参考:
原理
SVM方法是通过一个非线性映射p,把样本空间映射到一个高维乃至无穷维的特征空间中(Hilbert空间),使得在原来的样本空间中非线性可分的问题转化为在特征空间中的线性可分的问题.简单地说,就是升维和线性化.升维,就是把样本向高维空间做映射,一般情况下这会增加计算的复杂性,甚至会引起“维数灾难”,因而人们很少问津.但是作为分类、回归等问题来说,很可能在低维样本空间无法线性处理的样本集,在高维特征空间中却可以通过一个线性超平面实现线性划分(或回归).一般的升维都会带来计算的复杂化,SVM方法巧妙地解决了这个难题:应用核函数的展开定理,就不需要知道非线性映射的显式表达式;由于是在高维特征空间中建立线性学习机,所以与线性模型相比,不但几乎不增加计算的复杂性,而且在某种程度上避免了“维数灾难”.这一切要归功于核函数的展开和计算理论.
支持向量机(SVM)是一种比较好的实现了结构风险最小化思想的方法。它的学习策略是结构风险最小化原则,为了最小化期望风险,应同时最小化经验风险和置信范围。
SVM 其实本质也是感知机。
最终解决的是一个凸二次规划问题,从理论上说,得到的将是全局最优解,解决了在神经网络方法中无法避免的局部极值问题。
将实际问题通过非线性变换转换到高维的特征空间,在高维空间中构造线性决策函数来实现原空间中的非线性决策函数,巧妙地解决了维数问题,并保证了有较好的推广能力,而且算法复杂度与样本维数无关。
SVM属于监督学习算法,supervised learning 流程如图所示:
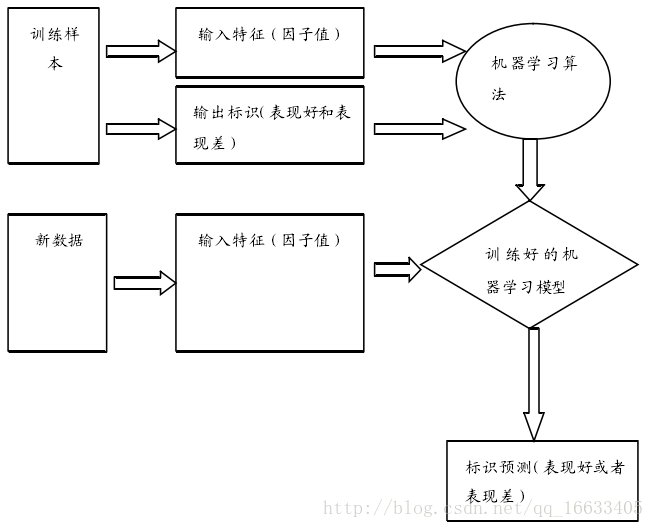
SVM => Support Vector Machine 支持向量机
SVC => Support Vector Classification 支持向量机用于分类,目的是找出分类的超平面
SVC => Support Vector Regression 支持向量机用于回归分析,目的是拟合曲线,函数回归,用于预测
SVC与SVR的区别见图:
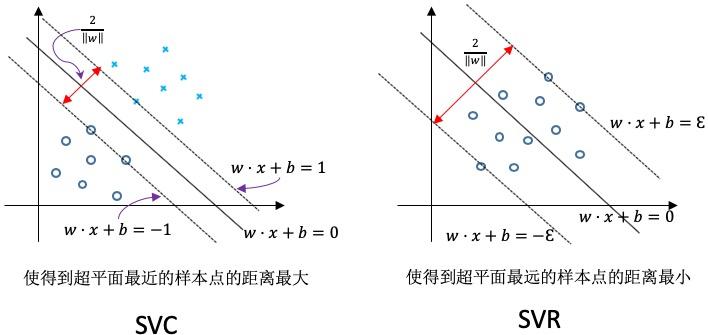
分类是找一个平面,使得边界上的点到平面的距离最远,回归是让每个点到回归线的距离最小。
python-sklearn
python中基本调用sklearn.svm中的函数实现相关功能,对应地,sklearn的SVM中有sklearn.svm.SVC()和sklearn.svm.SVR()两个方法。
scikit-learn SVM算法库封装了libsvm 和 liblinear 的实现,仅仅重写了算法了接口部分。分为两类,分类:SVC, NuSVC,和LinearSVC。回归:SVR, NuSVR,和LinearSVR 。相关的类都包裹在sklearn.svm模块中。
sklearn官方SVM API: sklearn.svm: Support Vector Machines
SVM公式原理:Support Vector Machines

实践tips:
避免数据拷贝
核缓存的大小:对于 SCV、SVR、NuSVC 和 NuSVR,核函数缓存的大小对于大型问题的运行时间有着非常大的影响。如果有足够多的内存,建议把cache_size的大小设置的尽可能的大。
设置 C:1 是一个合理的默认选择,如果有较多噪点数据,你应该较少 C 的大小。
SVM 算法不是尺度不变,因此强烈建议缩放你的数据。如将输入向量 X 的每个属性缩放到[0,1] 或者 [-1,1],或者标准化为均值为 0 方差为 1 。另外,在测试向量时也应该使用相同的缩放,已获得有意义的结果。
对于SVC,如果分类的数据不平衡(如有很多的正例很少的负例),可以设置class_weight='balanced',或者尝试不同的惩罚参数 C
底层实现的随机性:SVC和NuSVC的底层实现使用了随机数生成器,在概率估计时混洗数据(当 probability 设置为 True),随机性可以通过 random_state 参数控制。如果 probability 设置为False ,这些估计不是随机的,random_state 对结果不在有影响。
使用 L1 惩罚来产生稀疏解
SVC
分类支持向量机。参考源码。
基于libsvm库实现
训练时间复杂度为o(n^2)
训练集实例数量大(大于1万)时很难进行归一化
多分类问题采用one-vs-rest方法实现
class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)
from sklearn.svm import SVC
LinearSVC
线性SVM分类器。参考源码。
基于liblinear库实现,可以用于二类分类,也可以用于多类分类
有多种惩罚参数和损失函数可供选择
训练集实例数量大(大于1万)时也可以很好地进行归一化
既支持稠密输入矩阵也支持稀疏输入矩阵
多分类问题采用one-vs-rest方法实现
class sklearn.svm.LinearSVC(penalty='l2', loss='squared_hinge', *, dual=True, tol=0.0001, C=1.0, multi_class='ovr', fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000)
LinearSVC implements “one-vs-the-rest” multi-class strategy, thus training n_classes models.
For “one-vs-rest” LinearSVC the attributes coef_ and intercept_ have the shape (n_classes, n_features) and (n_classes,) respectively. Each row of the coefficients corresponds to one of the n_classes “one-vs-rest” classifiers and similar for the intercepts, in the order of the “one” class.
LinearSVC不会计算概率,因为没有训练这样做. 如需手动计算测试概率,使用标准logistic function进行概率估计:1. / (1 + exp(-decision_function(X))). 该方法产生形式意义上的概率(介于0和1之间的数字),但它们不会遵循任何合理的概率模型。
tips
特征标准化是指对数据的每一维进行均值化和方差相等化。这在很多机器学习的算法中都非常重要,包括SVM算法中。
Support Vector Machine algorithms are not scale invariant, so it is highly recommended to scale your data. For example, scale each attribute on the input vector X to [0,1] or [-1,+1], or standardize it to have mean 0 and variance 1. Note that the same scaling must be applied to the test vector to obtain meaningful results. This can be done easily by using a Pipeline.
参见Preprocessing data.