create table a( id int, username varchar2(20) ); create table b( id int, username varchar2(20) ); insert into a values(1,'小明'); insert into a values(2,'小红'); insert into a values(3,'小君'); commit select * from a select * from b delete from a where id>=4 insert into b values(2,'小红'); insert into b values(4,'小星'); insert into b values(5,'小刘');
去重 (查人数) select * from a union select * from b
去重另一种写法 select distinct * from ( select * from a union all select * from b )
不去重(速度快) select * from a union all select * from b
求红色区域
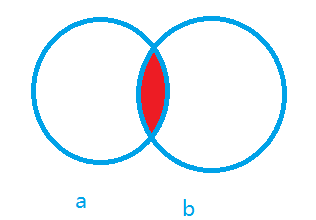
先查id
select id from a where a.id in (select b.id from b)
再查是谁 select * from a where id in( select id from b where b.id in (select a.id from a) )
另一种方法 select * from b where b.id in (select a.id from a)
还有一种方法 select b.* from a,b where a.id = b.id
求红色区域
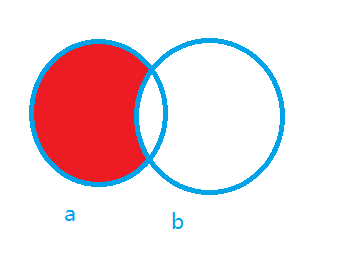
select * from a where id not in (select id from b)
not in 在oracle大数据时,速度非常慢,不建议使用
select * from a where id in ( select id from a minus select id from b )