UI自动化元素识别
selenium 常用api罗列
1.浏览器中加载URL:driver.get('http://wwwbaidu.com')
2.浏览器最大化:driver.maximize_window()
3.浏览器最小化:driver.minimize_window()
4.自定义浏览器窗口大小:driver.set_window_size(200,200)
5.刷新:driver.refresh()
6.返回上一页:driver.back()
7.向前进一页:driver.forward()
8.截图:driver.get_screenshot_as_file("c:\\test.bmp”)
9.获取当前页的URL:driver.current_url
10.获取当前页面的title:driver.title
11.获取页面源代码:driver.page_source
12.关闭当前tab页面:driver.close()
13.退出当前driver:driver.quit()
小试牛刀
# -*- coding: utf-8 -*-
# @Time : 2021/12/10 10:50
# @Author : Limusen
# @File : demo_ui_02
import os
import time
from selenium import webdriver
# 方法一 将驱动python的安装路径下
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 最小化
driver.minimize_window()
time.sleep(1)
# 最大化
driver.maximize_window()
time.sleep(1)
# 前进
driver.forward()
# 后退
driver.back()
# 刷新
driver.refresh()
# 截图
driver.get_screenshot_as_file("file.png")
time.sleep(1)
# 关闭浏览器
driver.quit()
元素识别
元素的定位和操作是自动化测试的核心部分,其中操作又是建立在定位的基础上的,举例:一个对象就是一个人,我们可以通过身份证号、姓名或者他的住址找到这个人。那么一个web对象也是一样的,我们可以通过唯一区别于其它元素的属性来定位这个元素。
元素识别:
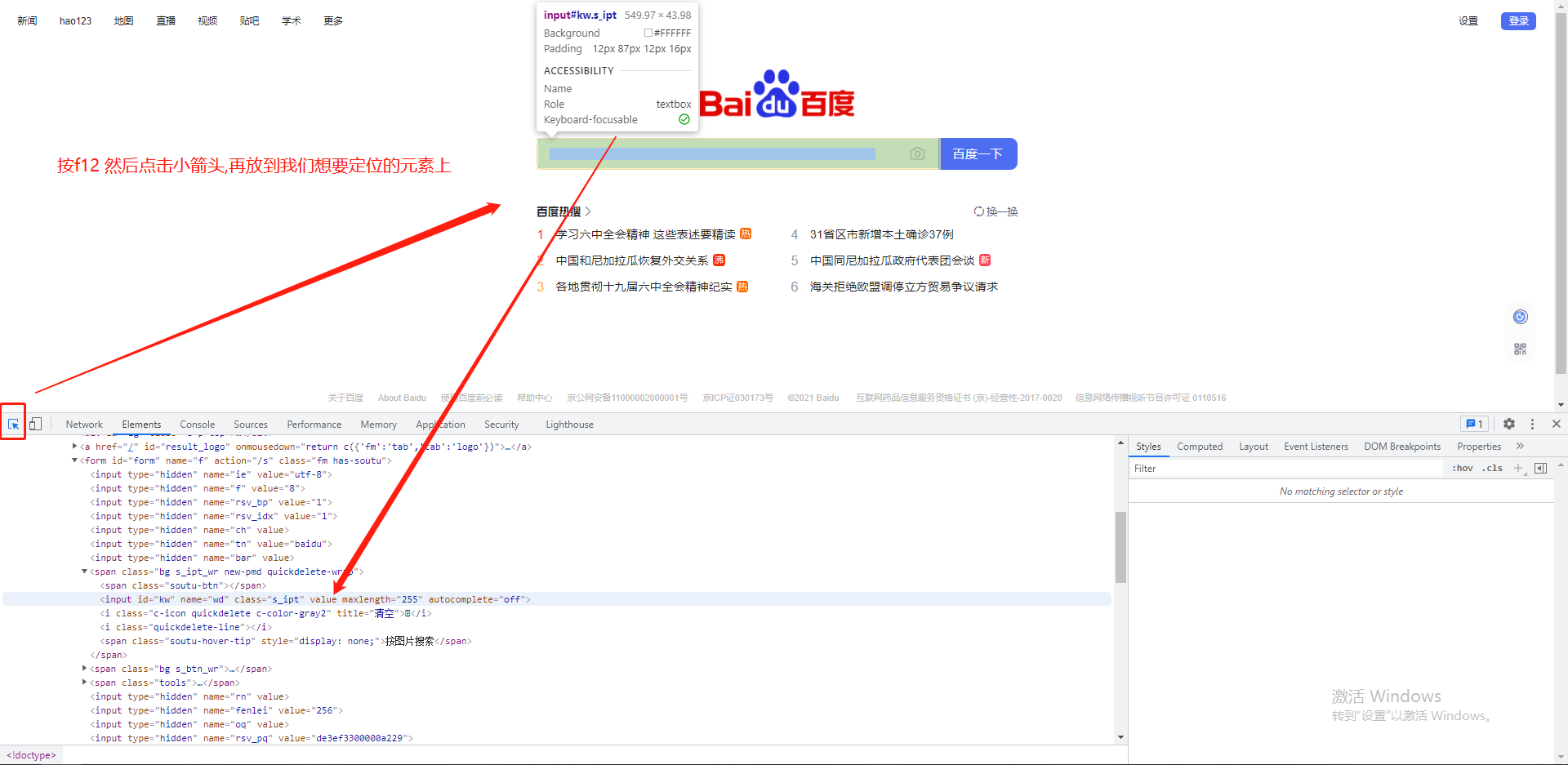
1、利用Chrome浏览器开发者工具:
1)打开Chrome浏览器,按F12或依次点击菜单—更多工具—开发者工具;
2)切换到Elements页签,在Elements下点击左上方小箭头可以指定页面元素,查看对应代码
2、利用火狐浏览器开发者工具:
1)打开火狐浏览器,按F12或点击菜单—web开发者—查看器;
2)进入到查看器页签,在查看器下点击左上方小箭头可以指定页面元素,查看对应代码
-
识别方法
1.通过id定位元素: driver.find_element_by_id("id_vaule")
2.通过name定位元素: driver.find_element_by_name("name_vaule")
3.通过class_name定位元素:driver.find_element_by_class_name("class_name")
4.通过tag_name定位元素:driver.find_element_by_tag_name("tag_name_vaule")
5.通过link定位:driver.find_element_by_link_text("text_vaule")或:driver.find_element_by_partial_link_text("text_vaule")
6.通过xpath定位元素:driver.find_element_by_xpath("xpath_syntax")
7.通过css定位元素driver.find_element_by_css_selector(“css_syntax”)
- 牛刀小试
# -*- coding: utf-8 -*-
# @Time : 2021/12/10 11:06
# @Author : Limusen
# @File : baidu_demo_01
"""
页面元素均为百度
可自行查找元素
"""
import os
import time
from selenium import webdriver
png_file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), '..', 'sample', 'png_file', '{}')
# 方法一 将驱动python的安装路径下
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.implicitly_wait(10)
# ===============通过id定位===============#
# # 从上面截图可以发现,这个元素有一个id属性,我们可以通过id去定位这个属性值
# # 然后进行操作
# driver.find_element_by_id("kw").send_keys("今天你吃饭了没")
# time.sleep(2)
# driver.find_element_by_id("su").click()
# time.sleep(2)
# driver.get_screenshot_as_file(png_file_path.format("baidu_id.png"))
# driver.quit()
# ===============通过id定位===============#
# ===============通过name-class定位===============#
# driver.find_element_by_name("wd").send_keys("今天你吃饭了没")
# # 注意class一个属性如果为空格 需要用.来进行拼接才能识别到
# driver.find_element_by_class_name("bg.s_btn").click()
# ===============通过name定位===============#
# ===============通过tag_name定位===============#
# 用的比较少
# ===============通过tag_name定位===============#
# ===============通过link_text定位===============#
# driver.find_element_by_link_text("hao123").click()
# driver.get_screenshot_as_file(png_file_path.format("baidu_demo_link_text.png"))
# ===============通过link_text定位===============#
# ===============通过xpath定位===============#
# driver.find_element_by_xpath('//span/input[@id="kw"]').send_keys("今天吃饭了吗")
# driver.find_element_by_class_name("bg.s_btn").click()
# ===============通过xpath定位===============#
# ===============通过css定位===============#
driver.find_element_by_css_selector('#kw').send_keys("今天吃饭了吗")
driver.find_element_by_class_name("bg.s_btn").click()
# ===============通过css定位===============#
Xpath
后续主要用的是xpath我们现在讲解一下xpath相关的知识
XPATH是什么?
XPATH是一门在XML文档中查找信息的语言,XPATH可用来在XML文档中对元素和属性进行遍历,主流的浏览器都支持XPATH,因为HTML页面在DOM中表示为XHTML文档。SeleniumWebDriver支持使用XPATH表达式来定位元素。
Xpath常用六种定位方式:
绝对路径
通过绝对路径定位绝对路径的开头是一个斜线(/),从网页的根节点html开始,逐层去查找需要定位的元素。
此方法缺点显而易见,当页面元素位置发生改变时,都需要修改,因此,并不推荐使用。
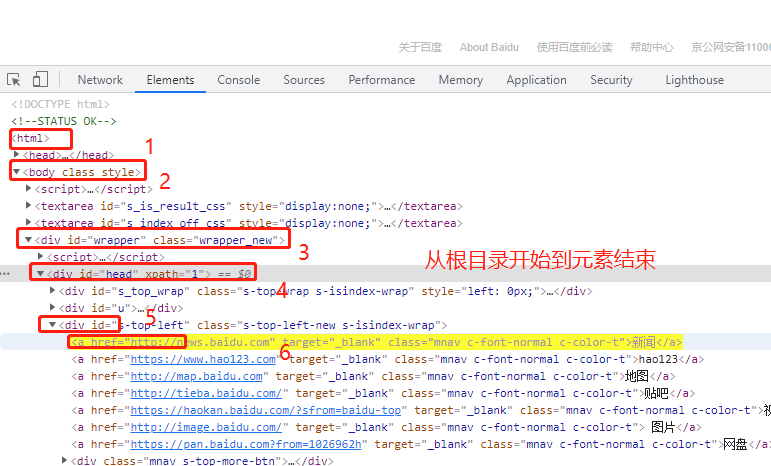
举例:百度搜索框绝对路径定位driver.find_element_by_xpath('/html/body/div[1]/div[1]/div/div[1]/div/form/span[1]/input')
备注:当同一层次有多个相同的元素时,使用下标区分,下标从1开始
- 示例代码
# -*- coding: utf-8 -*-
# @Time : 2021/12/22 15:08
# @Author : Limusen
# @File : demo_ui_03
from selenium import webdriver
driver = webdriver.Chrome()
url = "http://www.baidu.com"
driver.get(url)
# 绝对路径
driver.find_element_by_xpath("html/body/div/div/div[2]/a[1]").click()
相对路径
通过相对路径定位相对路径的开头是两个斜线(//),表示文件中所有符合模式的元素都会被选出来,即使是处于树中不同的层级也会被选出来。
举例:百度搜索框相对路径定位
driver.find_element_by_xpath('//span[1]/input')
driver.find_element_by_xpath(’//form/span[1]/input')
备注:以上都可以定位到百度搜索框,相对路径的长度和开始位置并不受限制,可以采用从后往前逐层定位直到定位到即可的方式去定位。
- 示例代码
from selenium import webdriver
driver = webdriver.Chrome()
url = "http://www.baidu.com"
driver.get(url)
# 相对路径
driver.find_element_by_xpath("//body/div/div/div[3]/a[1]")
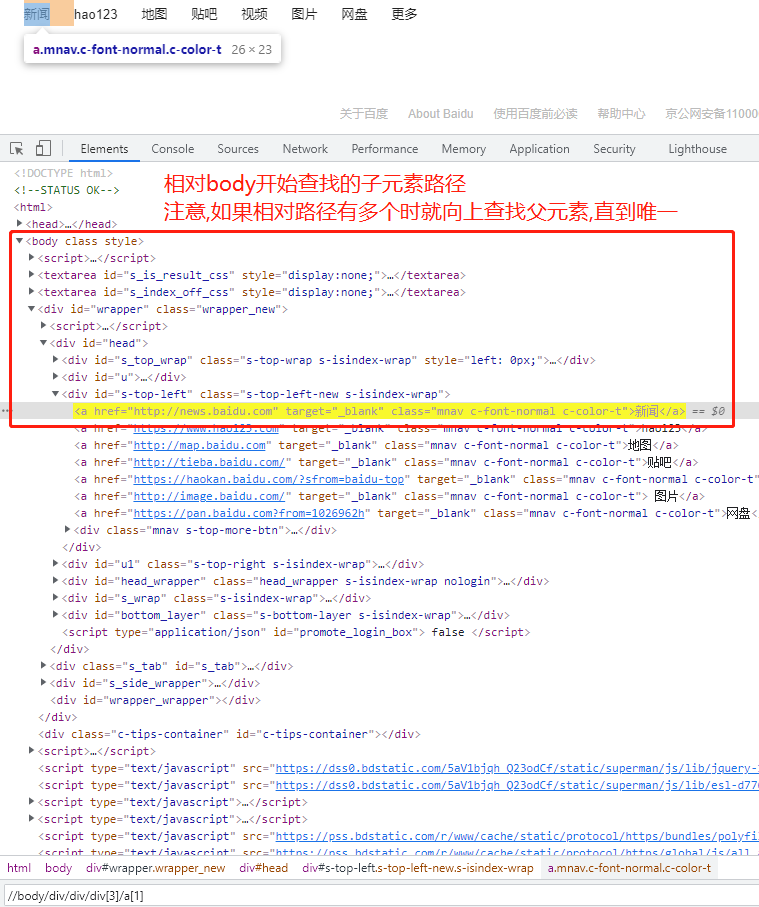
元素索引
通过元素索引定位遇到同层级相同标签元素时,可以使用索引(下标)表示,索引的初始值为1
举例:定位百度hao123链接
driver.find_element_by_xpath('//div[3]/a[2]')
- 示例代码
# -*- coding: utf-8 -*-
# @Time : 2021/12/22 15:08
# @Author : Limusen
# @File : demo_ui_03
import time
from selenium import webdriver
driver = webdriver.Chrome()
url = "http://www.baidu.com"
driver.get(url)
# 索引定位
driver.find_element_by_xpath("//body/div/div/div[3]/a[3]").click()
time.sleep(2)
driver.quit()
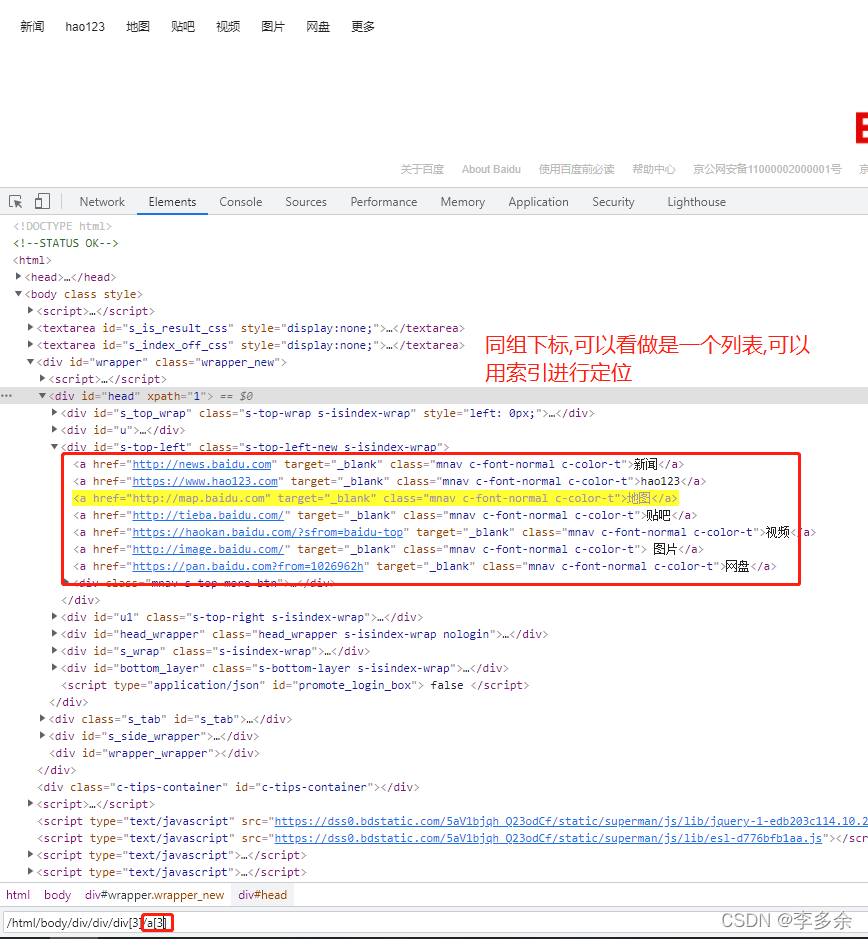
元素属性
使用元素属性定位元素属性定位要求属性能够定位到唯一一个元素,如果存在多个相同条件的标签,默认定位第一个,
具体格式//标签名[@属性="属性值"]
支持使用and和or关键字,多个属性一起定位元素。
举例:
driver.find_element_by_xpath("//a[@name='tj_trnews']")
driver.find_element_by_xpath("//a[@name='tj_trnews'and@class='mnav']")
driver.find_element_by_xpath("//a[@name='tj_trnews’or@class='mnav']")
备注:Xpath支持通配符号*号
通过属性定位还可以如下写法:driver.find_element_by_xpath("//*[@*='tj_trnews']")
- 示例代码
# -*- coding: utf-8 -*-
# @Time : 2021/12/22 15:08
# @Author : Limusen
# @File : demo_ui_03
import time
from selenium import webdriver
driver = webdriver.Chrome()
url = "http://www.baidu.com"
driver.get(url)
# 元素属性
driver.find_element_by_xpath('//input[@id="kw"]').send_keys("0.0")
time.sleep(2)
driver.quit()
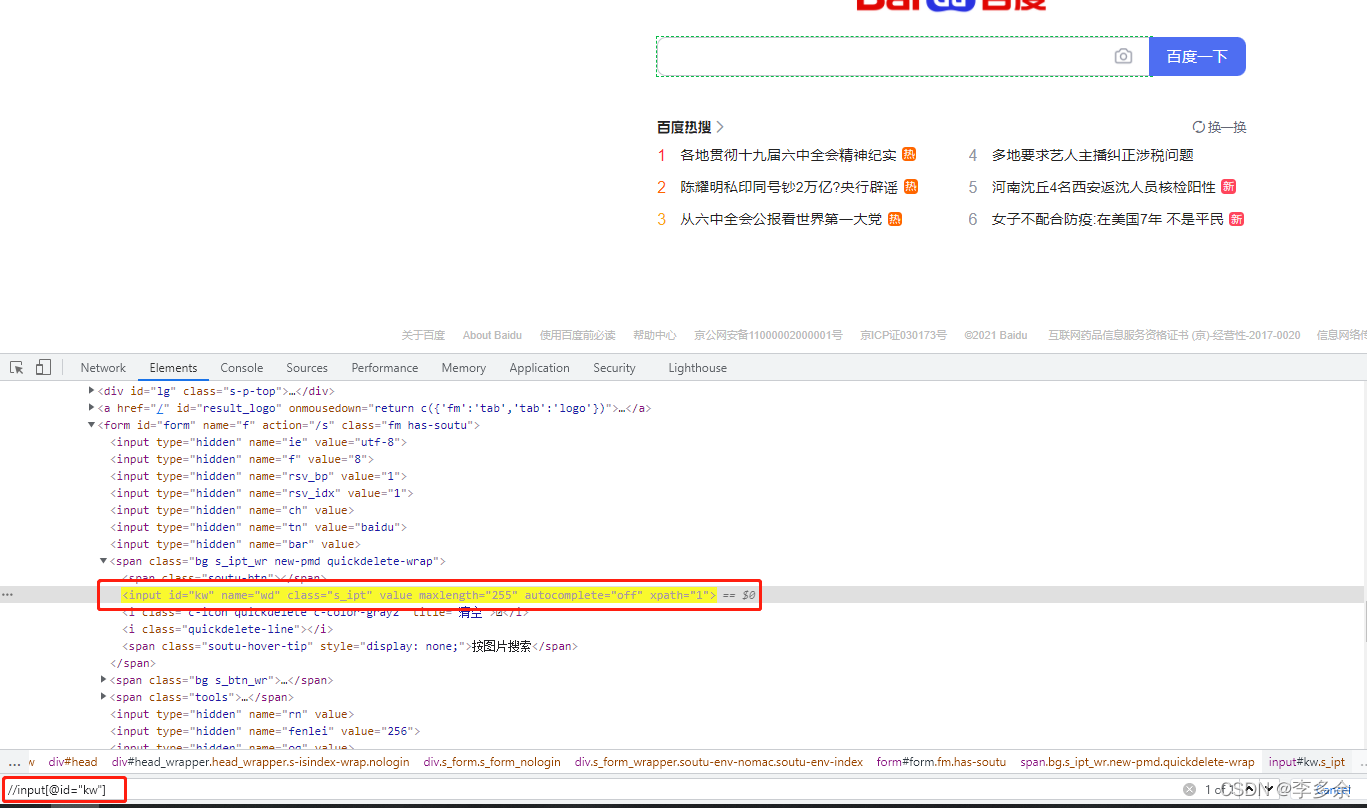
部分属性值匹配
使用部分属性值匹配(也称为模糊方法定位)属性值如果太长或网页中的元素属性动态变化,
可以使用此方法元素属性值开头包含内容:starts-with()
driver.find_element_by_xpath("//a[starts-with(@name,'tj_trhao')]")
元素属性值结尾包含内容: substring()
driver.find_element_by_xpath("//a[substring(@name,9)='123']")
元素属性值结尾包含内容:contains()
driver.find_element_by_xpath("//a[contains(@name,'hao')]")
- 示例代码
import time
from selenium import webdriver
driver = webdriver.Chrome()
url = "http://www.baidu.com"
driver.get(url)
# 4.动态元素的识别 http://news.baidu.com
# 4.1 元素属性开头的内容: starts-with()
driver.find_element_by_xpath('//a[starts-with(@href,"http://news")]').click()
# 4.1.2 元素属性结尾包含的内容: substring() https://www.hao123.com substring(@href)=""
driver.find_element_by_xpath('//a[substring(@href,13)="hao123.com"]').click() # 13 从第13个元素开始取
# 4.1.3 元素属性中间包含的内容: contains()
driver.find_element_by_xpath('//a[contains(@href,"hao123")]').click()
动态元素识别
- 示例代码
# -*- coding: utf-8 -*-
# @Time : 2021/12/22 15:08
# @Author : Limusen
# @File : demo_ui_03
import time
from selenium import webdriver
driver = webdriver.Chrome()
url = "http://www.baidu.com"
driver.get(url)
# xpath定位方式
# 4.动态元素的识别 http://news.baidu.com
# 4.1 元素属性开头的内容: starts-with()
driver.find_element_by_xpath('//a[starts-with(@href,"http://news")]').click()
# 4.1.2 元素属性结尾包含的内容: substring() https://www.hao123.com substring(@href)=""
driver.find_element_by_xpath('//a[substring(@href,13)="hao123.com"]').click() # 13 从第13个元素开始取
# 4.1.3 元素属性中间包含的内容: contains()
driver.find_element_by_xpath('//a[contains(@href,"hao123")]').click()
# 5.元素文本在xpath中可以通过text() 函数
# driver.find_element_by_xpath('//a[text()="新闻"]').click()
time.sleep(2)
driver.quit()
总结
这一章内容主要讲述的是什么是xpath定位,以及xpath定位的几大方法,大家可以用实操进行查看或者练习,有什么问题可以联系我
下一章节我们将讲述一下css定位
代码地址
https://gitee.com/todayisgoodday/PythonSelenium
CSDN地址
https://blog.csdn.net/weixin_42382016/category_11566096.html