LeNet-5包含于输入层在内的8层深度卷积神经网络。其中卷积层可以使得原信号特征增强,并且降低噪音。而池化层利用图像相关性原理,对图像进行子采样,可以减少参数个数,减少模型的过拟合程度,同时也可以保留一定的有用信息。
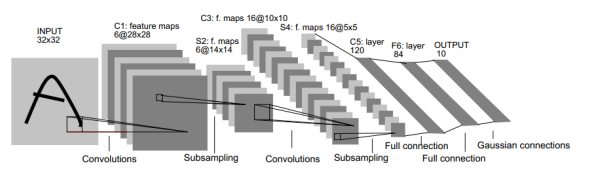
图一 LeNet网络模型框架
|
层次 |
描述 |
参数个数与连接数 |
作用 |
|
INPUT |
32*32的灰度图 |
0 |
|
|
C1卷积层 |
由6个5*5*1卷积核与输入层做卷积操作产生的6个28*28的Feature Map(FM). |
参数:(5*5+1)*6 连接:(5*5*1+1)*6*28*28 |
对输入图像提取6个特征 |
|
S2池化层 |
对C1层的每一个Feature Map的长宽尺寸降到原来的1/2,得到6个14*14的FM通道数量不变。 |
参数:2*6 连接:(2*2+1)*6*(14*14) |
降低网络训练参数及模型的过拟合程度。常用的由最大池化和平均池化。 |
|
C3卷积层 |
有16个FM,由四组卷积核,分别为6个5*5*3,7个5*5*4,2个5*5*5,1个5*5*6。得到16个10*10的FM,每一个FM是由上一层的各FM的不同组合得到,组合情况详见下表。 |
参数:(5*5*3+1)*6+(5*5*4+1)*7+(5*5*5+1)*2+(5*5*6+1)*1 连接:((5*5*3+1)*6+(5*5*4+1)*7+(5*5*5+1)*2+(5*5*6+1)*1)*(10*10) |
提取深层特征 |
|
S4池化层 |
对C2的FM进行池化,降低每一个FM的大小为原来的1/2,得到16个5*5的FM. |
参数:2*16 连接:(2*2+1)*16*(5*5) |
降低网络训练参数及模型的过拟合程度。常用的由最大池化和平均池化。 |
|
C5卷积层 |
由120个5*5*16的卷积核与S4层卷积,得到120个1*1的FM |
参数:(5*5*16+1)*120 连接:(5*5*16+1)*120*(1*1) |
提取深层特征 |
|
F6全连接层 |
84个神经元与C5中的120个神经元全连接,加上4个偏置项。 |
参数:(120+1)*84 连接:(120+1)*84 |
|
|
F7全连接 |
10个神经元与上一层的84个神经元全连接,加上10个偏置项。采用径向基函数(详解看另一篇文章) |
参数:(84+1)*10 连接:(84+1)*10 |
训练 |
|
总结: 1、 我们从模型框架或者模型的结构数据中可以看得出来,从原始图像开始到输出层,Feature Map在逐步减小,而通道数逐渐变大。 2、池化层只改变上一个每一层的FM的尺寸,并不改变其通道数 3、每一个卷积层与紧接的池化层通常合称为一个卷积层。 |
|||
LetNet第三次FM组合表

关于LeNet最后一层的RBF函数理解
参考:http://blog.csdn.net/qiaofangjie/article/details/16826849
输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输入模式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。这些单元的参数是人工选取并保持固定的(至少初始时候如此)。这些参数向量的成分被设为-1或1。虽然这些参数可以以-1和1等概率的方式任选,或者构成一个纠错码,但是被设计成一个相应字符类的7*12大小(即84)的格式化图片。这种表示对识别单独的数字不是很有用,但是对识别可打印ASCII集中的字符串很有用。
使用这种分布编码而非更常用的“1 of N”编码用于产生输出的另一个原因是,当类别比较大的时候,非分布编码的效果比较差。原因是大多数时间非分布编码的输出必须为0。这使得用sigmoid单元很难实现。另一个原因是分类器不仅用于识别字母,也用于拒绝非字母。使用分布编码的RBF更适合该目标。因为与sigmoid不同,他们在输入空间的较好限制的区域内兴奋,而非典型模式更容易落到外边。
RBF参数向量起着F6层目标向量的角色。需要指出这些向量的成分是+1或-1,这正好在F6 sigmoid的范围内,因此可以防止sigmoid函数饱和。实际上,+1和-1是sigmoid函数的最大弯曲的点处。这使得F6单元运行在最大非线性范围内。必须避免sigmoid函数的饱和,因为这将会导致损失函数较慢的收敛和病态问题。