3.1神经网络概述
(1)神经网络每个单元相当于一个逻辑回归,神经网络由逻辑回归的堆叠起来。下图是网络结构:
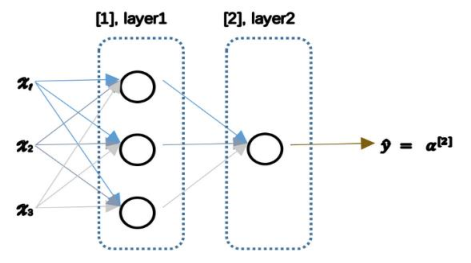
针对网络结构进行计算:
1.第一层的正向传播

2.第一层的反向传播
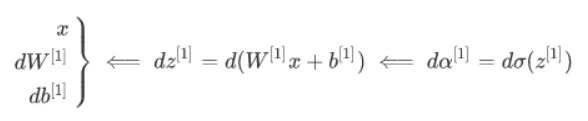
3.第二层的反向传播(正向只要把微分符号去掉即可)
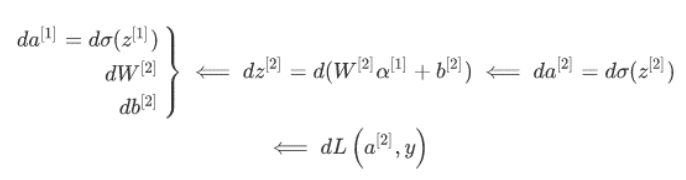
3.2神经网络的表示
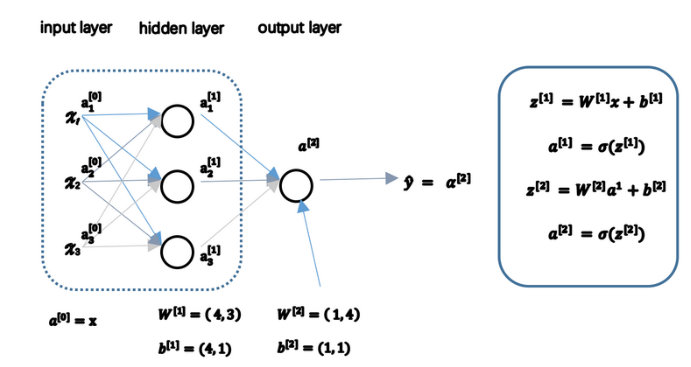
(1)神经网络各层分别较输入层、掩藏层和输出层,其中说一个网络有几层时一般不包括输入层,如下图是一个两层的网络:
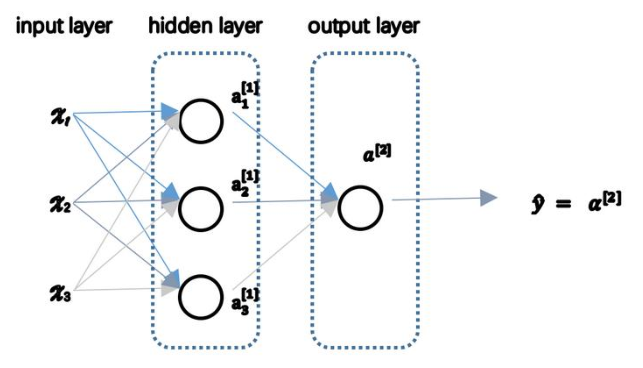
(2)a[0]chang也常用来表示输入特征,a[1]b表示第一层的输出,如第一层(不算输入层)有四个神经元,其输出为(用a表示是因为activation激活函数的缩写):
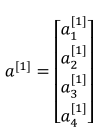
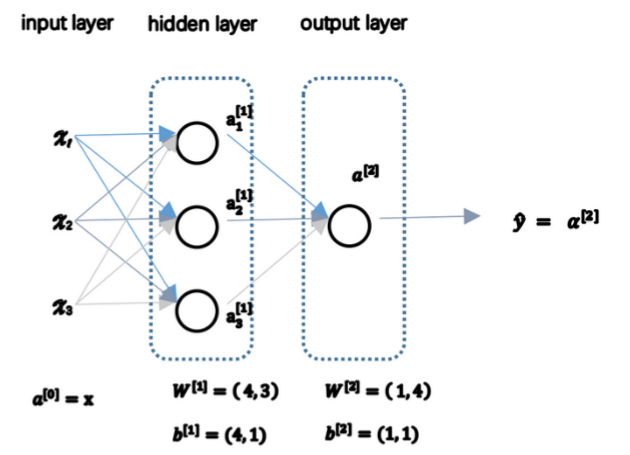
(3)关于W[m],b[m]是和第m层输出有关的系数,W的维度(第m层单元数,上一层单元数),b的维度为(第m层单元数,1)。
3.3计算一个神经元网络的输出
(1)神经结构如下:
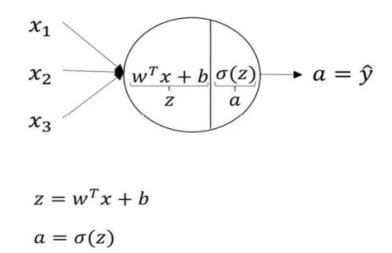
(2)每一个神经元做的计算:
(2)向量化表示下面四个式子:
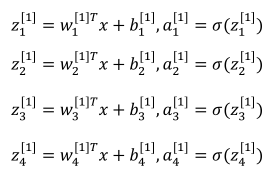
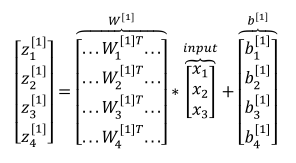
(3)一个输入样本,神经网络的计算
3.4多样本向量化
(1)多样本的计算示意图(a[2](1)前面的2表示第二层,后面的1表示第一个样本):
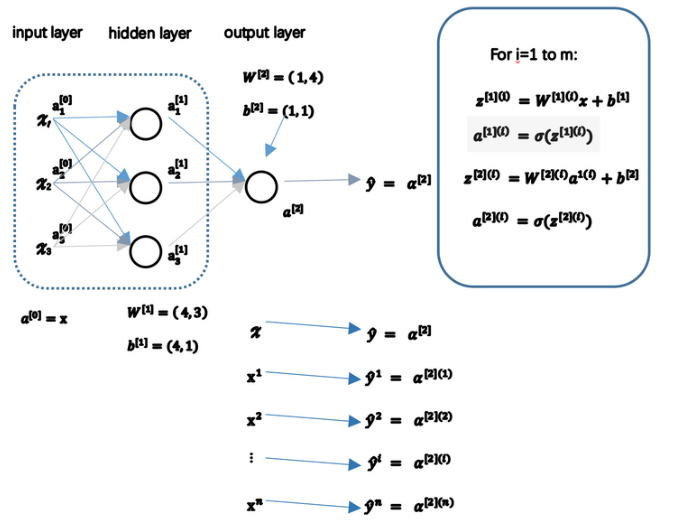
(2)向量化:

(3)以矩阵A为例,从水平上看,每一列对应着不同的训练样本;从垂直方向看,每一行对应着同一层的不同神经元。
3.5向量化实现的解释
(1)矩阵乘列向量得到列向量:
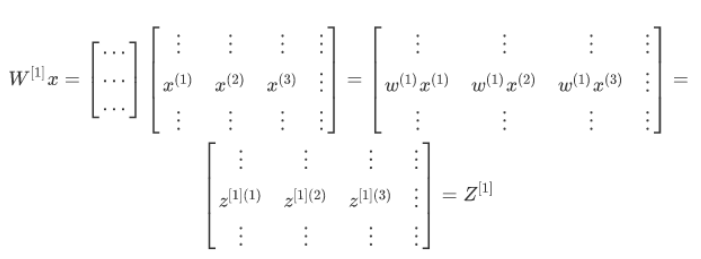
(2)上面式子中省略了b[1],b[1]的维度与Z[1]相同,再加上python具有广播的功能,所以可以使得向量b与每一列相加。
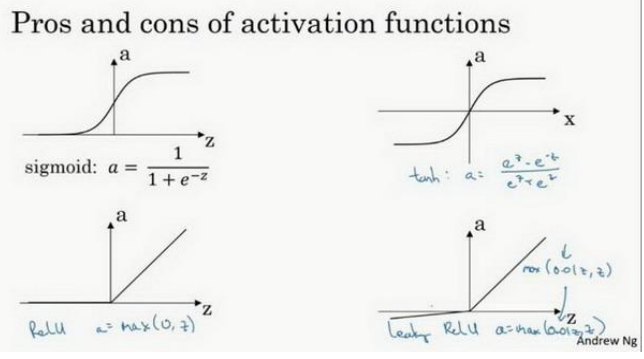
3.6激活函数
(1)sigmoid激活函数:除了输出层是一个二分类问题基本不会用它。存在梯度消失问题,其函数表达式如下:
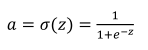
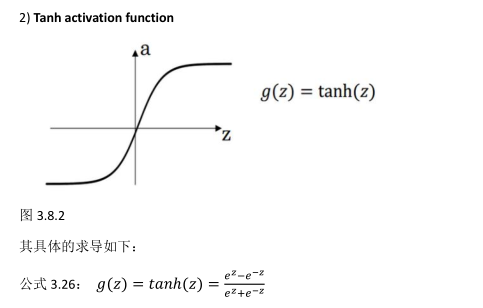
(2)tanh激活函数:tanh是非常优秀的,可以中心化数据(-1到1),几乎适合所以场合。存在梯度消失问题,其函数表达式如下:
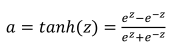
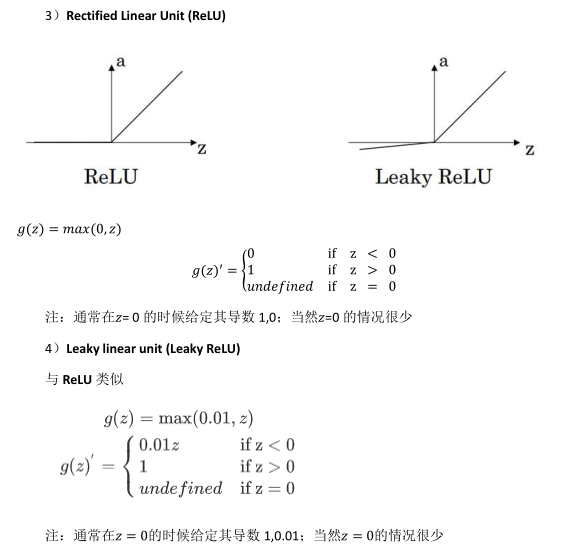
(3)ReLU激活函数:最常用的默认函数,如果不确定用哪个激活函数,就是用ReLU(函数表达式为a=max(0,z))或则Leaky ReLU(函数表达式为a=max(0.01z,z),0.01参数可改)。ReLU在负半区梯度为零,产生所谓的稀疏性,但由于有足够多的掩藏层是z大于0,所以学习过程还是非常的快。
(4)下面的四种激活函数的图像:
3.7为什么需要非线性激活函数
(1)如果没有非线性激活函数,那么无论网络有多少层,输出始终是输入的线性组合,与一层网络毫无区别。举例如下:

(2)有时候输出可能会用到线性激活函数。
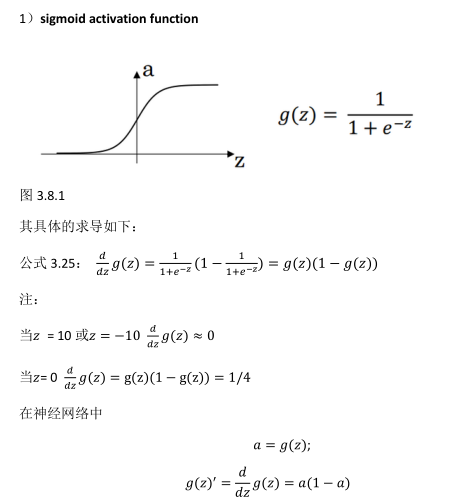
3.8激活函数的导数
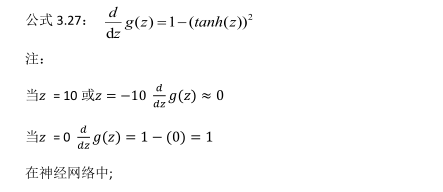
3.9神经网络的梯度下降
(1)正向传播四个式子:

(2)反向传播六个式子(下面公式3.3.2中应该是dz[2]):

3.10(选修)直观理解反向传播
(1)主要推导过程:
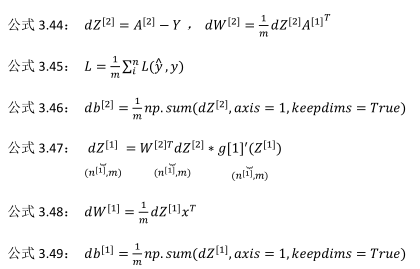
3.11随机初始化
(1)W不能初始化为零否则一层中每个单元都做相同的计算,和一个单元没什么区别,b可以初始化为零。可按照如下方式初始化(0.01的作用是时输出不会太大,太大由由sigmoid、tanh激活函数是将会导致梯度特别小):
