1.pod的基本概念
1)k8s中最小的部署单元
2)一组容器的集合,含多个容器
3)一个pod中的容器共享网络命名空间
4)Pod 生命周期比较短暂的组件, 比如, 当 Pod 所在节点发生故障, 那么该节点上的 Pod
会被调度到其他节点, 但需要注意的是, 被重新调度的 Pod 是一个全新的 Pod,跟之前的
Pod 没有关系 。
5)pod依赖于一个基础镜像,一般都是pause开头的这样一个镜像。
2.pod的两种机制
1)共享网络
一个pod创建后,它通过pause根容器,把其它业务容器加入到pause容器里,让所有业务容器在同一个namespaces名称空间中,从而实现网络共享。
注:docker不同容器实现隔离的机制是各自独立的 namespaces和cgroup实现的。
2)共享存储
一个pod创建后,是分布node节点上的,那么当这个节点宕机以后,pod的自愈能力会在其它节点创建新的pod,这时候如果没有用到共享存储的话,新创建的pod只是一个纯粹的编排资源对象,没有实际的数据,那么数据就丢失了。k8s中定义了pv和pvc的概念使得pod共享存储。
3.pod镜像拉取的三种策略
yaml文件中你会看到这样两行:
image:nginx:1.18
imagepullpolicy:always
---
always:每次创建pod都会重新拉取镜像
iFNotPresent:默认值,宿主机不存在该镜像时才拉取。
never:pod永远不会主动拉取镜像
4.pod资源限制
k8s采用request和limit两种制类型来对资源进行分配和限制,底层还是用docker的cgroup技术。
request资源需求:即运行pod的节点必须满足运行pod的最基本需求才能运行pod
limit资源限制:运行pod期间,内存使用量可能会增加,那么最多能使用多少,这就是资源限额也就是硬限制。
CPU单位理解:一核=1000(millicores) 500M即0.5个Cpu
内存单位理解:常规的M单位
参考图中示例:

5.重启机制
yaml文件中你会看到这样一行:
restartpolicy:never
always:默认策略,当容器终止退出后,总是重启容器,适用于业务容器
注:下面两种策略适用于批量任务
onfailure:当容器一次退出(退出状态码非0)时,才重启容器
never:当容器终止退出,从不重启容器。
6.影响pod调度的属性
1)pod资源限制会对pod具体分配到那个节点上运行产生影响
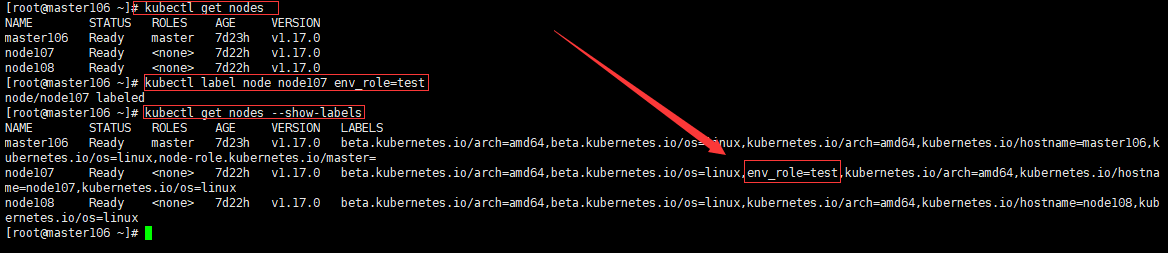
2)节点选择器
例如:nodeselecter:
env_role:test #选择test标签的节点上运行pod。
前提先给节点打标签命令如图:
3)节点亲和性
nodeaffinity 分硬亲和和软亲和。
4)污点和污点容忍 taint污点:节点不做普通调度,是节点属性,而上面的节点选择器和亲和力都是pod属性。