博客链接:
深入浅出 KNN算法(包括基础知识)
深入浅出 广义线性模型
- 概述
-
人工神经网络(Artificial Neural Networks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connection Model),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。(百度百科)
-
注:
要搞清楚深度学习机器学习的关系

事实上多重神经网络算法就是所谓的深度学习
- 原理
- 参见之前的一篇博客:Machine Learning Note Phase 2
- 或者这里也有一篇深度学习介绍
- 事实上,神经网络算法并没有多么“高明”,在此次人工智能浪潮中它能够脱颖而出就在于,它能够充分的利用现代计算机的强大算力,如此去完成许多看起来不可思议的事儿。
- 神经网络的非线性矫正
- 插到这里可能会显得比较突兀,如果你没有看博客:Machine Learning Note Phase 2的话。

如果隐藏层只是线性模型的加权求和的话,那么不能让神经网络变得神奇,但是生成隐藏层之后,我们对它进行一定的处理(把本来是线性的变成不是线性的)就使它拥有了化腐朽为神奇的力量。
这里主要有两种处理方法:
-
双曲正切处理(tanh)
-
非线性矫正(relu)
直观展示:
import numpy as np
import matplotlib.pyplot as plt
line = np.linspace(-5,5,200)
plt.plot(line,np.tanh(line),label="tanh")
plt.plot(line,np.maximum(line,0),label="relu")
plt.legend(loc="best")
plt.xlabel("X")
plt.ylabel("relu(x) and tanh(x)")
plt.show()
结果:

分析:
tanh(x)可以把x的值压缩到-1~1 之间,很美,无论是数学上还是图案上,当然还有其它好处,以后分析
而relu(x)则比较野,它索性将所有小于0的全部看作0,大于0的带入y=x中。虽然看起来不是很美,但是在实
际应用中却能提高运行速度,并且拟合的也不错
4.神经网络的参数设置
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
wine = load_wine()
X = wine.data[:,2]
Y = wine.target
x0,x1,y0,y1 = train_test_split(
wine.data,wine.target,random_state=0)
mlp = MLPClassifier(solver="lbfgs")
mlp.fit(x0,y0)
结果:
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=None, shuffle=True, solver='lbfgs', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False)
分析:
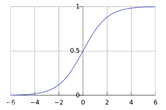
activation:非线性化办法
有四种 relu,tanh,logistic,identity。relu和tanh已经说过了,logisic和tanh比较像,tanh能将数值
压缩到-1~1之间,logistic能够将数值压缩到0~1之间
如图:
alpha:L2正则化参数
与线性模型的L2正则化参数一样,数值越大,正则化程度越高,默认为0.0001
hidden_layer_sizes:隐藏层的size
默认是只有应该隐藏层,并且节点数是100
如果设置hidden_layer_sizes=(10,10),那么就意味着模型中有两个隐藏层,并且每层都有10个节点
每个隐藏层的节点数越多,意味着模型的分割曲线越平滑
同样能做到这一点的还有:增加隐藏层的层数,将activation项改成tanh,调整alpha项
事实上不难理解,Right?
- 神经网络实力–手写识别实例
- MNIST手写数据集
MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。 - 实例:
- 总结
神经网络可以从超大的数据集中获取信息,并且建立起极为复杂的模型,所以在计算能力充足,且参数配置合适
的时候,神经网络可以比其他机器学习模型算法表现更加的优异。但是它的问题也很突出,如模型训练的时间比
较长,对数据预处理的要求比较高。
对于特征单一的数据集来说,神经网络的表现不错, 但如果数据集中的特征差异比较大的话,随机森林或是梯
度上升随即决策树等基于决策树的算法的表现会比较好,
神将网络调参:
隐藏层的节点数约等于训练数据集的特征数量,但是一般不要超过500。开始训练模型的时候,让模型尽可能的
复杂但,然后利用alpha来提高模型的表现


