一.概念
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
大规模数据处理时, MapReduce 在三个层面上的基本构思 。
如何对付大数据处理:分而治之
对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略。
上升到抽象模型: Mapper 与 Reducer
MPI等并行计算方法缺少高层并行编程模型,为了克服这一缺陷,MapReduce借鉴了Lisp函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型。
上升到构架:统一构架,为程序员隐藏系统层细节
MPI等并行计算方法缺少统一的计算框架支持,程序员需要考虑数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统
层面的处理细节。
不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算!
序列化是指将结构化的数据转化为字节流以便在网络上传输或写入到磁盘进行永久存储的过程,反序列化是指将字节流转换为结构化对象的逆过程。序列化常见应用场景:进程间通信和永久存储。
Hadoop中,序列化要满足:紧凑,快速,可扩展,支持互相操作。Hadoop中使用了自己的序列化格式Writable。它绝对紧凑、速度快、但不容易扩展。
自定义数据类型:
实现Writable接口,以便该数据能被序列化后完成网络传输或文件输入/输出。
如果该数据需要作为主键key使用,或需要比较数值大小时,则需要实现WritableComparable接口。
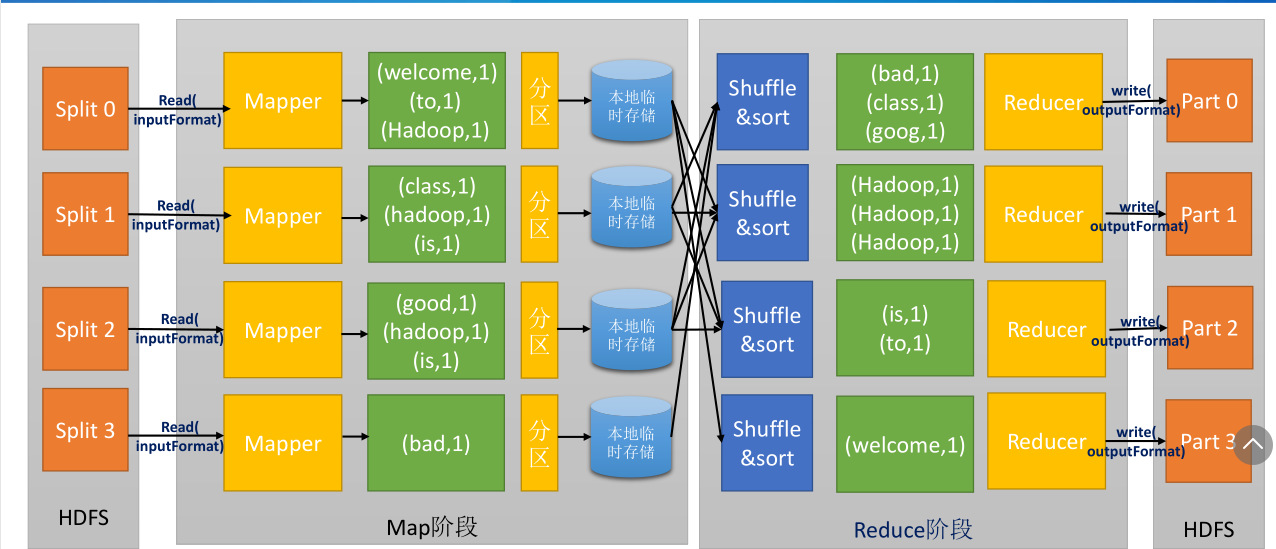
集群上最紧俏的资源便是网络带宽,因此尽量减少map和reduce阶段的网络传输对MapReduce的性能提升是很重要的。Hadoop为map任务的输出指定了一个合并函数(combiner),合并函数的输出作为reduce的输入。Combiner是的map的输出结果更加紧凑,同时减少了写磁盘和网络传输的数据量。 Combiner 又称为Local Reducer 。