需求:
1.读取一个xx.TXT格式的文件,内容含英文字符,标点,以及一些特殊符号。
2.统计英文单词在文本出现的次数。
3.将结果显示出来。
设计分析:
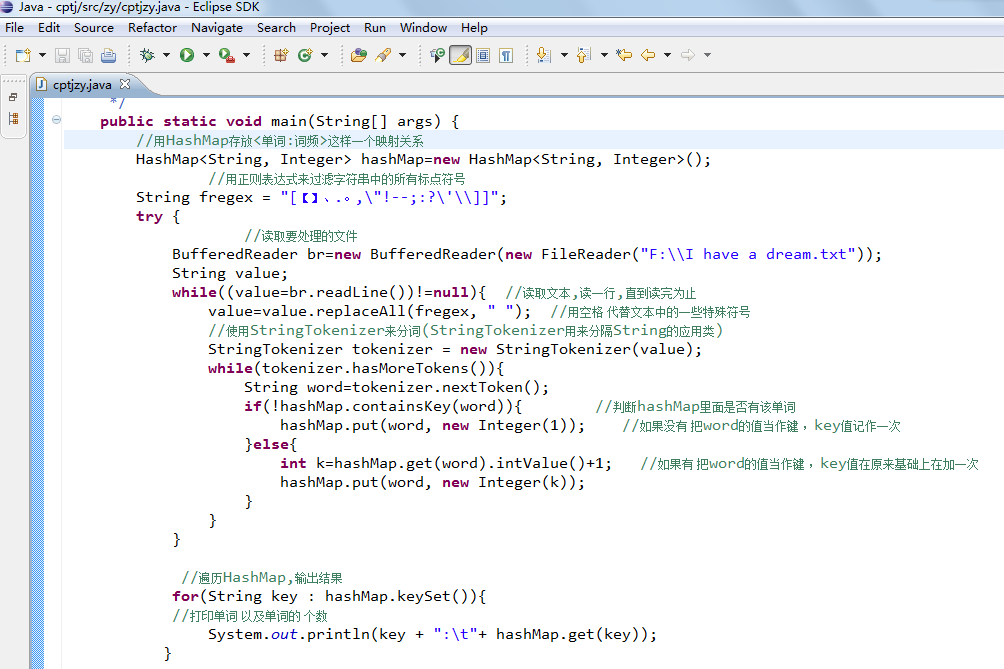
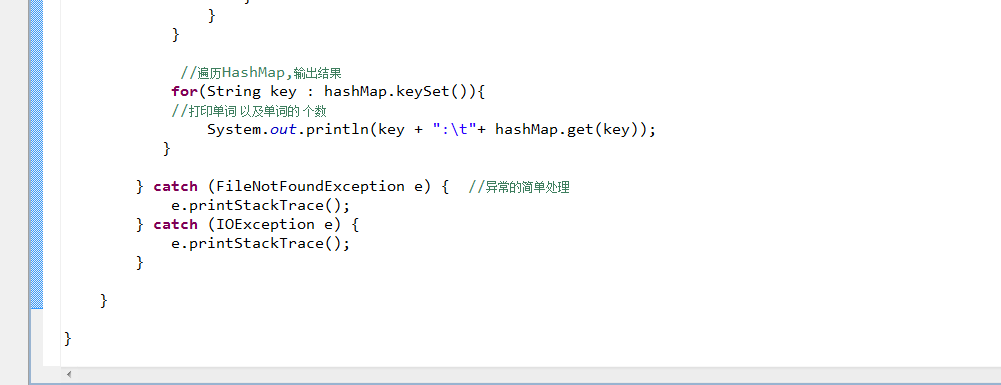
1.读取文件使用BufferedReader类按行读取。
2.定义一个正则表达式过滤字符串符号。
3.创建hashmap。
4.使用StringTokenizer来分词。
5.把分的单词加入haspmap存储的键值对。
6,遍历HashMap输出结果。
代码图示:
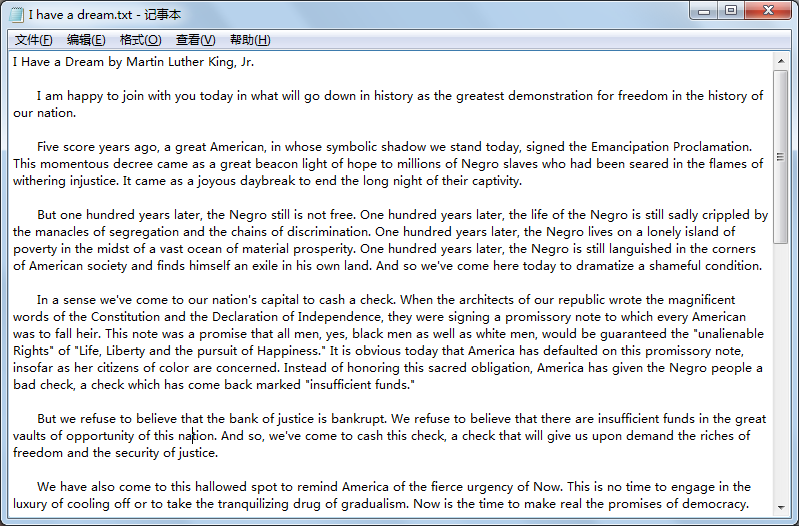
读取的文档:
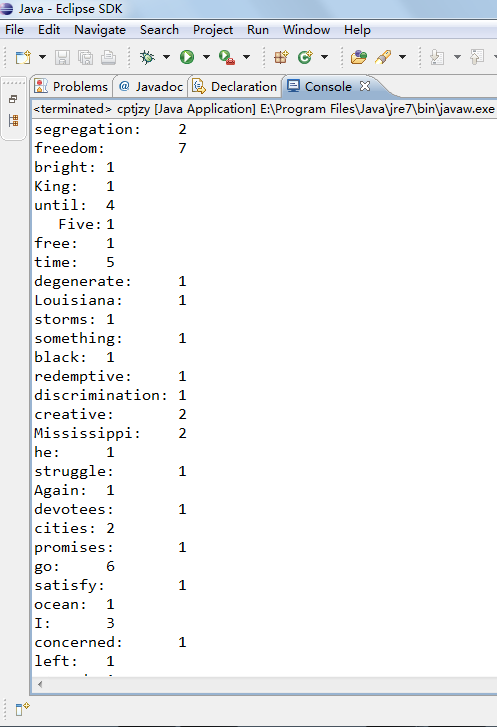
运行结果部分图示:
总结:
在完成这次作业的过程中,不说是千辛万苦,也可说是历经万难了。
首先,由于基础实在太差,刚开始就是上网上搜教程啊,看视频啊,查书啊,问同学啊。
之后,就是学习,参考,编码,修改。
经历了N次的error error error后。
终于,在run出结果的那一刻,实在是兴奋呐,当然还是有很多的不足。
对我来说,这只是一个开始,之后的学习之路还很远。加油吧!