一、基本概念
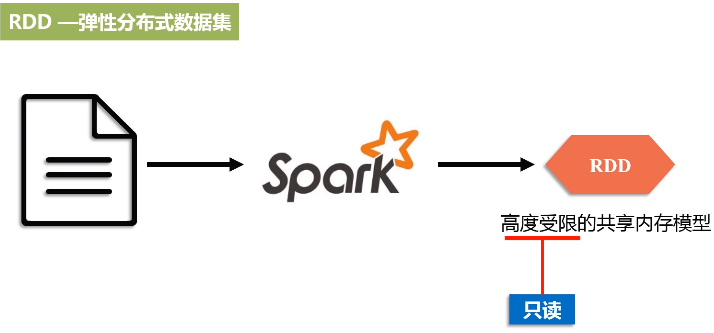
1.RDD
Resillient Distributed Dataset 弹性分布式数据集
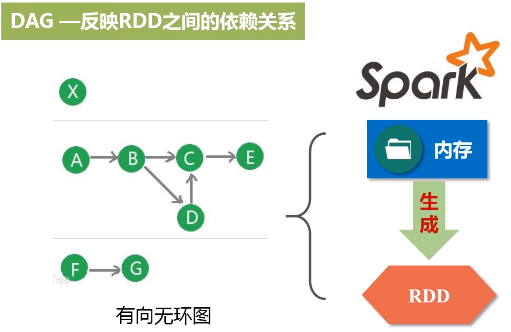
2.DAG
反映RDD之间的依赖关系
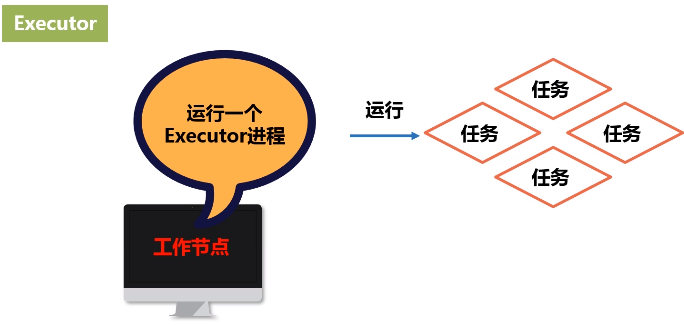
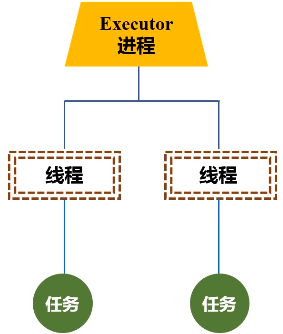
3.Executor
进程驻守在机器上面,由进程派生出很多的线程,然后去执行任务。
4.应用application

5.任务
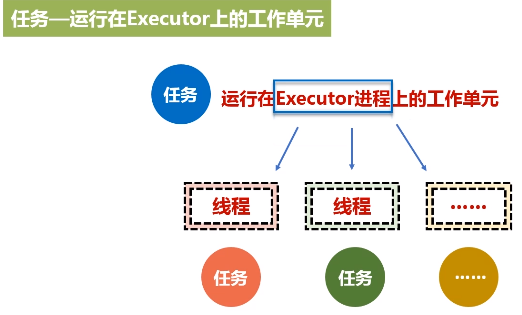
6.作业Job
一个应用程序提交之后,会生成若干个作业,每个作业,会被切分成很多个任务子集,每个任务子集叫一个阶段。所以说一个作业包含多个RDD以及作用于相应RDD上的各种操作。

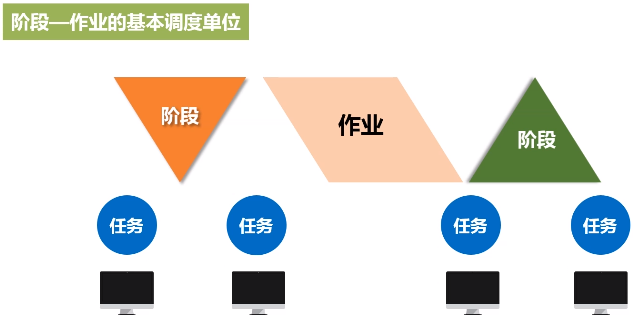
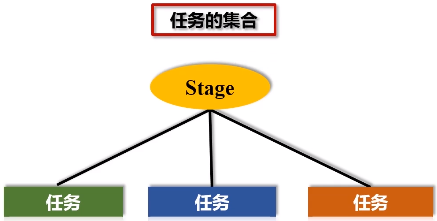
7.阶段stage
阶段是作业的基本调度单位,一个阶段是很多个任务的集合
二、架构设计
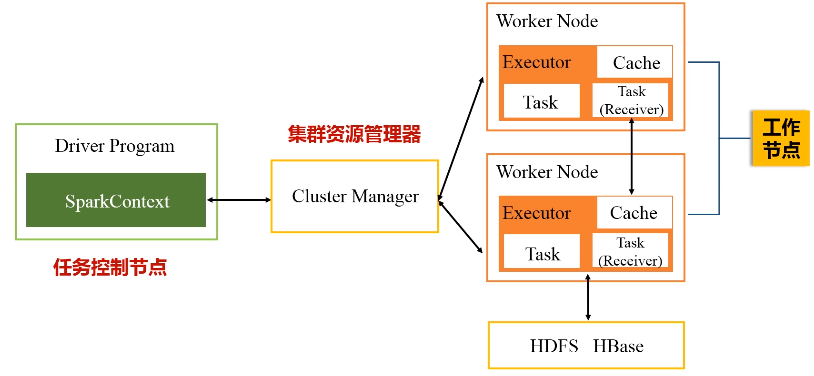
1.Driver program
功能:任务控制节点,应用程序的“指挥所”
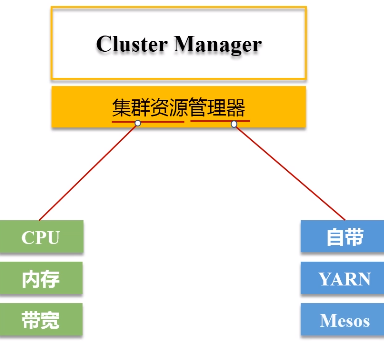
2.Cluster Manager
功能:集群资源管理器
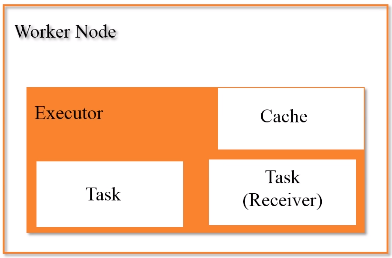
3.Worker Node 工作节点
每个工作节点都会有executor进程,每个进程派生出多个线程,每个线程具体去执行相关的任务。

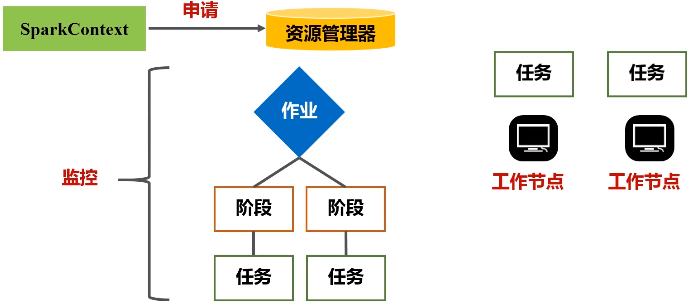
一个应用在执行时候,需要一个管家节点(任务控制节点Driver),然后应用会根据相关代码,最终会被生成若干个作业,一个应用提交以后,它会被分成很多作业,具体生成多少个作业是取决于里面的相关代码。
一个任务会被切分成不同的作业,一个作业会被切分成不同的阶段,每一个阶段包含了很多个任务,这些任务会被派发到不同的工作节点上,就是workernode去执行。
每次去执行应用时,Driver节点会向集群的资源管理器申请资源,因为计算需要CPU内存,申请到资源以后,就会启动相对应节点的Executor进程,然后会向对应节点的Executor进程去发送应用程序代码和文件,就在它上面派发出线程去执行具体任务。
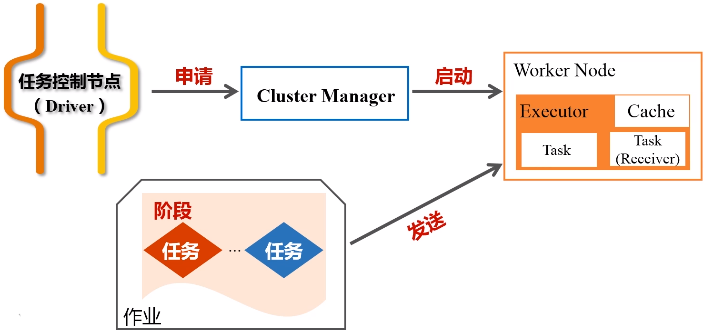
执行结束后, 会把运行结果再返回给Drive节点,然后返回给用户,或者写入到文件系统HDFS或者数据库

三、Spark运行基本流程
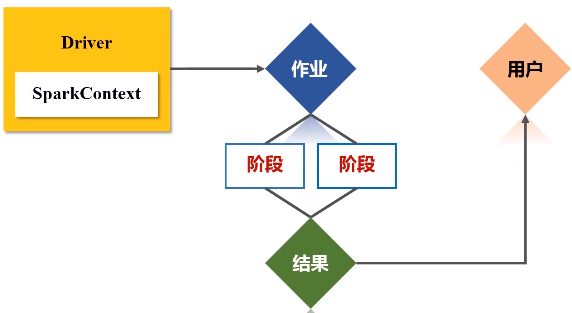
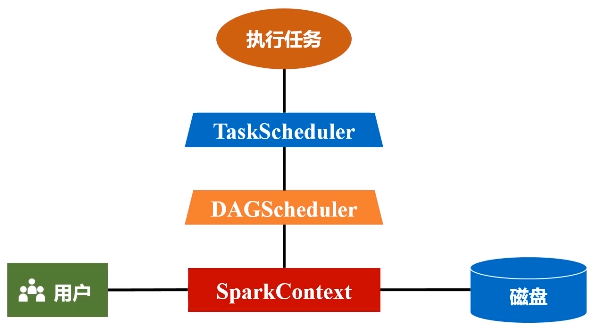
(1)首先去构建起一个基本的运行环境,要构建集群,应用程序提交的时候要先给它确定运行应用的主节点(Driver节点),一旦确定好(指挥所建好之后),会由Driver节点给它派生一个SparkContext对象。

(2)这个对象负责向资源管理器申请资源,然后负责把整个作业分解成不同阶段,并且把每个阶段的任务把它调度到不同的节点上面去执行。执行过程它还要进行监控,万一失败了,他要负责恢复回来。
资源管理器收到资源请求后,会为Executor的进程去分配资源(CPU、内存)去执行,之后启动Executor进程
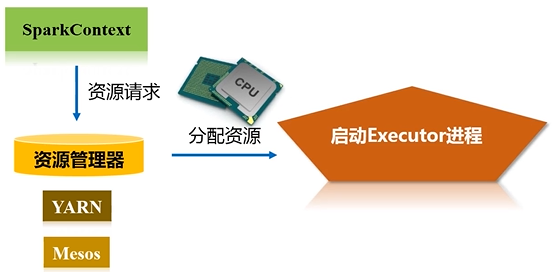
executor进程是驻留在各个不同的workernode上面的,可能有几百上千台机器workernode上面

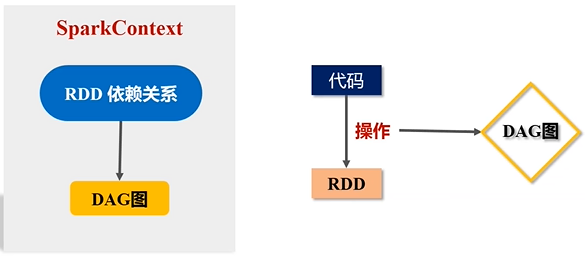
(3)SparkContext对象要根据RDD的依赖关系构建一张DAG图
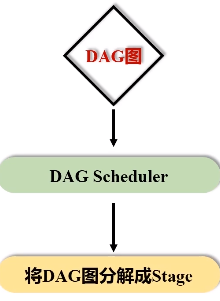
这个图会被提交到叫DAG Scheduler的模块进行解析,它要负责把这张完整的DAG图,把它切成很多不同的阶段,每个阶段里面都包含若干个任务,每个阶段里面都包含多干个任务
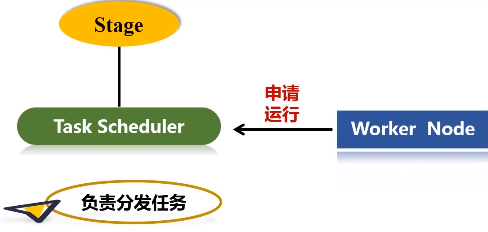
得到一个又一个阶段以后,再把这么一个阶段提交给下一个Task Scheduler,task scheduler具体负责把任务到底分发到哪个节点上面去。整个分发过程并不是说task scheduler拿到任务就往外扔,而是各个worker node上面那些executor会主动地向这个task tracker去申请运行任务。然后task tracker就会把相关的任务,根据它申请的情况,扔到相对应的worker node上,让executor进程去派送线程去执行。
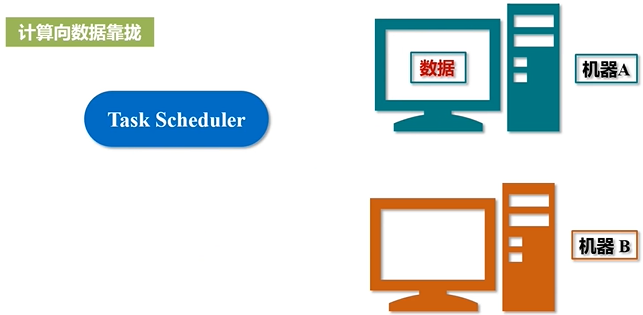
任务分发的基本原则:必须要保证计算向数据靠拢
数据在哪个节点上面,就优先把计算扔到数据所在节点,完成本地化的处理
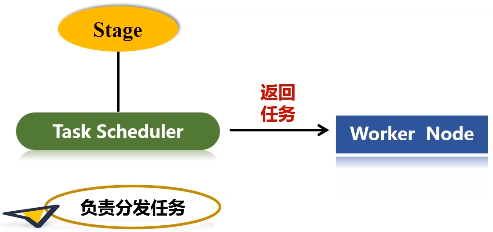
(4)任务在executor上面运行以后,它会得到结果,结果又反馈给TaskScheduler,再用Task Scheduler往上传递给DAG Scheduler,然后由Spark Context对象再做一个最后的处理,或者返回给用户看,或者写入到HDFS。

Spark Context是整个运行程序的指挥官,而且,它也代表了整个应用程序连接集群的通道。

四、RDD的设计与运行原理
为什么要有RDD?
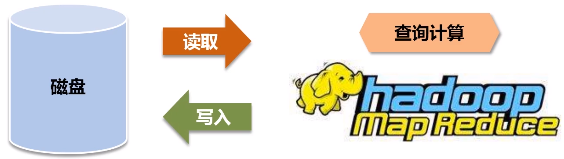
Hadoop处理不了迭代式场景,每次都要从磁盘读取或写入数据,这对于频繁去访问某个数据集的场景不适用的,这会产生很大的磁盘IO开销,还会带来序列化和反序列化开销()。


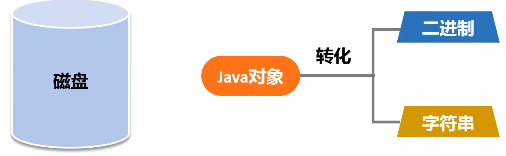
序列化:本来在内存中生成了Java对象,现在要把它写到磁盘,肯定不能以对象来写,要把他写成二进制或者字符串,比如说想把Java对象传递给另一台机器,或者保存到磁盘里面去,要么写成JSON格式文件传输过去,要么写成二进制文件传输过去,肯定不会把对象传过去。所以,把对象转成可以保存的和传输的格式的过程就叫序列化


1.RDD运行原理(设计背景)
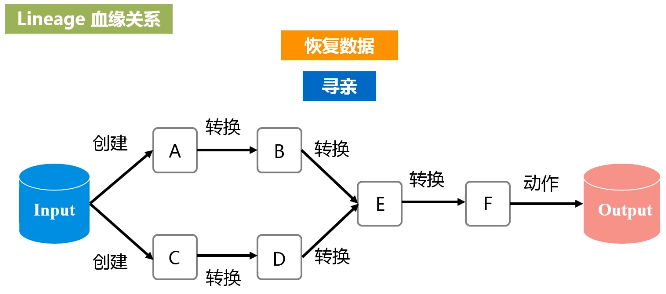
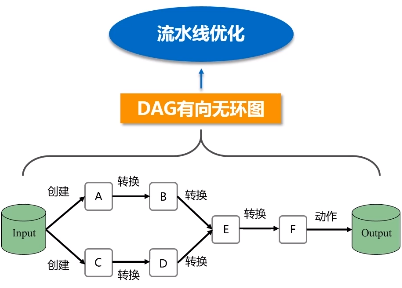
RDD提供了抽象的数据结构,就是不用担心底层数据的分布特性,只需要把具体应用逻辑表达成一系列转换,然后不同的RDD之间转换,形成依赖关系,形成一个DAG图。形成DAG图,是可以实现优化的,它生成图的目的,是为了后期实现可能的优化,有可能它优化不了,但很多情况下都是可以优化的。优化就是实现管道化或叫流水线化。
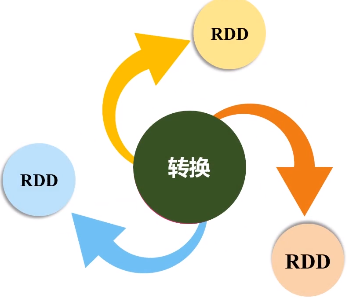
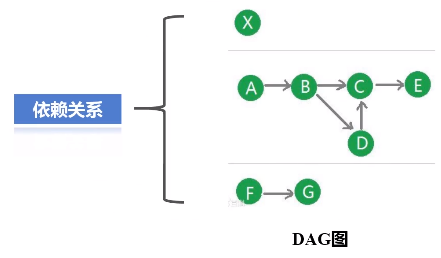
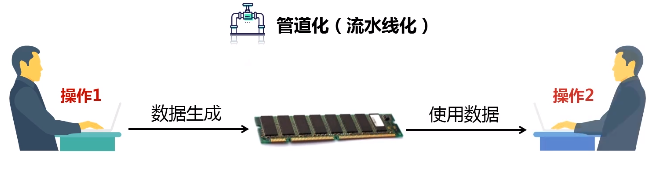
流水线化可以避免数据落地,不用不断地写底层磁盘,就形成流水线。这个操作一结束,马上把操作的输出,作为另外一个操作的输入,不用写到磁盘交给另外一个操作。所以说,有了RDD这种设计的抽象之后,再用DAG这种形式去组织以后,可以发现在很大程度上就可以避免数据频繁落地(“磁盘”)。
2.RDD概念

RDD本质上是一个只读的分区记录集合。比如,一个很大的数据集文件,原来是保存在磁盘上面,把它读进来,加载到内存当中生成一个RDD,数据集很大,单机内存肯定放不下,需要把一个RDD非常很多个分区,每个分区放在不同的机器上,比如,分区1放在机器1,分区2放在机器10,这样就变成一个分布式的对象集合,所以一个RDD在逻辑上是一个完整的抽象,但实际上它的数据会被分区,不同的分区会被放到不同机器上。所以说,每个RDD的每个分区就是一个数据片段集合,是一个子集。
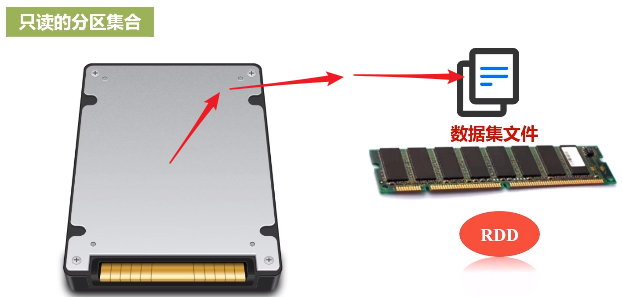
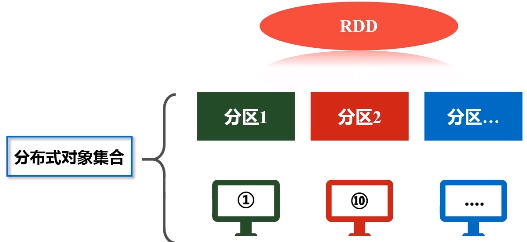
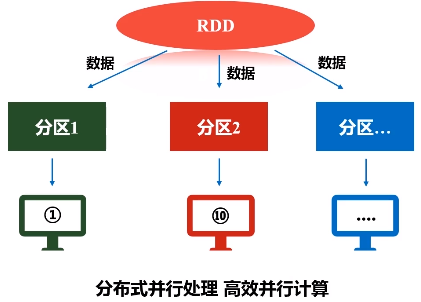
RDD提供了一种高度受限(只读)的共享内存模型,一旦把RDD加载进来,生成内存当中的数据集合,一生成就不能修改这叫高度受限,

RDD是在转化的过程中可以改,但一旦生成新RDD,这个RDD又是不能改的。
3.RDD操作

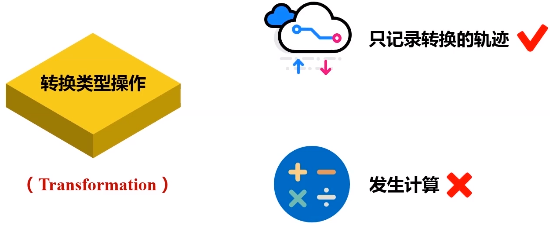
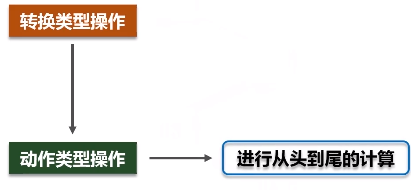
(1)转换类操作
只记录转换的轨迹,不发生计算
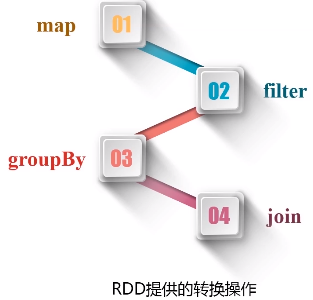
RDD提供粗粒度的转换操作:map、filter、groupby、join
粗粒度修改:一次只能针对RDD全集进行转换,不支持有针对性的转换( spark不支持细粒度修改,如网页爬虫。)
高度受限的共享内存模型会不会影响表达能力?

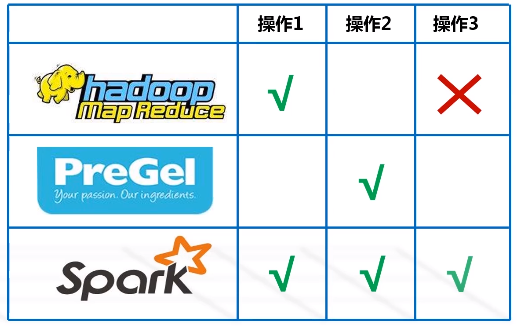

(2)动作类型操作
进行从头到尾的计算
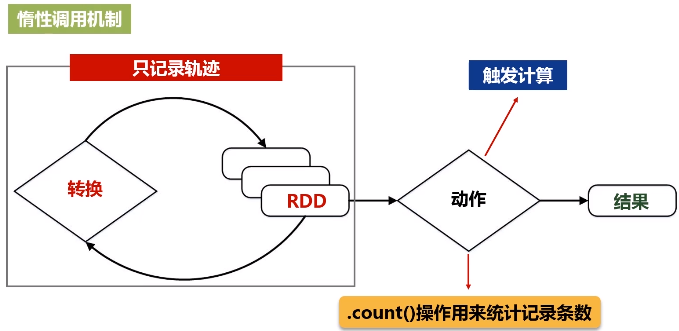
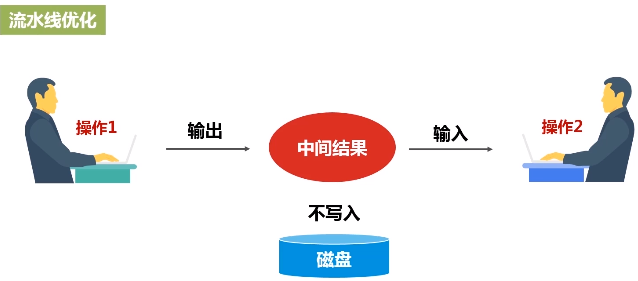
流水线优化:整个操作过程中,一个操作的输出就可以直接形成流水线,交给另外一个操作作为输入,不要去落磁盘。不需要保存中间结果。
4.RDD特性
(1)高效的容错性:数据丢失能恢复
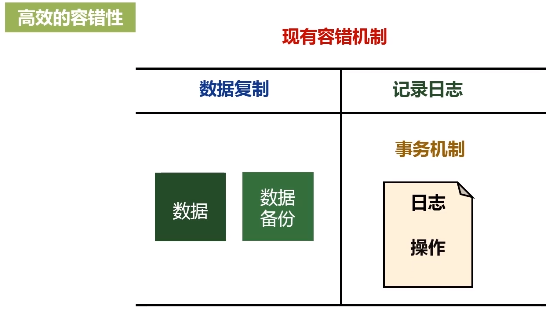

(2)性能高效:数据在内存的多个RDD之间进行传递,避免不必要的读写磁盘开销。从而避免不必要的序列化和反序列。
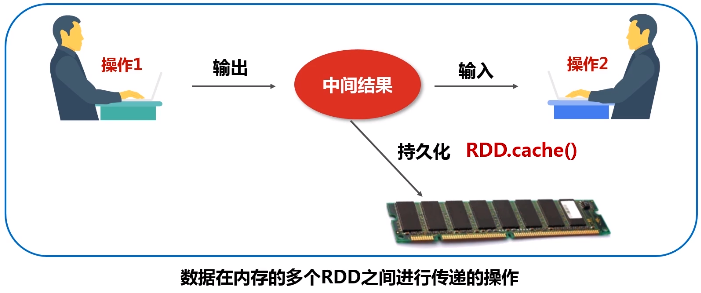

5.RDD之间的依赖关系
疑问:为什么要切,怎么切?
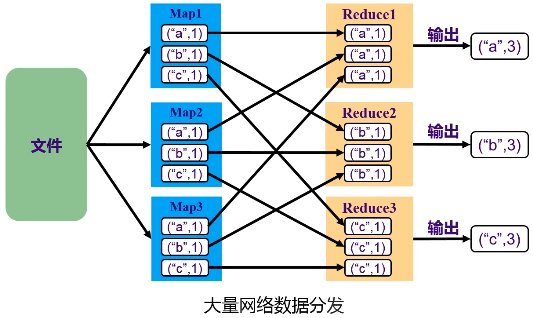
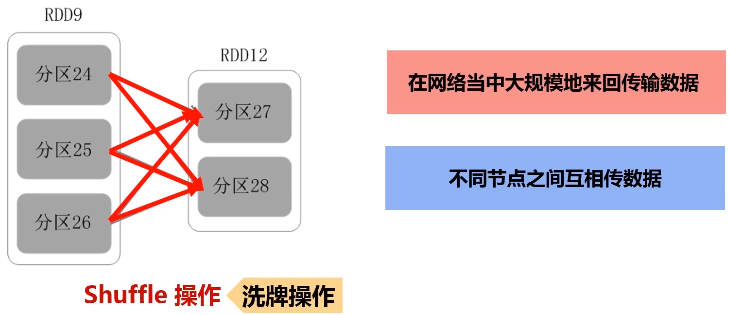
洗牌(shuffle):过程需要大量网络之间的数据分发。
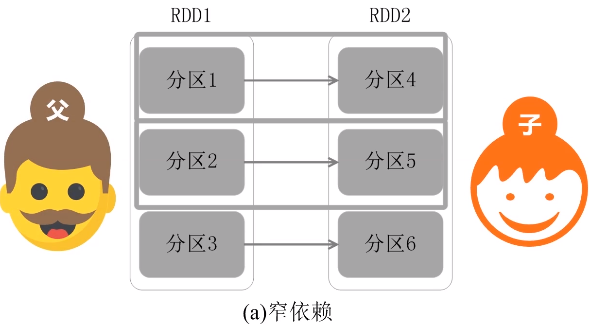
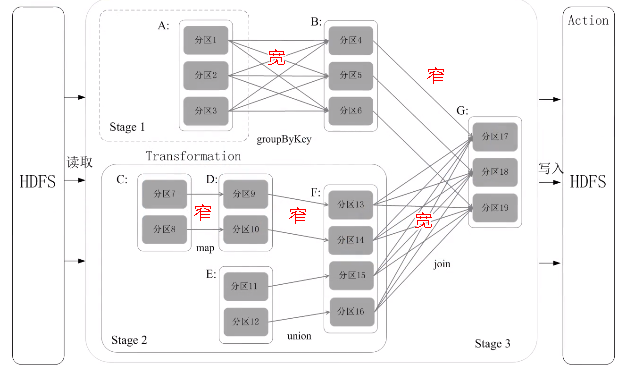
(1)怎么划分阶段?
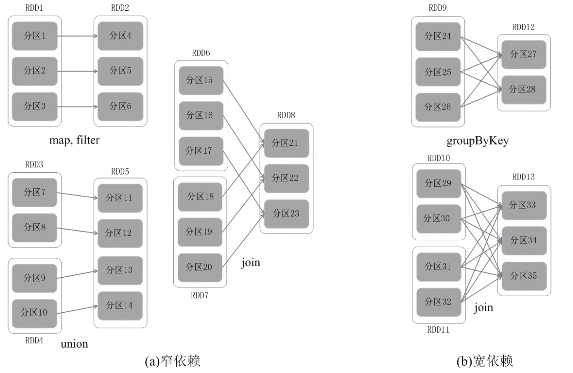
窄依赖:不划分阶段
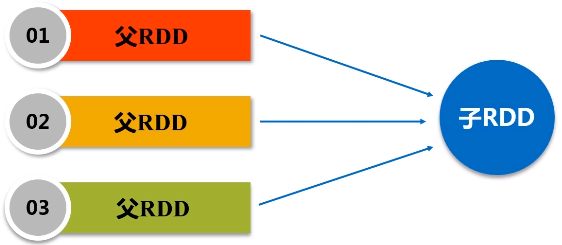
父亲对儿子,一一对应的分区关系,或者是多个父亲RDD对应一个儿子RDD的分区
宽依赖: 划分成多个阶段。只要发生了shuffle操作,肯定是宽依赖。
一个父RDD的分区对应一个儿子RDD的多个分区,发生shuffle操作。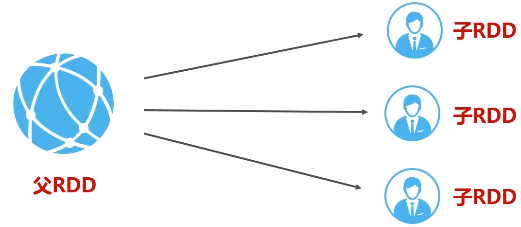
6.阶段的划分
把一个作业(DAG图)划分成多个阶段,依据就是窄依赖和宽依赖。宽依赖没办法优化,而窄依赖是可以进行优化。

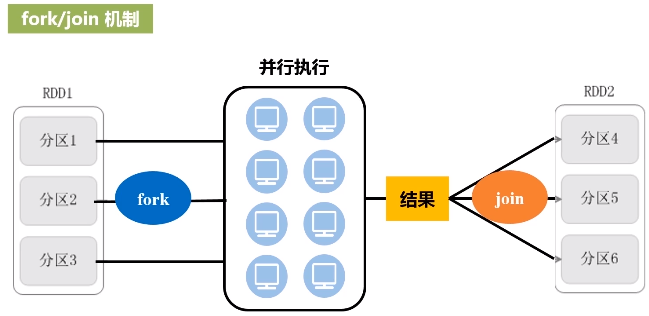
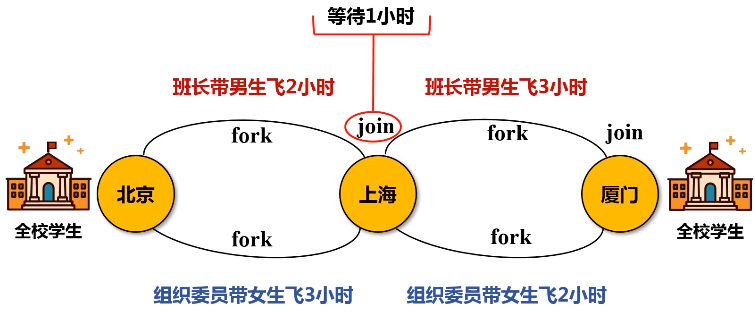
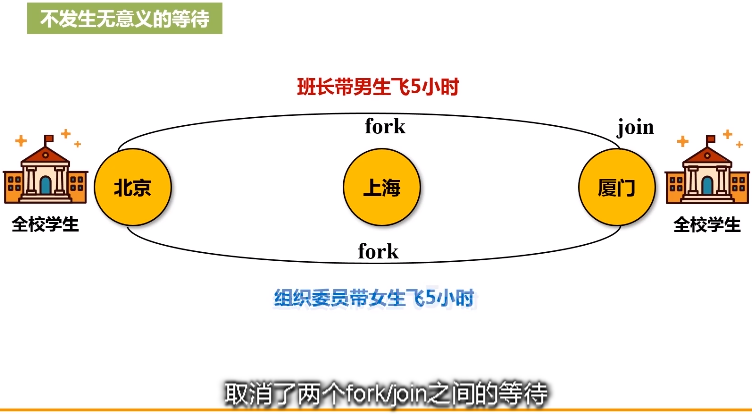
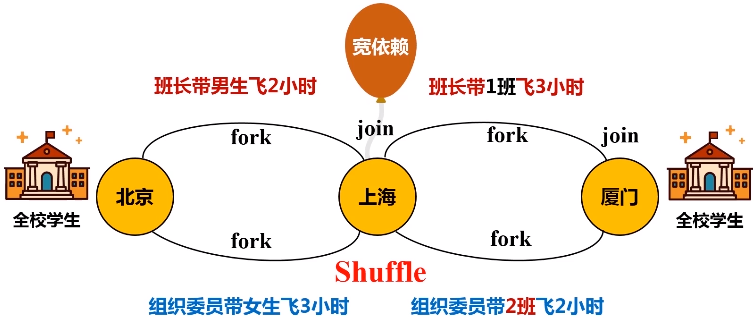
优化原理:fork和join机制
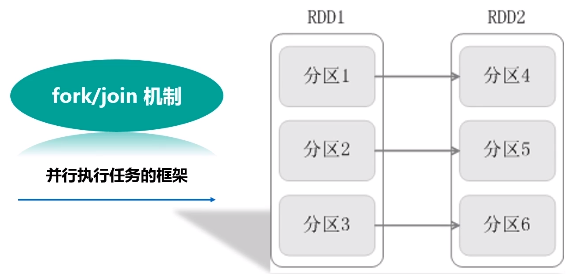
为了能够并行执行,把分区1,分区2和分区3,fork到不同的机器上去,执行完之后再把这几台机器执行的结果join起来。



7.RDD的运行过程
(1)创建RDD对象
(2)SparkContext会计算RDD之间依赖关系,生成一个DAG图
(3)DAGScheduler会把DAG图分解成很多个阶段,每一个阶段都包含了若干了任务集合,这些任务会被Task Scheduler调度,扔给不同的Worker Node去执行。Worker Node上面有Excutor进程,每一个Excutor进程都会派生出很多的线程,每个线程就会具体去执行任务,最终把任务再发返回给Task Scheduler,再由DAGScheduler提交给SparkContext,再由SparkContext对象将结果返回用户或写入磁盘。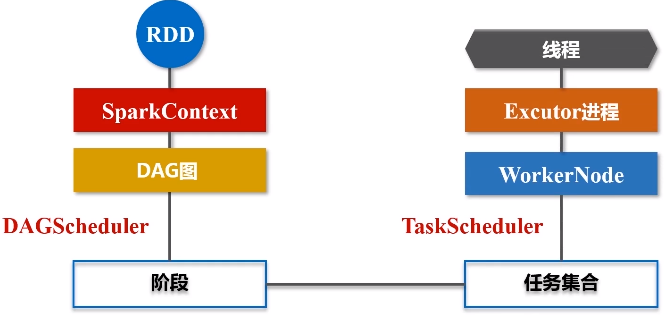
参考文献: