聚类算法:
对于数值变量,k-means eg:k=4,则选出不在原数据中的4个点,计算图形中每个点到这四个点之间的距离,距离最近的便是属于那一类。标准化之后便没有单位差异了,就可以相互比较。
对于分类变量,k-mode:
对于数值和分类变量:k-prototype
连续变量与分类变量的权重,K=1则等权重;K<1则分类变量;K>1则数值变量。
PAM:两种因素排序,坐标是(a,b),若k=2,则在其中(通过计算原数据集某一类所有点到某一点距离最短找到该点)选出2个点,计算图形中每个点到这四个点之间的距离,距离最近的便是属于那一类,没有方向性。
AGNES
DIANA
Cluster之间的比较
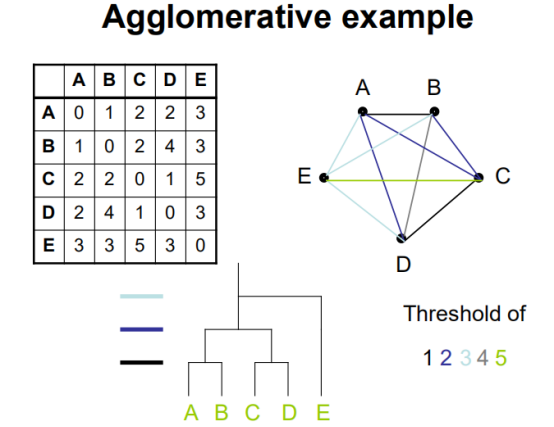
通过各种距离计算方式将变量联系在一起,成为聚类的依据。
Hierarchical cluster:将每个变量的不同因素(a,b,c,d,e,f,g)描点成网络,网络变成矩阵(其中网络权重(距离)为矩阵处数值),矩阵变成树形图。
判别函数:
回归是连续变量x解释连续变量y
方差分析是分类变量x解释连续变量y
判别分析(DA)是连续变量x解释分类变量y
使用DA的前提:
样本量是因素种类的4-5倍。
正态性即数据总体是正态分布。
方差齐性即各方面保持均匀。
判断独立性VIF膨胀系数
线性判别函数不够用时,使用线性平方判别函数。

即DA使用判别函数作为分类依据,是有目标的supervised。Cluster使用距离作为分类依据,是没目标unsupervised。