反向传播算法从大体上理解就是通过计算最终误差与某个权值参数的梯度,来更新权值参数。
梯度就是最终误差对参数的导数,通过链式求导法则求出。
然后通过赋予学习率计算得出,例如:
其中 为学习率。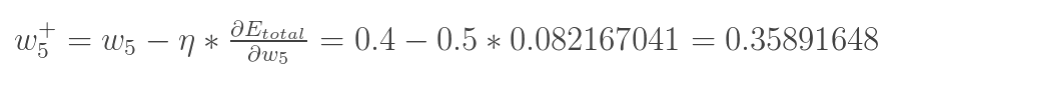
Python代码如下:
import numpy as np
def nonlin(x, deriv = False):
if(deriv == True):
return x * (1 - x)
return 1 / (1 + np.exp(-x))
//计算s函数,以及用于反向传播的函数
X = np.array([[0.35], [0.9]])
y = np.array([[0.5]])
np.random.seed(1)
W0 = np.array([[0.1, 0.8], [0.4, 0.6]])
W1 = np.array([[0.3, 0.9]])
print 'original ', W0, '
', W1
for j in xrange(100):
l0 = X
l1 = nonlin(np.dot(W0, l0))
l2 = nonlin(np.dot(W1, l1))
l2_error = y - l2
Error = 1 / 2.0 * (y-l2)**2
print 'Error:', Error
l2_delta = l2_error * nonlin(l2, deriv=True)
l1_error = l2_delta * W1 #back propagation,误差向前传播
l1_delta = l1_error * nonlin(l1, deriv=True) //类似l2_delta的计算
W1 += l2_delta * l1.T
//采用的是另一种反向传播算法,与用误差和参数梯度计算所得结果一样。通过s函数实现。更新的是输出层的参数,仅需一次运算
W0 += l0.T.dot(l1_delta)
print W0, '
', W1