uq_dipose插入数据会成为系统的瓶颈,需要考虑分表操作,解决性能问题。
上面的过程中向t_uq_dipose插入记录,最好放在最后执行,原因:插入操作会锁表,放在最后能让锁表的时间降到最低,提升系统的并发性。
关于消息服务中,消费者如何保证消息处理的幂等性?
每条消息都有一个唯一的消息id,类似于上面业务中的trade_no,使用上面的方式即可实现消息消费的幂等性。
1.实现幂等性常见的方式有:悲观锁(for update)、乐观锁、唯一约束
2.几种方式,按照最优排序:乐观锁 > 唯一约束 > 悲观锁
脏读
一个事务在执行的过程中读取到了其他事务还没有提交的数据。
读已提交
即一个事务操作过程中可以读取到其他事务已经提交的数据。
可重复读
一个事务操作中对于一个读取操作不管多少次,读取到的结果都是一样的。
幻读
脏读、不可重复读、可重复读、幻读,其中最难理解的是幻读
幻读在可重复读的模式下才会出现,其他隔离级别中不会出现
事务A重新执行一个查询,返回一系列符合查询条件的行,发现其中插入了被事务B提交的行
http://www.itsoku.com/article/77
https://www.cnblogs.com/itsoku123/p/10875203.html