2. 数据库表的准备(MySQL)
1) 确认要保存的字段:
本文旨在获取妈妈网网站文章的数据,因此需要文章标题(title)、文章链接(href)、文章内容(content)和内容图片(imgs)
2) 创建数据库表
CREATE TABLE `mamawang_info` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `title` varchar(255) DEFAULT NULL, `href` varchar(255) DEFAULT NULL, `content` text, `imgs` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=627 DEFAULT CHARSET=utf8;
3) 连接数据库: 先安装ptyhon的pymysql包
import pymysql.cursors
connect = pymysql.Connect(
host='localhost',
port=3306,
user='root',
passwd='admin',
db='baby_info',
charset='utf8'
)
3. 爬取网站数据
1) 确认需要爬取的网站数据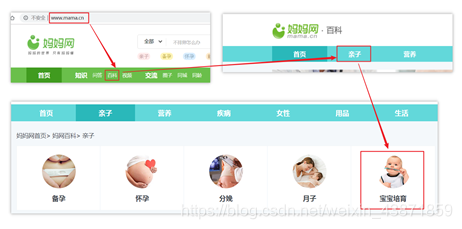
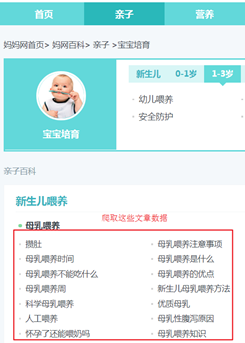
2) 研究网页结构
url = 'http://www.mama.cn/z/t1183/' response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, "html.parser") div = soup.find(class_='list-left')
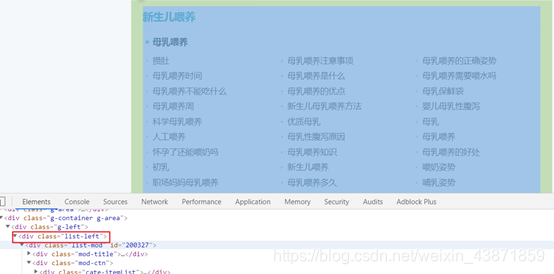
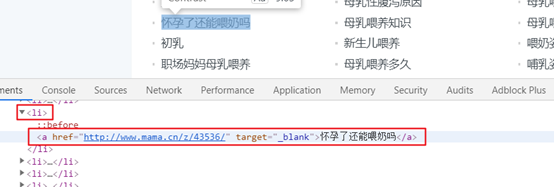
3) 编写python代码爬取网页内容(完整代码)
import requests from bs4 import BeautifulSoup import datetime import pymysql.cursors import time import os # 连接数据库 connect = pymysql.Connect( host='localhost', port=3306, user='root', passwd='admin', db='baby_info', charset='utf8' ) def get_one_page(): headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36' } # 开始时间 start_time = datetime.datetime.now() url = 'http://www.mama.cn/z/t1183/' # 图片保存路径 root = "D://reptile//images//" # 若不存在该目录,就创建该目录 if not os.path.exists(root): os.mkdir(root) response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, "html.parser") div = soup.find(class_='list-left') lists = div.find_all('li') for list in lists: title = list.find('a').string href = list.find('a')['href'] time.sleep(1) # 通过文章的url获取文章网页内容 page = requests.get(href, headers=headers) web_text = BeautifulSoup(page.text, "html.parser") contents = web_text.find_all('p') content = '' # 由于文章内容存到数据库,每条开头都有“退出”,末位都有none,因此,利用count忽略拼接第一个string和最后一个string count = 0 for i in contents: if count != 0 and count != len(contents) - 1: content = '{}{}'.format(content, i.string) count += 1 try: div_imgs = web_text.find('div', class_='detail-mainImg') imgs = div_imgs.find('img')['src'] path = root + imgs.split("/")[-1] with open(path, "wb") as f: # 开始写文件,wb代表写二进制文件 f.write(requests.get('http:' + imgs).content) except(Exception): print("抱歉,找不到图片") inset_spec_code(title, href, content, path) end_time = datetime.datetime.now() print((end_time - start_time).seconds) # 获取游标 cursor = connect.cursor() def inset_spec_code(title, href, content, imgs): try: # 插入数据 sql = "INSERT INTO mamawang_info(title,href,content,imgs) VALUES ('%s','%s','%s','%s')" data = (title, href, content, imgs) cursor.execute(sql % data) connect.commit() print('成功插入', cursor.rowcount, '条数据') except Exception: print("插入失败") if __name__ == '__main__': get_one_page()
4. 运行python文件
1) 在该python文件的同级目录下打开cmd命令,输入:python mamawang.py
2) 结果
图片下载结果
数据库结果(626条)