此作业要求参见:https://edu.cnblogs.com/campus/nenu/2019fall/homework/6583
代码地址:https://e.coding.net/yangtianyu/cptj.git
词频统计 SPEC 20180918
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
重点:这个看起来相对简单只要按顺序检索字母即可,然而对我相对困难的地方是需要将单字母和标点符号区分开。多次重复的单词的记为1次。
代码:判断是否是字母
inline int is_alphabet(char c) { if (c >= 'a' && c <= 'z' || c >= 'A' && c <= 'Z') return 1; else return 0;
执行效果:

功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
重点:如何将进行命令行输入这个功能实现,因为在这之前因为自己练习不够,没有见到过这类要求,需要查一些资料并需要尝试实践,且这个功能关系到整个功能的实现,对专业知识的掌握不牢固会严重影响进度。
代码:
if (strcmp(argv[1], "-f") == 0) { if (_access(argv[2], 0) == -1) { printf("'%s' not found! ", argv[2]); return -1; } char *read_file = open_file(argv[2]); count_words(read_file); return 0; }else if (strcmp(argv[1], "-d") == 0) { char *read_file, *read_tmp; if (!(read_file = (char *)malloc(MAX_MUTI_LENGTH))) { printf("malloc error! "); return -1; }
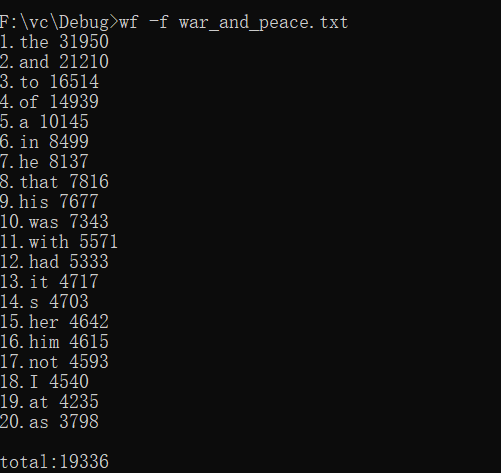
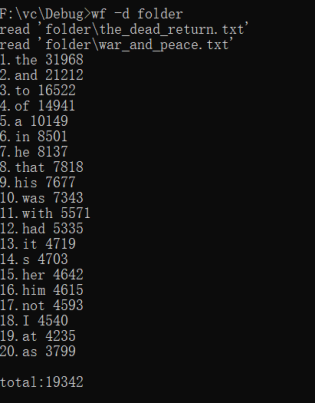
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
重点:要做批量文件处理,让用户输入文件路径,不要输入具体文件名称。遍历文件夹下所有文件,把需要处理的都放在文件夹下,就会遍历每一个文件,把每一个文件的单词都进行词频统计。重复的记一次。
代码:
long hFile=0; struct _finddata_t fileinfo; string p; if ((hFile = _findfirst(p.assign(argv[2]).append("\*").c_str(), &fileinfo)) != -1){ do{ if (!(fileinfo.attrib & _A_SUBDIR) && strcmp(fileinfo.name, ".") != 0 && strcmp(fileinfo.name, "..") != 0){ char path[MAX_PATH_LENGTH]; sprintf(path, "%s\%s", argv[2], fileinfo.name); if (_access(path, 0) == -1) continue; printf("read '%s' ", path); open_file_dst(&read_tmp, path); } } while (_findnext(hFile, &fileinfo) == 0); _findclose(hFile); } count_words(read_file); return 0; }
执行效果:
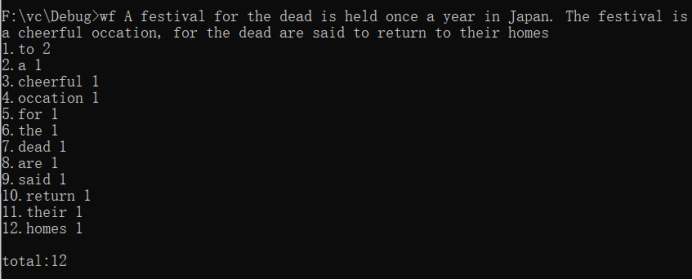
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
重点:本题与前面的区别是可以输入一整句话或者一个文档。
代码:
if (strcmp(argv[1], "-f") == 0) { if (_access(argv[2], 0) == -1) { printf("'%s' not found! ", argv[2]); return -1; } char *read_file = open_file(argv[2]); count_words(read_file); return 0; }else if (strcmp(argv[1], "-d") == 0) { char *read_file, *read_tmp; if (!(read_file = (char *)malloc(MAX_MUTI_LENGTH))) { printf("malloc error! "); return -1;
psp:
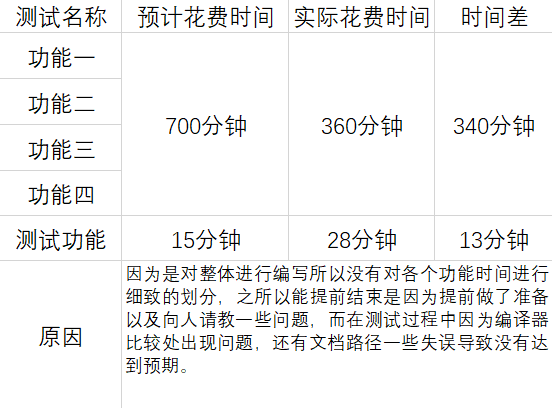
总结:(1)作业中四项小功能都是整合到数组中利用指针进行检索,虽然也能实现功能,但是执行时间上较慢,尤其是功能三就会显得更慢。方法选择上也是有待改进,这也是以后需要提高的地方。这周作业也是对自己有了很大的锻炼,在写程序过程中暴漏了非常多的缺点,我也是经过室友的指点帮助,才能完成,让我看到与能力强的同学之间的差距。不仅仅是一些语法的概念,还有逻辑思维能力,我的思想多么的有局限性。代码的执行结果并不是与老师的完全相同,这就好比是无法达到客户的需求一样,这方面也是要加强练习。
(2)在这次作业中又了解到了与代码有关的网站以及tortoise的使用,作为一名计算机专业的学生,平时还是要多关注一下这些方面的应用。