Collection
collection是单个集合保存的最大父亲接口,他与子接口的关系

List接口使用频率占集合的80%,List有两个重要的扩展方法:
E get(int index) 根据索引取得元素
E set(int index,E element)修改数据
ArrayList,LinkedList,Vector的区别:
ArrayList,Vector的底层由数组实现,链表由双链表实现的。ArrayList是非线程安全的,而Vector是线程安全的,故ArrayList的异步处理,效率更高,Vector同步处理,性能较低。
输出形式:
ArrayList的支持迭代器,ListIterator,foreach;
Vector支持迭代器,ListIterator,foreach,枚举。
设置实现的两个子类:HashSet的(无序存储),TreeSet的(有序存储)
需要注意的是:当我们使用TreeSet存放自定义的类时,该自定义类需要实现Comparable接口,否则会报错java.lang.ClassCastException :Serch.Person不能转换为java.lang.Comparable
import java.util.*;
class Person implements Comparable<Person>{
private String name;
private Integer age;
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
public Person(String name, Integer age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public int compareTo(Person o) {
if(o.age<this.age) {
return 1;
}else if(o.age>this.age) {
return -1;
}else {
return this.name.compareTo(o.name);
}
}
}
public class Test{
public static void main(String[] args) {
Set<Person> set = new TreeSet<>();
set.add(new Person("A", 25));
set.add(new Person("B", 20));
Iterator<Person> iterator = set.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
HashSet判断重复元素并不是实现Comparable接口来完成的,而是使用hashCode()和equals()方法来实现,如果要想标识出对象的唯一性,一定需要equals()与hashCode()方法共同调用。即:只有当equals()与hashCode()都判断为相同时才可以判断这两个元素是重复的,将此消除。
哈希的作用好比分桶,比如我们给一堆数据通过取模3运算来分桶,那么1 4 7 10分在第一个桶,2 5 5 8分在第二个桶,3 6 9分在第三个桶,我们可以得出这样的结论,不同的元素可能分在一个桶(hash),即
a)equals不同,hashCode可能相同,
b)hashCode相同,equals不一定相同,
c)equals相同,hashCode一定相同(我们在第二个桶放了两个5,注意,相同的元素在Set里是会被消除的,我这里只是举个栗子)
集合的四中输出形式:Iterator、ListIterator、Enumeration、foreach。
1)Iterator
JDK1.5之前,在Collection接口中就定义有iterator()方法,通过此方法可以取得Iterator接口的实例化对象;而在JDK1.5之后,将此方法提升为Iterable接口中的方法。无论你如何提升,只要Collection有这个方法,那么List、Set也一定有此方法
使用方法如下:
Iterator<集合类型> iterator = 集合实例化对象.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
2)ListIterator(双向迭代接口)
他是Iterator的子接口,比Iterator多了可以从后向前迭代处理
1. 判断是否有上一个元素:public boolean hasPrevious();
2. 取得上一个元素: public E previous();
注意:要实现从前向后输出,应该先从前向后输出一次,否则无法实现。
3)foreach
与数组的使用方式一致:
for(对象类型 对象实例 : 集合实例){
Syso(对象实例);
}
4) Enumeration(不常用)
使用方式:
Vector<Person> vector = new Vector<>();
vector.add(new Person("A", 20));
vector.add(new Person("B", 20));
vector.add(new Person("C", 20));
vector.add(new Person("A", 20));
Enumeration<Person> enumeration = vector.elements();
while(enumeration.hasMoreElements()) {
System.out.println(enumeration.nextElement());
}
运行结果:

Map接口
Map<K key, V value>接口一次保存两对象,Map接口存储的对应关系,Key:Value;Map接口的常用子类有如下四个: HashMap、Hashtable、TreeMap、ConcurrentHashMap。
Map接口的常用方法:

特点:
在JDK1.8前,HashMap底层存储使用的是拉链法(数组+链表)JDK8后加入了红黑树。
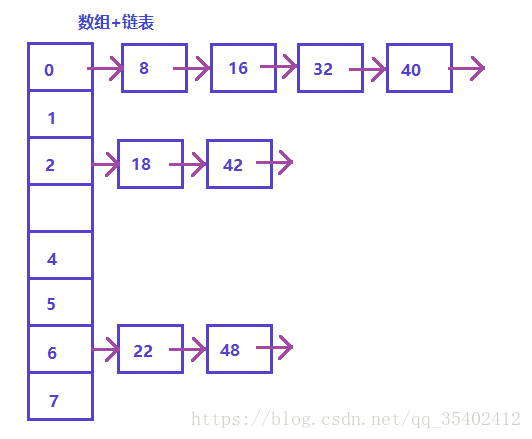
Map的key用Set存放,故key不能重复。
允许空键和空值(但空键只有一个,且放在第一位)
默认初始容量:16
默认加载因子:0.75 结合时间和空间效率考虑得到的,若加载因子太大,引起冲突的可能增大;加载因子太小,频繁的进行扩容,且浪费空间。
扩容时:
新初始化哈希表时,容量为默认容量,阈值为 容量*加载因子。
已有哈希表扩容时,容量、阈值均翻倍。
JDK1.8后加入红黑树。为什么要加入红黑树?
Hash虽然尽可能提高了查询的效率,但也有可能存在一些极端的可能性,若大量数据存在同一个桶内,那么执行该链表也是需要大量的操作,在上述的讲解拉链法中,当链表的元素足够多时,JDK1.8为此加入了红黑树,我们知道,红黑树是一种比链表查询更高效的数据结构.JDK1 0.8默认链表节点达到8个时进行链表- >红黑树转化。
红黑树的三个关键参数:
TREEIFY_THRESHOLD (默认为8)
。当链表数量为8时进行转化
UNTREEIFY_THRESHOLD (默认为6)
当扩容时,桶内的元素进过再哈希可能会分到别的桶,桶中元素若原来为红黑树,当数量减少为6,则把红黑树还原为链表结构。
MIN_TREEIFY_CAPACITY (默认为64)
为了避免进行扩容,树形化还有一次判断机会,即,如果哈希表中的元素大于64,才进行扩容。
如下图(数据不做任何考证,只做参考)
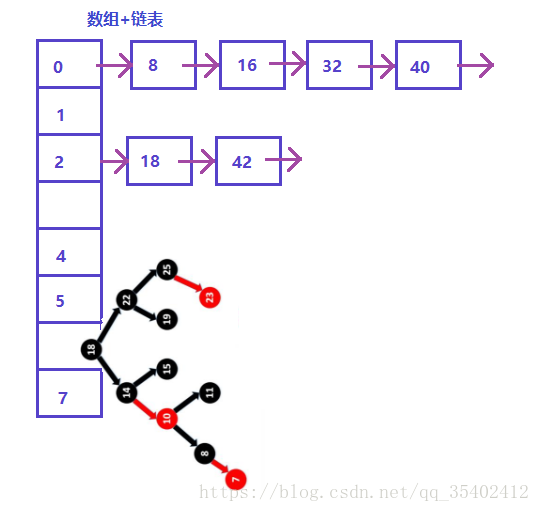
HashMap中与哈希表的区别:

Properties(资源文件)
*.properties文件,在这种文件里面其内容的保存形式为"key =value",通过ResourceBundle类读取的时候只能读取内容,要想编辑其内容则需要通过Properties类来完成,这个类是专门做属性处理的。
Properties是Hashtable的子类:public class Properties extends Hashtable<Object,Object>
方法:
1. 设置属性 : public synchronized Object setProperty(String key, String value)
2. 取得属性 : public String getProperty(String key),如果没有指定的key则返回null
3. 取得属性 : public String getProperty(String key, String defaultValue),如果没有指定的key则返回默认值
支持IO方法:
1. 保存属性: public void store(OutputStream out, String comments) throws IOException
2. 读取属性: public synchronized void load(InputStream inStream) throws IOException
public class Test {
public static void main(String[] args) throws FileNotFoundException, IOException {
Properties properties = new Properties();
properties.setProperty("a", "This is A");
properties.setProperty("b", "This is B");
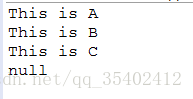
System.out.println(properties.getProperty("a"));
System.out.println(properties.getProperty("b","C"));
System.out.println(properties.getProperty("c","This is C"));//返回设置的形参,并不会给其赋值
System.out.println(properties.getProperty("c"));
File file = new File("C:\Users\Administrator\Desktop\test1.properties");
properties.store(new FileOutputStream(file), "testproperties");
}
}

public class Test {
public static void main(String[] args) throws FileNotFoundException, IOException {
Properties properties = new Properties();
// properties.setProperty("a", "This is A");
// properties.setProperty(“b”,“This is B”);
// System.out.println(properties.getProperty(“a”));
// System.out.println(properties.getProperty(“b”,“C”));
// System.out.println(properties.getProperty(“c”,“This is C”)); //返回设置的形参,并不会给它的赋值
// System.out.println(properties.getProperty(“c”));
File file = new File(“C:\ Users \ Administrator \ Desktop \ test1.properties”);
properties.load(new FileInputStream(file));
的System.out.println(properties.getProperty( “A”));
}
}