一 什么是分析函数
1 概念
分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值。
2 和聚合函数的区别
普通的聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。
3 开窗函数
开窗函数指定了函数所能影响的窗口范围,也就是说在这个窗口范围中都可以受到函数的影响,有些分析函数就是开窗函数。
4 分析函数语法
function_name (<argument>,<argument>...)
OVER
(<PARTITION-Clause>
<ORDER-BY-Clause>
<Windowing-Clause>)
语法解释:
1. function_name:对窗口中的数据进行操作,Oracle常用的分析函数有(这里就列举了一些常用的,其实有很多)
① 聚合函数
sum:一个组中数据累积和
min:一个组中数据最小值
max:一个组中数据最大值
avg:一个组中数据平均值
count:一个组中数据累积计数
② 排名函数
row_number( ):返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
rank( ):返回一个唯一的值,当碰到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。
dense_rank( ):返回一个唯一的值,当碰到相同数据时,此时所有相同数据的排名都是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间紧邻递增。
2. over:关键字,用于标识分析函数
3. Partition-Clause:分区子句,根据分区表达式的条件逻辑将单个结果集分成N组
格式: partition by......
4. Order-by-Clause:排序子句,用于对分区中的数据进行排序
格式:order by......
5. Windowing-Clause:窗口子句,用于定义function在其上操作的行的集合,即function所影响的范围
格式:
order by 字段名 range|rows between 边界规则1 AND 边界规则2
边界规则的取值如下表所示:
| 可取值 | 说明 |
| CURRENT ROW | 当前行 |
| N PRECEDING | 前N行 |
| UNBOUNDED PRECEDING | 一直到第一条记录 |
| N FOLLOWING | 后N行 |
| UNBOUNDED FOLLOWING | 一直到最后一条记录 |
注意:RANGE表示按照值的范围进行范围的定义,而ROWS表示按照行的范围进行范围的定义
二 分析函数和开窗函数实例
1 创建表格并插入数据
--创建表格 create table student( name varchar2(20), city varchar2(20), age int, salary int)
--插入数据 INSERT INTO student(name,city,age,salary) VALUES('Kebi','JiangSu',20,3000); INSERT INTO student(name,city,age,salary) VALUES('James','ChengDu',21,4000); INSERT INTO student(name,city,age,salary) VALUES('Denglun','BeiJing',22,3500); INSERT INTO student(name,city,age,salary) VALUES('Yangmi','London',21,2500); INSERT INTO student(name,city,age,salary) VALUES('Nana','NewYork',22,1000); INSERT INTO student(name,city,age,salary) VALUES('Sunli','BeiJing',20,3000); INSERT INTO student(name,city,age,salary) VALUES('Dengchao','London',22,1500); INSERT INTO student(name,city,age,salary) VALUES('Huge','JiangSu',20,2800); INSERT INTO student(name,city,age,salary) VALUES('Pengyuyan','BeiJing',24,4500); INSERT INTO student(name,city,age,salary) VALUES('Baoluo','London',25,8500); INSERT INTO student(name,city,age,salary) VALUES('Huting','ChengDu',25,3000); INSERT INTO student(name,city,age,salary) VALUES('Hurenxiang','JiangSu',23,2500);
表格创建完后,查看表格中的内容

2 聚合函数和开窗函数
① 单一的聚合函数count
案例:如果要求出student表中一共多少人
select count(name) from student
得到的结果
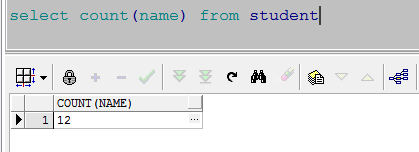
从上表中看出,得到的结果是一个值,即为student表中一共12个人
② 聚合函数count和开窗函数over( )的联合使用
案例:如果查询每个工资小于4000元的员工信息(姓名,城市以及工资),并在每行中都显示所有工资小于4000元的员工个数
第一种实现方式:通过子查询实现
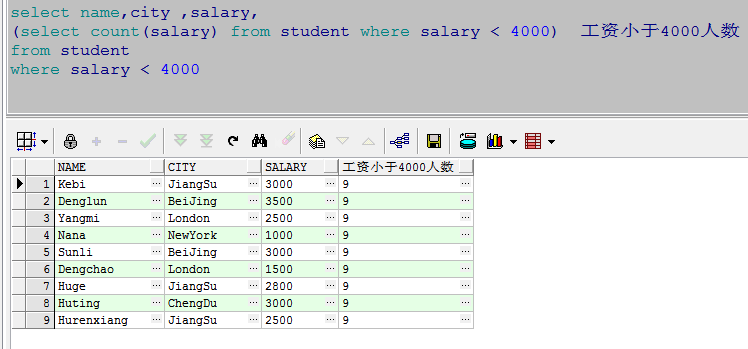
select name,city ,salary,
(select count(salary) from student where salary < 4000) 工资小于4000人数
from student
where salary < 4000
第二种实现方式:开窗函数over( )实现
select name, city, salary,count(*) over()
from student
where salary < 4000
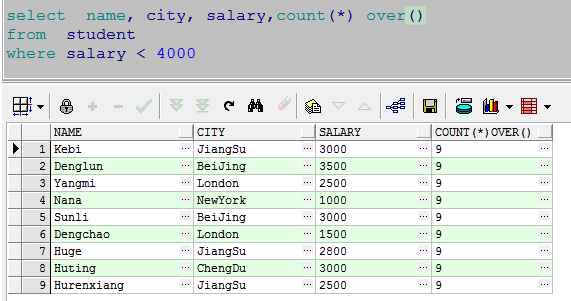
解释一下:开窗函数count(*)over( )是对查询结果的每一行都返回所有符合条件行的条数;
over关键字后的括号中的选项为空,则开窗函数会对结果集中的所有行进行聚合运算;
over关键字后的括号中的选项为不为空,则按照括号中的范围进行聚合运算。
partition by:分区子句,根据分区表达式的条件逻辑将单个结果集分成N组
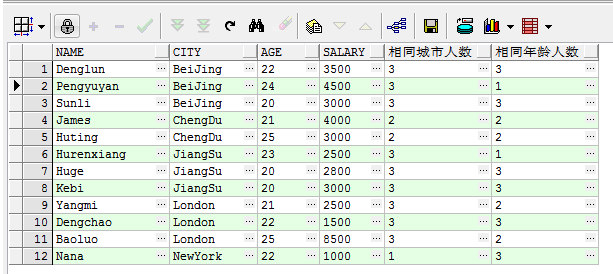
案例:查出表中相同城市和相同年龄的人数
select name, city, age, salary, count(*) over(partition by city) 相同城市人数, count(*) over(partition by age) 相同年龄人数 from student
order by子句:排序子句,用于对分区中的数据进行排序
① row:按照行定位的
案例:查询从第一行到当前行的工资总和
select name, city, age, salary, sum(salary) over(order by salary rows between unbounded preceding and current row) 到当前行工资求和 from student
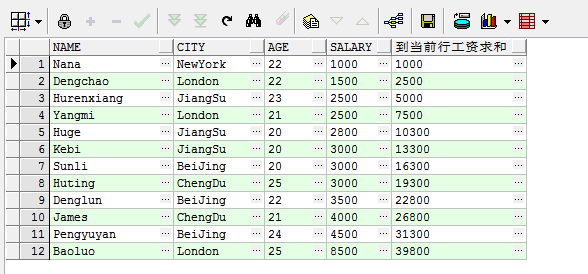
解释一下:over后面的括号中的unbounded preceding表示第一行,current row表示当前行。上面这段代码指的是首先将表中的数据按照salary进行排 序,如果不指明是升序还是降序,默认的是升序。然后看到rows这个字段,说明计算是按照行进行的。就是计算unbounded preceding(第一行)到current row(当前行)的和。比如第一行的salary为1000,第二行的salary为1500,那么第一行到第二行的和为1000+1500=2500;同理第三行salary为2500,那么从第一行到第三行的和为1000+1500+2500=5000,以此类推......
② range:按照范围定位的
案例:查询从第一行到当前行的工资总和
select name, city, age, salary, sum(salary) over(order by salary range between unbounded preceding and current row) 到当前行工资求和 from student
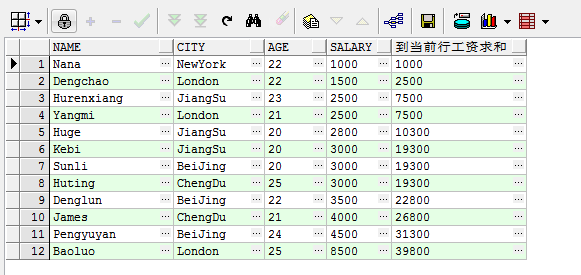
解释一下:range和rows,rows是按照行进行计算的,而range是按照范围进行计算的。这两种方式的不同点是处理并列数据的情况,上面第三行和第四行出现了两个2500,如果是rows就会在第三行显示1000+1500+2500=5000,第四行显示1000+1500+2500+2500=7500;如果是range就会在第三行显示1000+1500+2500+2500=7500,第四行显示1000+1500+2500+2500=7500,因为第三行和第四行中的salary是一样的,同时又是按照range进行计算的,所以从第一行开始r无法判断并列行中的当前行是哪一行,所以直接将并列的数相加。
三 排名函数和分析函数实例
排名函数
row_number( ):返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
rank( ):返回一个唯一的值,当碰到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。
dense_rank( ):返回一个唯一的值,当碰到相同数据时,此时所有相同数据的排名都是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间紧邻递增。
select name , city ,age , salary, row_number()over ( order by salary) as row_number, --按薪水依次排名 rank()over ( order by salary) as rank, --按薪水排名,相同薪水并列 dense_rank()over ( order by salary) as dense_rank --按薪水排名,相同薪水隔几个排名 from student
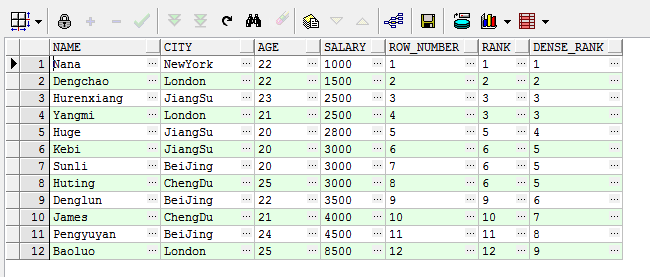
解释一下:因为row_number,rank,dense_rank在排名时极易混淆,所以在这里用这个例子给大家区分一下
row_number:不管是否有相同的薪水,都依次按照记录进行递增(1,2,3,4.....)
rank:按照薪水进行递增,遇到相同的薪水时排名一致,只不过遇到不相同的数据时,中间隔出排名,这么说可能有点抽象,比如上表中第三行和第四行的薪水都是2500,那么rank进行操作时相同的薪水排名一致都是3,而到了第五行则是5,就隔了一个4。
dense_rank:同样是按照薪水进行排序,遇到相同的薪水时排名一致,这边需要和上面的rank进行区分一下,上面的rank遇到相同的数据和不同的数据之间需要隔断,而这个不一样,不需要隔断,第四行和第五行的薪水都是2500,排名都是3,到了第五行不一样的薪水排名就是4。
参考文献:https://blog.csdn.net/jerrytomcat/article/details/82790543