FCN特点
1.卷积化
即是将普通的分类网络丢弃全连接层,换上对应的卷积层即可2.上采样
方法是双线性上采样差
此处的上采样即是反卷积3.因为如果将全卷积之后的结果直接上采样得到的结果是很粗糙的,
所以作者将不同池化层的结果进行上采样之后来优化输出
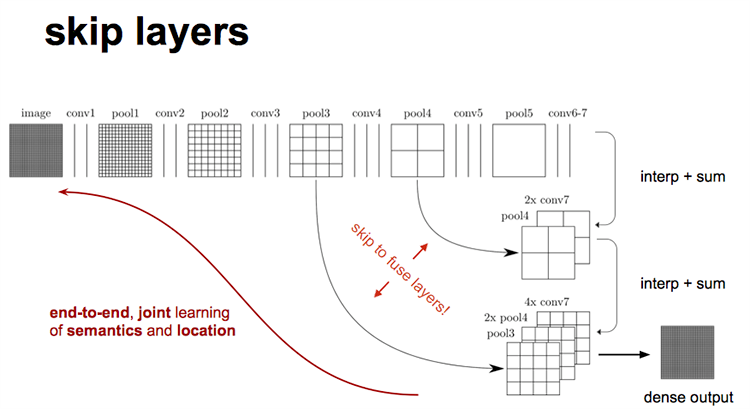
3.跳跃结构:
现在我们有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap进行upsampling操作之后,因为这样的操作还原的图片仅仅是
conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征,因此
在这里向前迭代。把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充
细节(相当于一个差值过程),最后把conv3中的卷积核对刚才upsampling之后的
图像进行再次反卷积补充细节,最后就完成了整个图像的还原。
http://www.cnblogs.com/gujianhan/p/6030639.html
https://blog.csdn.net/qq_38906523/article/details/80520950
CNN对输入图片尺寸有要求,而FCN没有的原因
经过卷积层之后的outputsize和inputsize之间的关系是固定的,outputsize = (inputsize - kernelsize) / stride + 1,但它们
并不用相互关心。
cnn在经过每个卷积层之后,产生一个feature map,这个feature map(n*n)的大小是由神经网络的结构所决定的,
feature map进入全连接层后要变成一个长向量,这个长向量每个元素(假设为n个)需要与下一层的所有神经元相连接,
(全链接层输入向量的维数对应全链接层的神经元个数)神经网络
的结构一旦确定,权值参数的个数就确定,故参数个数都已确定。向前推导即是每个层得到的结果都必须是确定的,
所以,cnn对于输入图片的尺寸大小有要求,全连接层的输入是固定大小的,如果输入向量的维数不固定,那么全连接的权值参数
的量也是不固定的,就会造成网络的动态变化,无法实现参数训练目的
修正理解:
feature map输入进入全连接层要变成一个长向量,这个长向量与全连接层的神经元相连接(相对应),而神经网络整个结构一旦确定,
权值参数就确定,如果输入向量的位数不固定,那么权值参数就会也不固定,造成网络的动态变化,无法训练参数。
fcn没有全连接层,所以feature map大小不受限制,卷积结束之后,通过上采样得到原图片的大小。
upsampling的方法
经过对比研究,upsampling采用反卷积(有的地方叫法不同)的方法得到的效果比较好。
而在全卷积层之后直接进行Upsampling的效果并不好,因为中间的pooling操作忽略了很多有用的信息。
所以采用了一种跳跃结构,这种结构则是吧前面的pooling层的结果与卷积最后得到的结果一起做加和,
然后再进行upsampling,这样的效果更好。如下图:
以上介绍了FCN的各种重点知识,下面介绍整体流程及细节
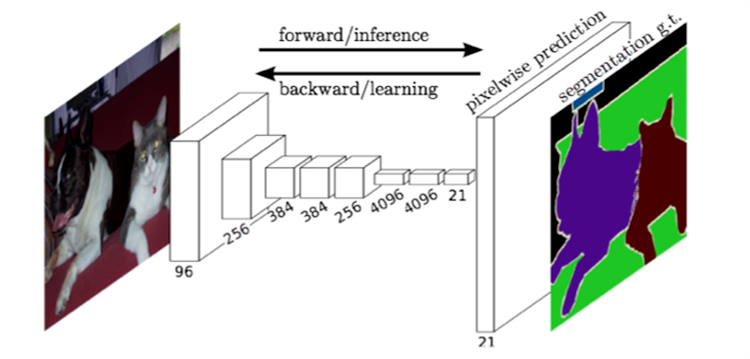
1.FCN与CNN的区别就在于把CNN最后的全连接层换成卷积层来进行逐像素的分类识别,输入图片后经过前部分的
卷积层之后会得到一个feature map,由这个feature map进行上采样得到与原始图像尺寸相同的结果,从而恢复了
对每个像素的分类,最后通过softmax分类计算像素损失得到最终预测结果。结构如下图:
FCN的缺点:
1.对像素与像素之间的关系并没有考虑到,忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
2.虽然8倍的上采样效果还可以,但还有待提高,不够精细,细节还有待提高。