Mac下使用IDEA远程连接Hadoop调试MapReduce程序,参考网上博客,总会出现如题报错,下面是我在mac下的一种解决办法,可以参考。
前期准备
如果想远程调试,需要做一些准备工作,简单罗列下。
(1)在本地准备一份了hadoop(有博主直接从集群中copy一份),设置环境变量。
# hadoop路径为具体路径
export HADOOP_HOME=/Users/yangchaolin/hadoop2.6.0/hadoop-2.6.0-cdh5.14.0
(2)IDEA工程下,将本地hadoop中share文件下的资源jar包都引入到项目中。
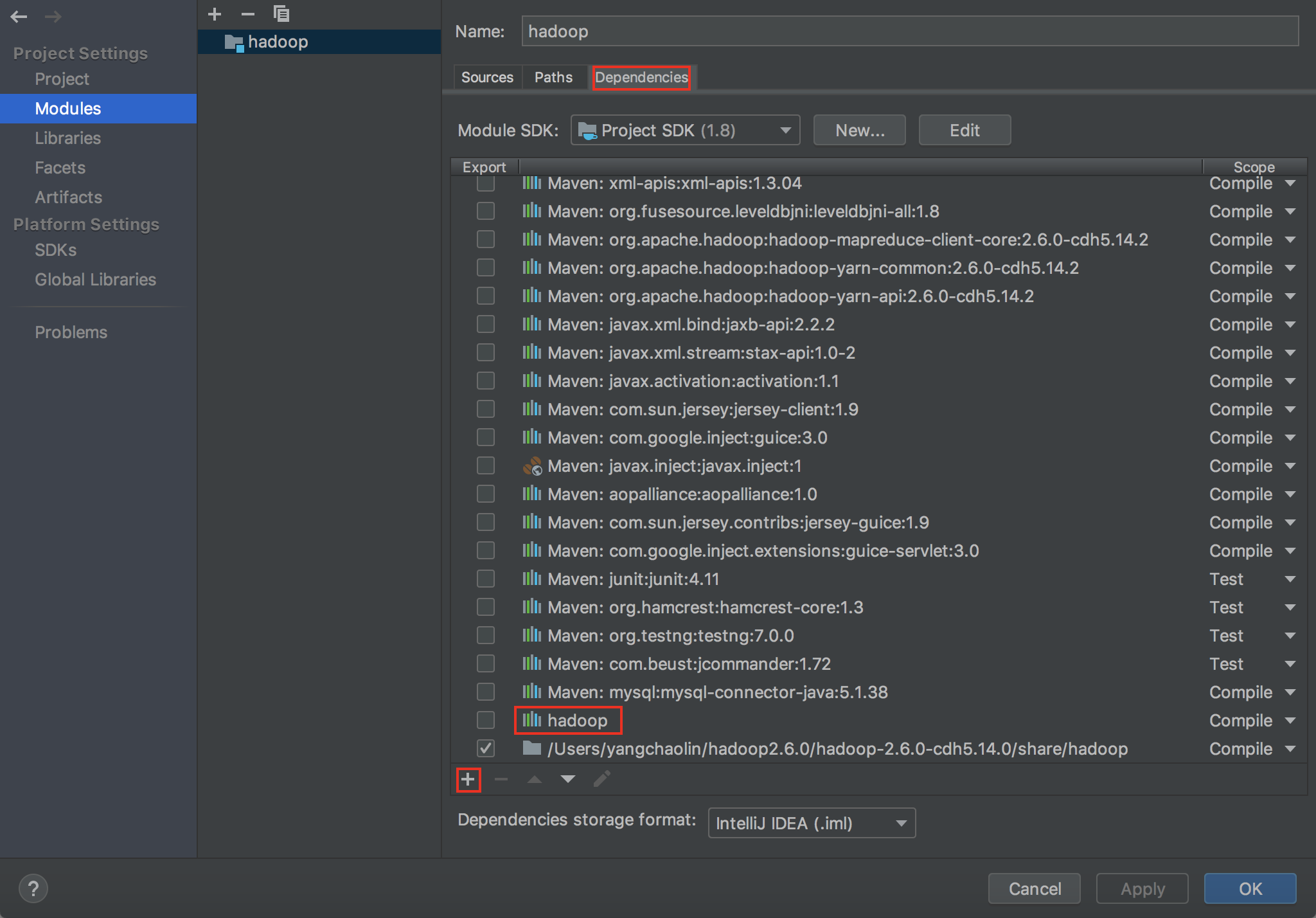
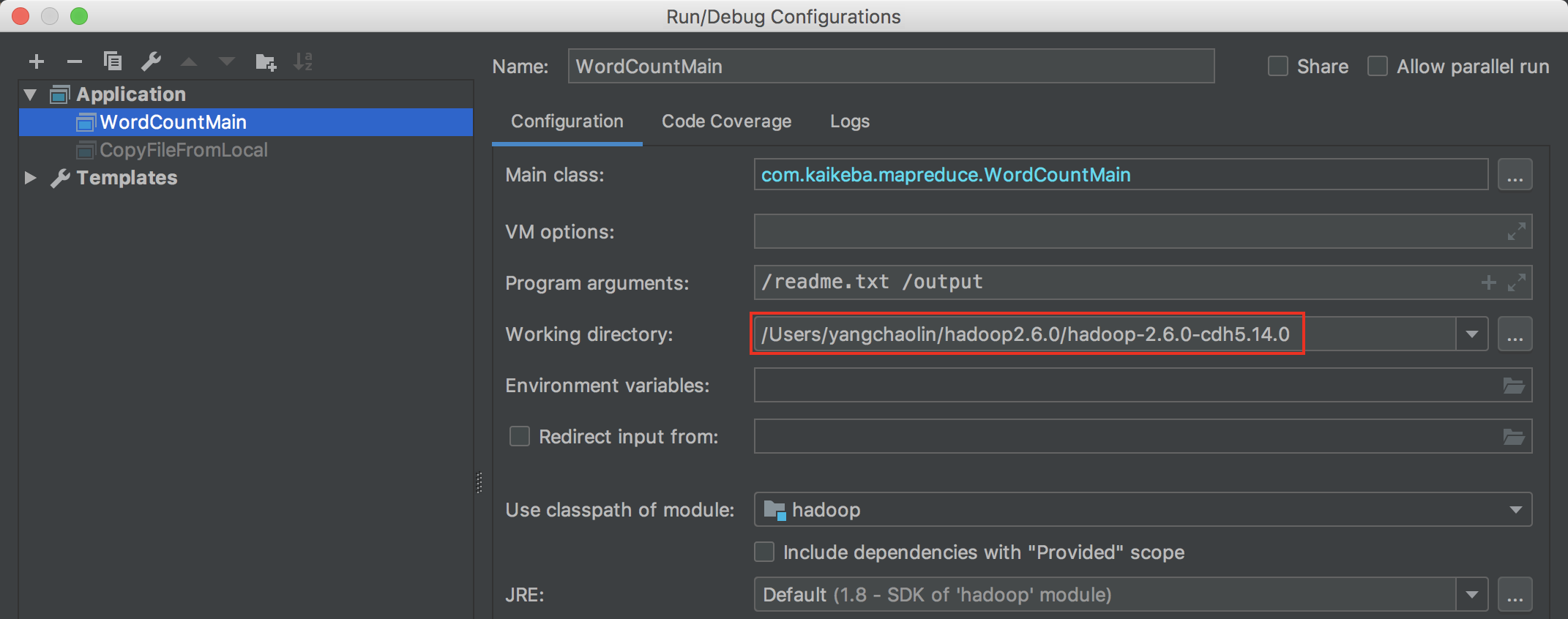
(3) 准备MapReduce程序,并创建一个application,这个application使用的工作目录就使用本地hadoop。
map端程序


1 package com.kaikeba.mapreduce; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Mapper; 7 8 import java.io.IOException; 9 10 /** 11 * mapreduce's map 12 */ 13 public class WordCountMap extends Mapper<LongWritable, Text,Text, IntWritable> { 14 //most application should override map method 15 @Override 16 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 17 //split 18 String readLine = value.toString(); 19 String[] words = readLine.split(" "); 20 //words output to disk 21 for(String word:words){ 22 context.write(new Text(word),new IntWritable(1)); 23 } 24 } 25 }
reduce端程序
1 package com.kaikeba.mapreduce; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Reducer; 6 7 import java.io.IOException; 8 9 /** 10 * mapreduce's reduce 11 */ 12 public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> { 13 //should override reduce method 14 @Override 15 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 16 //count words count 17 int count=0; 18 for(IntWritable i:values){ 19 count+=i.get(); 20 } 21 //output key value to hdfs 22 context.write(key,new IntWritable(count)); 23 } 24 }
main函数
1 package com.kaikeba.mapreduce; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 10 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 12 13 import java.io.IOException; 14 15 /** 16 * mapreduce's main method, 'WordCountMain' is mapreduce's job name 17 */ 18 public class WordCountMain { 19 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 20 //check args,args is input path and output path 21 if(args==null||args.length!=2){ 22 System.out.println("please input path"); 23 System.exit(0);//exit main method 24 } 25 //create mapreduce job 26 Configuration conf=new Configuration(); 27 //if run mapreduce in cluster,set conf and mapred-site should set yarn 28 //conf.set("mapreduce.job.jar","/home/hadoop/IdeaProject/hadoop/target/hadoop-1.0-SNAPSHOT.jar"); 29 //conf.set("mapreduce.app-submission.cross-platform","true"); 30 //conf.set("mapreduce.framework.name","yarn"); 31 32 /** 33 * Creates a new Job with no particular Cluster and a given jobName. 34 * A Cluster will be created from the conf parameter only when it's needed 35 */ 36 Job job=Job.getInstance(conf,WordCountMain.class.getSimpleName());//get class simplename 37 //set mapreduce job 38 job.setJarByClass(WordCountMain.class);//Set the Jar by finding where a given class came from 39 //set input/output format 40 job.setInputFormatClass(TextInputFormat.class); 41 job.setOutputFormatClass(TextOutputFormat.class); 42 //set input/output path 43 FileInputFormat.setInputPaths(job,new Path(args[0])); 44 FileOutputFormat.setOutputPath(job,new Path(args[1])); 45 //set map/reduce class 46 job.setMapperClass(WordCountMap.class); 47 job.setReducerClass(WordCountReduce.class); 48 //add combine class 49 job.setCombinerClass(WordCountReduce.class); 50 //set map/reduce output key-value type 51 //map 52 job.setMapOutputKeyClass(Text.class); 53 job.setMapOutputValueClass(IntWritable.class); 54 //reduce 55 job.setOutputKeyClass(Text.class); 56 job.setOutputValueClass(IntWritable.class); 57 //set job number ---> 4 reduce task 58 job.setNumReduceTasks(4); 59 //job commit 60 try{ 61 job.waitForCompletion(true); 62 }catch(Exception e){ 63 e.printStackTrace(); 64 } 65 } 66 }
其他资源文件内容省略,因为本文报错跟资源配置文件没有关系。
程序使用maven打成jar包,使用hadoop jar 类的全路径名 输入路径 输出路径的命令在linux下执行是没有问题,具体过程省略。
报错解决
接下来使用IDEA远程调试hadoop,配置好上文创建的application后,发现执行会报如下错误,说找不到路径或目录。
1 19/10/14 00:53:02 WARN security.UserGroupInformation: PriviledgedActionException as:yangchaolin (auth:SIMPLE) cause:ExitCodeException exitCode=1: chmod: /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas/mapred/staging/yangchaolin90307621/.staging/job_local90307621_0001: No such file or directory 2 3 Exception in thread "main" ExitCodeException exitCode=1: chmod: /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas/mapred/staging/yangchaolin90307621/.staging/job_local90307621_0001: No such file or directory 4 5 at org.apache.hadoop.util.Shell.runCommand(Shell.java:604) 6 at org.apache.hadoop.util.Shell.run(Shell.java:507) 7 at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:789) 8 at org.apache.hadoop.util.Shell.execCommand(Shell.java:882) 9 at org.apache.hadoop.util.Shell.execCommand(Shell.java:865) 10 at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:720) 11 at org.apache.hadoop.fs.ChecksumFileSystem$1.apply(ChecksumFileSystem.java:498) 12 at org.apache.hadoop.fs.ChecksumFileSystem$FsOperation.run(ChecksumFileSystem.java:479) 13 at org.apache.hadoop.fs.ChecksumFileSystem.setPermission(ChecksumFileSystem.java:495) 14 at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:616) 15 at org.apache.hadoop.mapred.JobClient.copyAndConfigureFiles(JobClient.java:814) 16 at org.apache.hadoop.mapred.JobClient.copyAndConfigureFiles(JobClient.java:774) 17 at org.apache.hadoop.mapred.JobClient.access$400(JobClient.java:178) 18 at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:991) 19 at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:976) 20 at java.security.AccessController.doPrivileged(Native Method) 21 at javax.security.auth.Subject.doAs(Subject.java:422) 22 at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920) 23 at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:976) 24 at org.apache.hadoop.mapreduce.Job.submit(Job.java:582) 25 at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:612) 26 at com.kaikeba.mapreduce.WordCountMain.main(WordCountMain.java:60) 27 28 Process finished with exit code 1
(1)尝试将集群中hadoop安装目录权限修改为777,继续测试,依然报错。
(2)根据报错说找不到目录,参考使用window本的童鞋,发现他们会在磁盘下自动创建一个目录(这个目录是在资源配置文件中指定的),查看我的mac发现并没有这个目录,尝试在mac的根目录下创建主目录,并赋予777权限,再次执行竟然通过了!!!怀疑跟mac下用户的权限有关系,因为window下一般用户都是管理员,而mac不是。
# 进入根目录
youngchaolinMac:/ yangchaolin$ cd /
# 创建主目录 youngchaolinMac:/ yangchaolin$ sudo mkdir kkb Password: youngchaolinMac:/ yangchaolin$ ls -l total 45... drwxr-xr-x 2 root wheel 68 10 23 22:52 kkb # 赋予777权限 youngchaolinMac:/ yangchaolin$ sudo chmod -R 777 kkb youngchaolinMac:/ yangchaolin$ ls -l total 45... drwxrwxrwx 2 root wheel 68 10 23 22:52 kkb
IDEA执行通过,完成MapReduce任务。
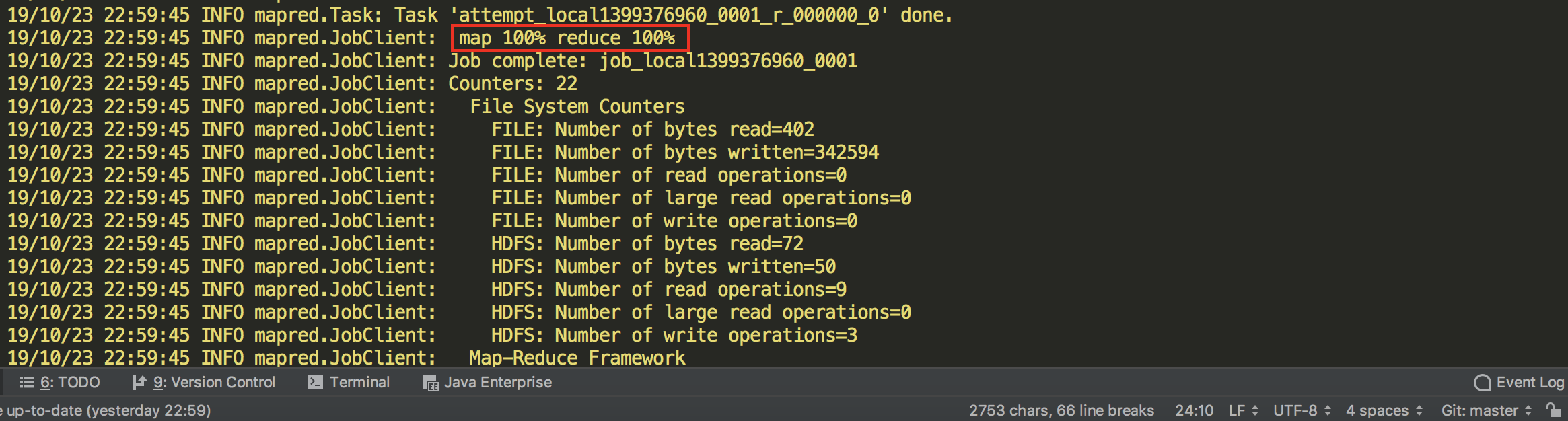
集群中查看计算结果,ok。
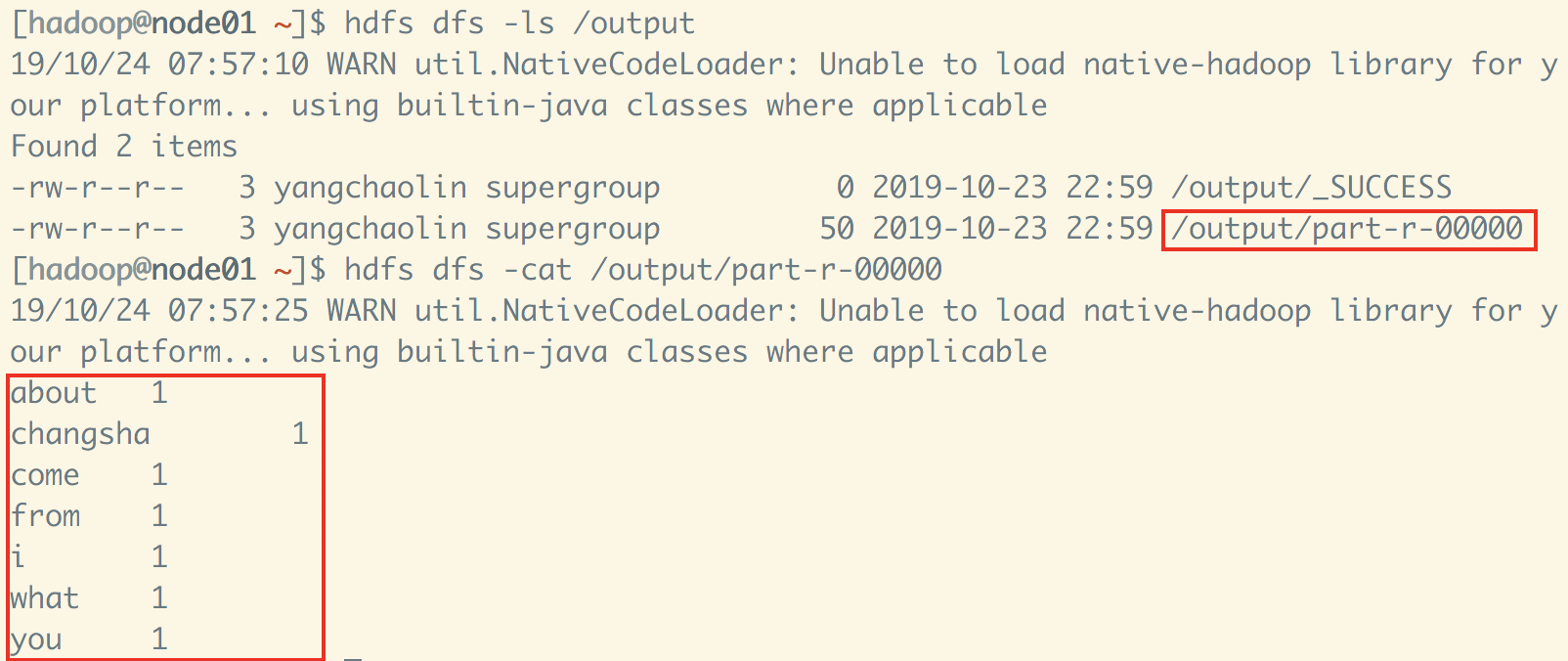
网上查了很多博客,有这个报警的各种解决方法,但是很多是window下。如果是mac,可参考本文,这可能是这个报错的一种解决方法。
参考博文:
(1)https://www.cnblogs.com/yjmyzz/p/how-to-remote-debug-hadoop-with-eclipse-and-intellij-idea.html