我们在前面一章做了一个稍微复杂的爬虫,这里我们再另外一个爬虫
现在我们要从下面的网站(国家药品监督管理局)爬取到所有的企业名称和其对应的生产许可证信息
官网地址:http://scxk.nmpa.gov.cn:81/xk/
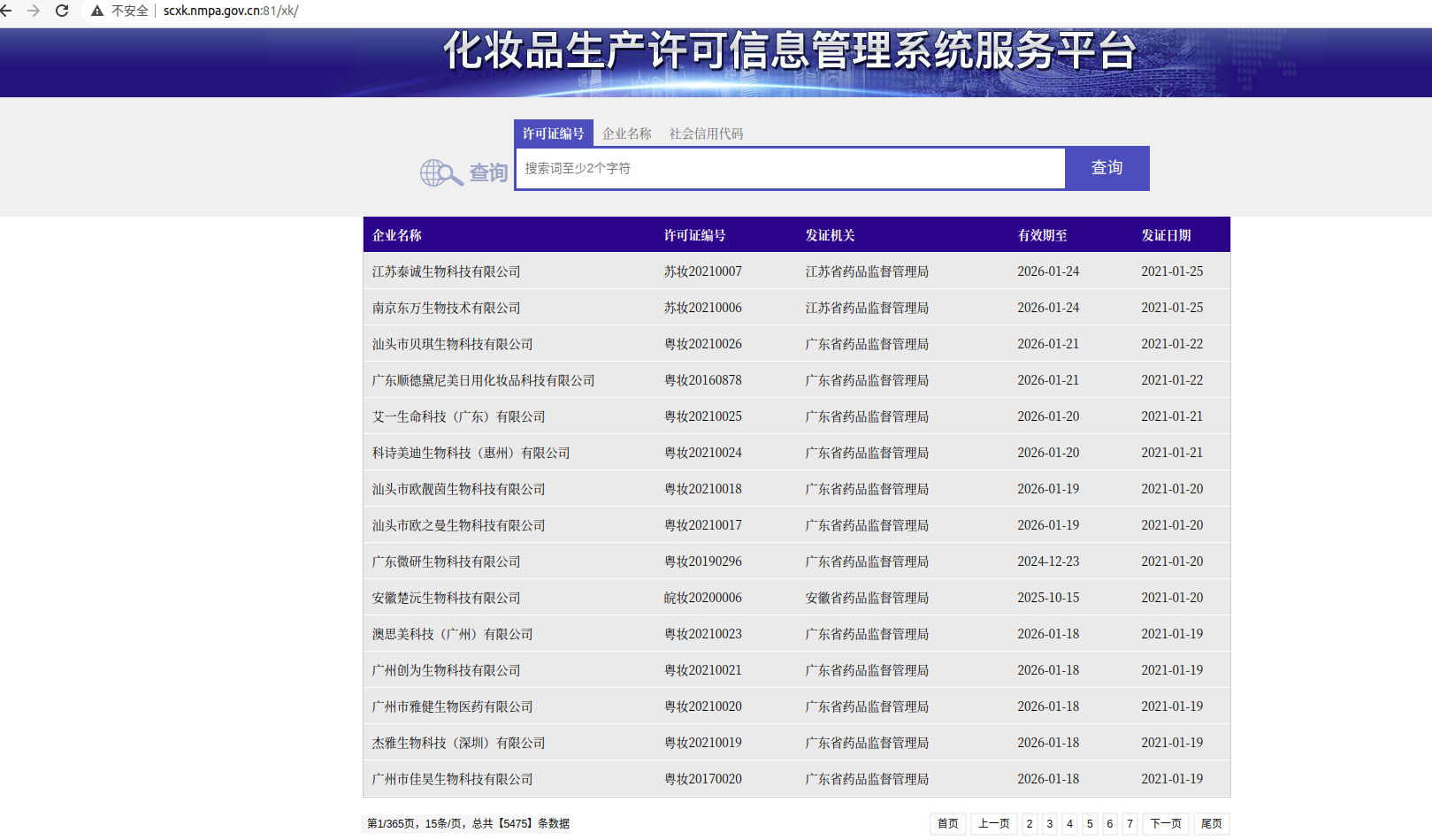
上面的图就是主页的效果,注意一下一共是365页,美业是15条信息
随便点开一个公司对应的链接

就是这样的内容
数据持久化的要求是每个公司对应一个文件,文件名就是公司名称。
为了说明流程,这里不爬取所有的数据,只爬3页的就行了,主要说明爬虫的流程。
整个爬虫主要分两个步骤,第一个是拿到每页上的各个公司对应的链接,第二步是获取到第二个页面上的公司信息
公司的获取
先用抓包工具看一下第一个页面上请求的过程以及数据是通过什么方式过来的!

前端上每个公司都是一个li标签

而标签里的内容是通过AJAX请求拿到的数据。我们可以看看响应部分的内容
"filesize":"", "keyword":"", "list":[ { "ID":"2a9cdc38848d4a528718435fcc321426", "EPS_NAME":"江苏泰诚生物科技有限公司", "PRODUCT_SN":"苏妆20210007", "CITY_CODE":"92", "XK_COMPLETE_DATE":{ "date":25, "day":1, "hours":0, "minutes":0, "month":0, "nanos":0, "seconds":0, "time":1611504000000, "timezoneOffset":-480, "year":121 }, "XK_DATE":"2026-01-24", "QF_MANAGER_NAME":"江苏省药品监督管理局", "BUSINESS_LICENSE_NUMBER":"91321291MA22CL3C26", "XC_DATE":"2021-01-25", "NUM_":1 }, { "ID":"e07b9ae1130d4a2a9528970e214a494c", "EPS_NAME":"南京东万生物技术有限公司", "PRODUCT_SN":"苏妆20210006", "CITY_CODE":"81", "XK_COMPLETE_DATE":{ "date":25, "day":1, "hours":0, "minutes":0, "month":0, "nanos":0, "seconds":0, "time":1611504000000, "timezoneOffset":-480, "year":121 }, "XK_DATE":"2026-01-24", "QF_MANAGER_NAME":"江苏省药品监督管理局", "BUSINESS_LICENSE_NUMBER":"9132011608773791X1", "XC_DATE":"2021-01-25", "NUM_":2 },
上面的内容是两条li标签里的内容,注意下最开始第二个页面截图中的url,是带了一个参数的
http://scxk.nmpa.gov.cn:81/xk/itownet/portal/dzpz.jsp?id=f355d4df25a04241bffb7edc18e7667a
注意那个参数id,就是我们在上面那个ajax请求获取到的json数据里的一部分内容
详细内容的获取
第二个页面中我们要获取到内容是在一个table里,那么表格里的数据是怎么来的呢?同样我们还是从抓包工具看一下

注意到请求的参数了么,这就是我们刚才获取到的id
我们先获取到第一部分的内容
import requests import json if __name__ == '__main__': url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList' head = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36' } data = { 'on': 'true', 'page': '', 'pageSize': '15', 'productName':'', 'conditionType': '1', 'applyname': '', } Company_list = [] for i in range(1,4): data['page'] = str(i) request = requests.post(url=url,headers=head,data=data) comp = request.json()['list'] for company in comp: company_name = company['EPS_NAME'] company_id = company['ID'] Company_list.append({'name':company_name,'id':company_id})
要注意一点:我们发送POST请求对应的URL并不是我在这一页一开始哪里贴出来的官网地址,而是AJAX请求对应的地址
for循环是我们指定了个页数,在爬取每页数据的过程中,做了一个列表,列表里存放的是公司名称和对应的ID所组成的字典。下面就可以通过这个列表爬取具体的数据了
具体数据的获取
和上面的爬取数据的过程一样,就是在一个循环里我们拿到需要的数据
detail_url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById' for company in Company_list: data2 = { 'id':company['id'] } request = requests.post(url=detail_url,headers=head,data=data2) with open(company['name']+'.txt','w',encoding='utf-8') as f: _comp = request.json() json.dump(_comp,f,ensure_ascii=False)
这里要注意点一点,就是因为返回的数据里是包含有中文的,在写入json数据时如果有中文要加上参数:ensure_ascii=False。
整个爬虫过程没什么难点,主要是让我们知道其工作的流程。