一、groupby分组统计
类似SQL:
select city,max(temperature) from city_weather group by city;
groupby:先对数据分组,然后在每个分组上应用聚合函数、转换函数,官网如下:

1 分组使用聚合函数做数据统计
1)单个列groupby,查询所有数据列的统计

我们看到:
- groupby中的'A'变成了数据的索引列
- 因为要统计sum,但B列不是数字,所以被自动忽略掉
2)多个列groupby,查询所有数据列的统计
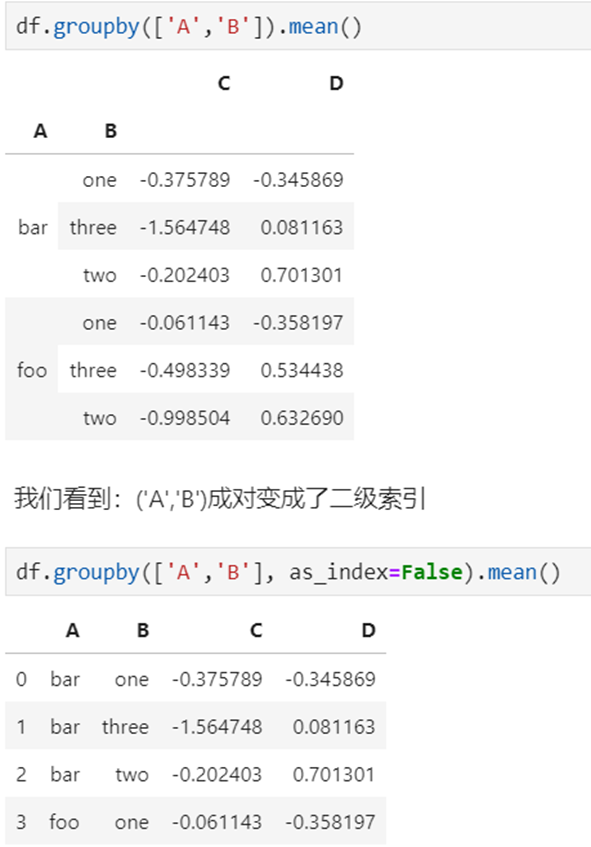
3)同时查看多种数据统计

我们看到:列变成了多级索引
4)查看单列的结果数据统计
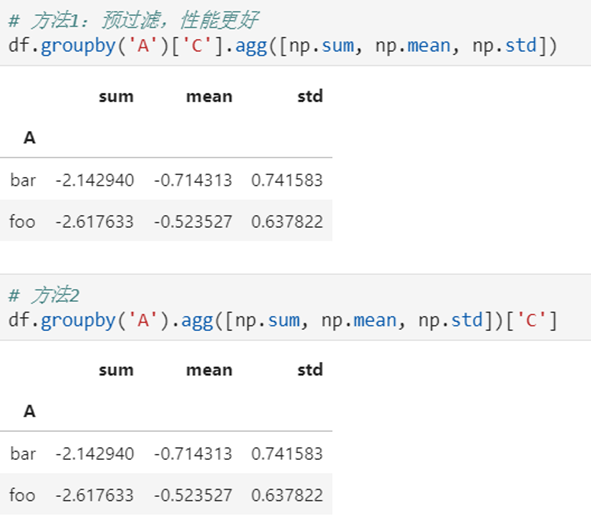
5)不同列使用不同的聚合函数

2 遍历groupby的结果理解执行流程
for循环可以直接遍历每个group
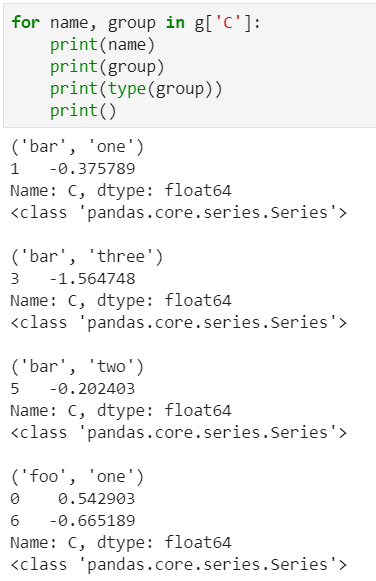
1)遍历单个列聚合的分组
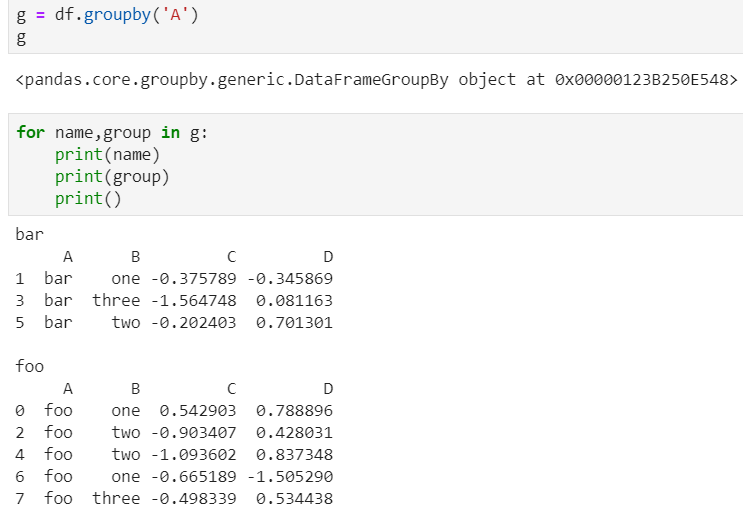
可以获取单个分组的数据

2)遍历多个列聚合的分组

可以直接查询group后的某几列,生成Series或者子DataFrame
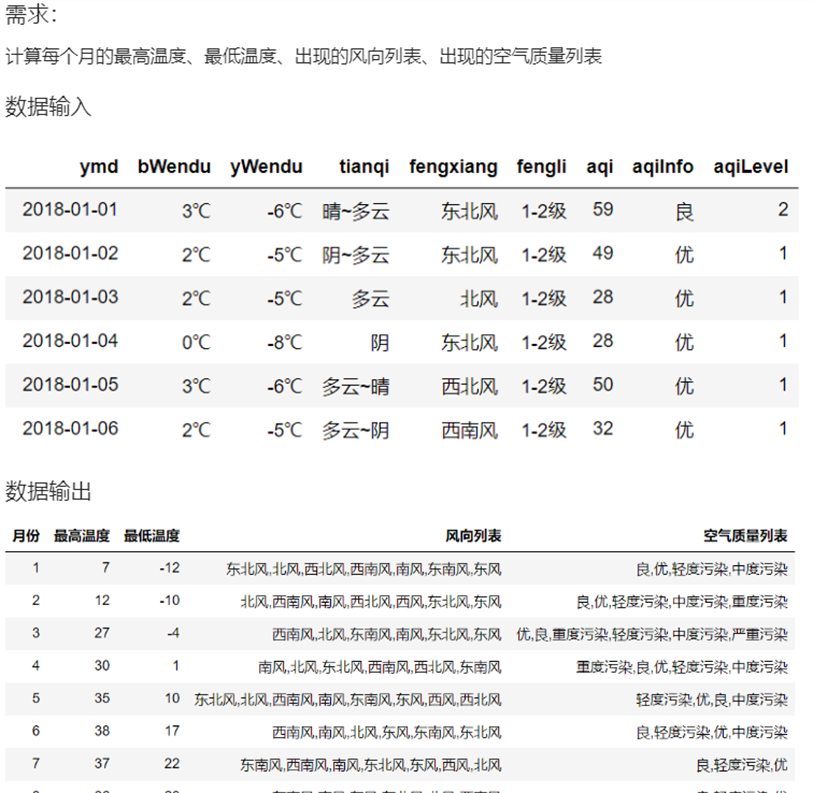
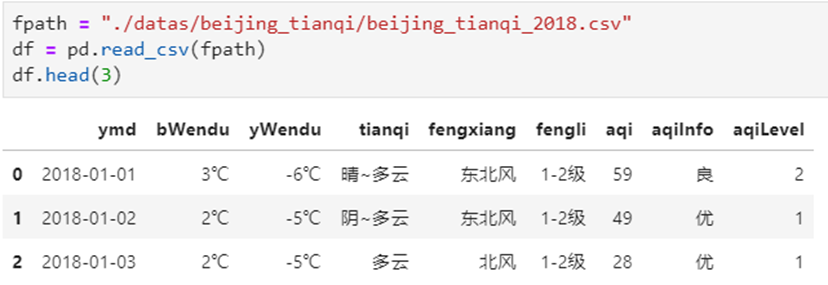
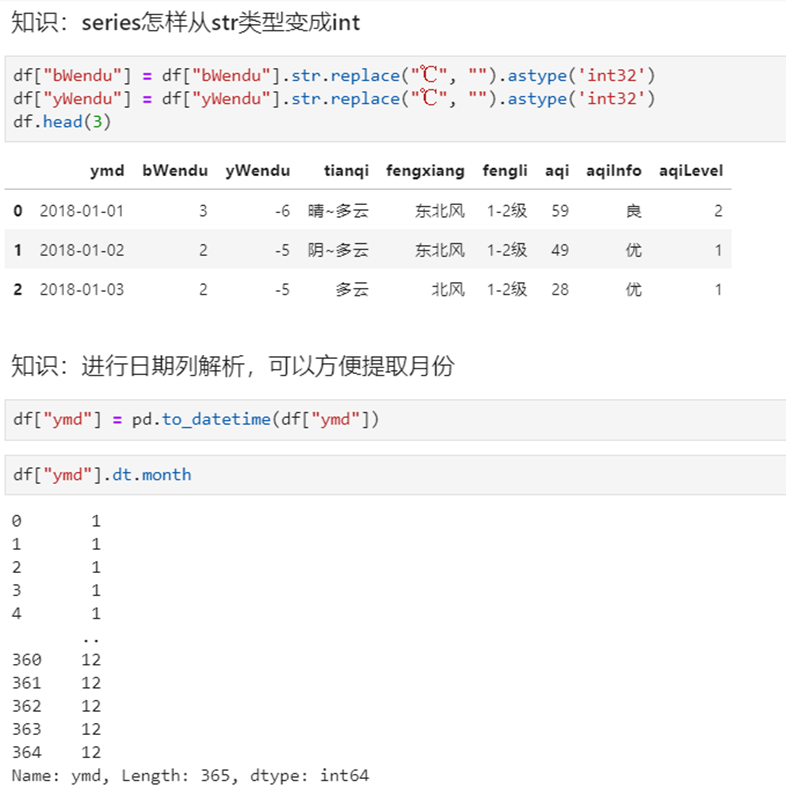
3 实例分组探索天气数据
实验数据
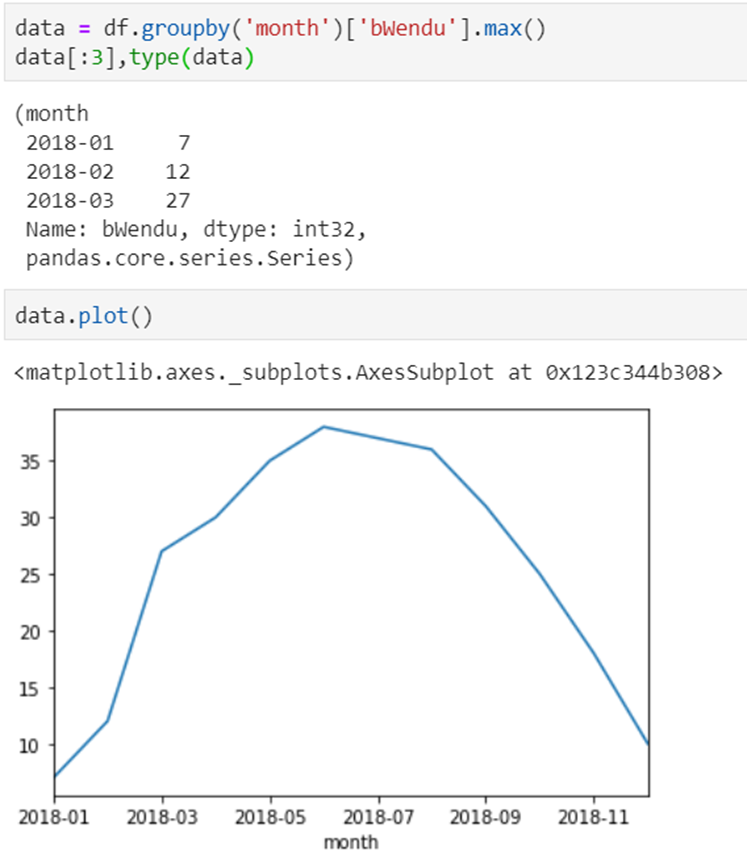
1)查看每个月的最高温度
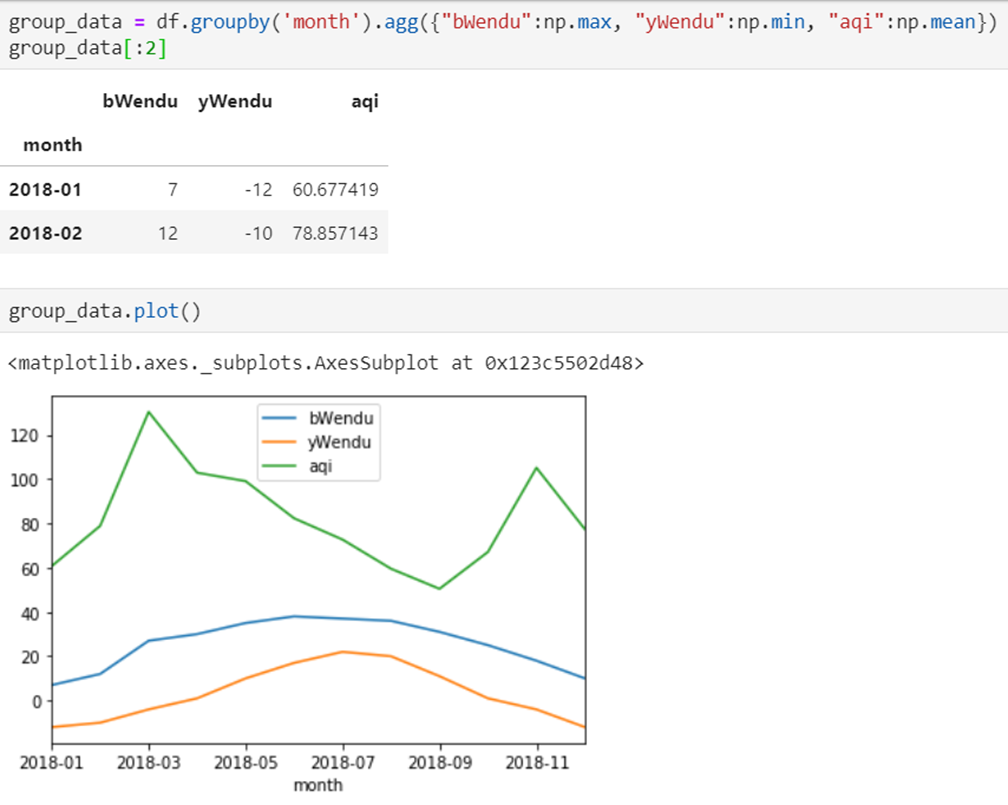
2)查看每个月的最高温度、最低温度、平均空气质量指数
二、groupby聚合后不同列数据统计和合并
电影评分数据集(UserID,MovieID,Rating,Timestamp)
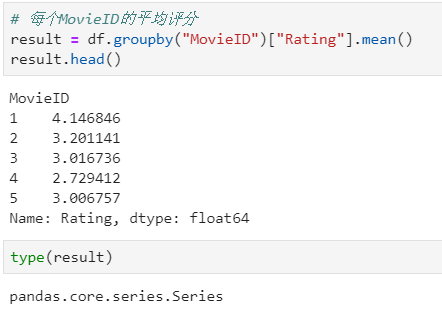
聚合后单列-单指标统计:每个MovieID的平均评分
- df.groupby("MovieID")["Rating"].mean()
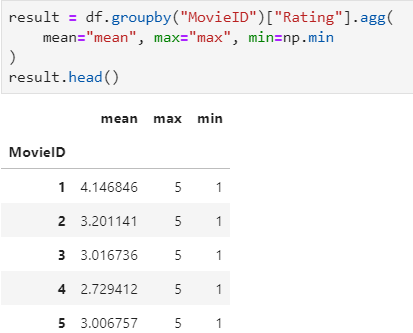
聚合后单列-多指标统计:每个MoiveID的最高评分、最低评分、平均评分
- df.groupby("MovieID")["Rating"].agg(mean="mean", max="max", min=np.min)
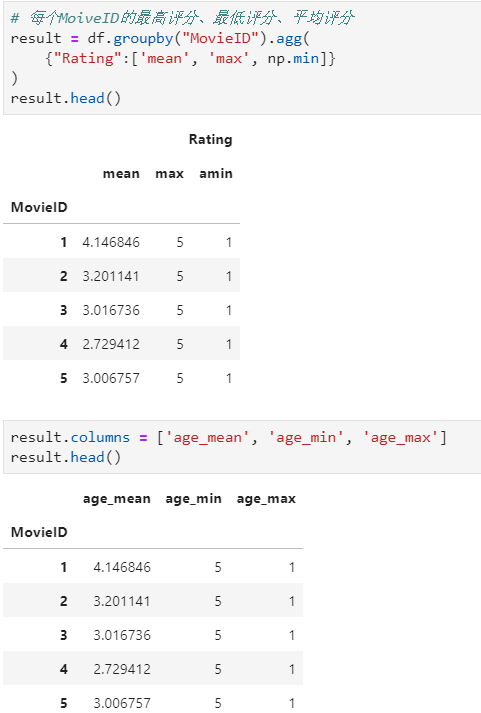
- df.groupby("MovieID").agg({"Rating":['mean', 'max', np.min]})
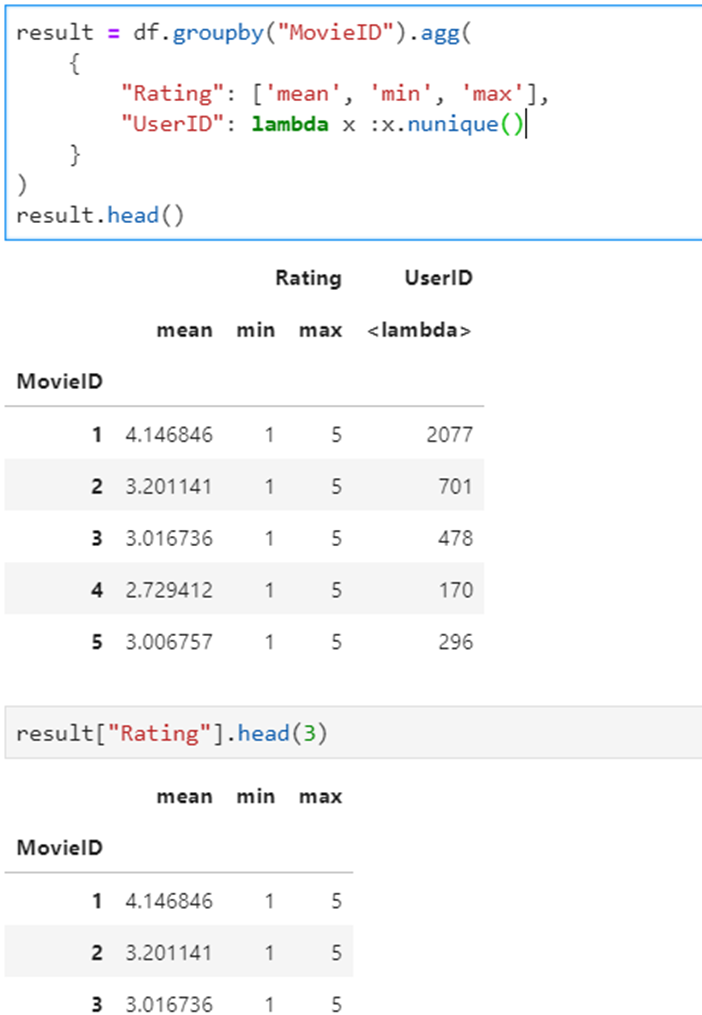
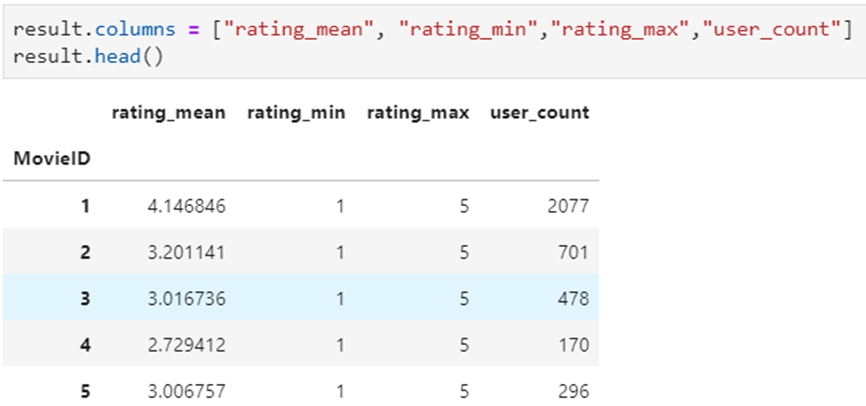
聚合后多列-多指标统计:每个MoiveID的评分人数,最高评分、最低评分、平均评分
- df.groupby("MovieID").agg( rating_mean=("Rating", "mean"), user_count=("UserID", lambda x : x.nunique())
- df.groupby("MovieID").agg( {"Rating": ['mean', 'min', 'max'], "UserID": lambda x :x.nunique()})
- df.groupby("MovieID").apply( lambda x: pd.Series( {"min": x["Rating"].min(), "mean": x["Rating"].mean()}))
记忆:agg(新列名=函数)、agg(新列名=(原列名,函数))、agg({"原列名":函数/列表})
agg函数的两种形式,等号代表"把结果赋值给新列",字典/元组代表"对这个列运用这些函数"
官网文档:https://pandas.pydata.org/pandas-docs/version/0.23.4/generated/pandas.core.groupby.DataFrameGroupBy.agg.html
注意:
- 如果按一列聚合,只传列名字符串,如果多个就要传由列名组成的列表
- 聚合方法可以使用 Pandas 的数学统计函数 或者 Numpy 的统计函数,如果是 python 的内置统计函数,直接使用变量,不需要加引号
1 聚合后单列-单指标统计
2 聚合后单列-多指标统计
每个MoiveID的最高评分、最低评分、平均评分
方法1:agg函数传入多个结果列名=函数名形式
方法2:agg函数传入字典,key是column名,value是函数列表
3 聚合后多列-多指标统计
每个MoiveID的评分人数,最高评分、最低评分、平均评分
方法1:agg函数传入字典,key是原列名,value是原列名和函数元组

方法2:agg函数传入字典,key是原列名,value是函数列表
统计后是二级索引,需要做索引处理
方法3:使用groupby之后apply对每个子df单独统计

4 聚合后字符串列的合并
数据

方法一

方法二

5 agg函数
agg函数一般与groupby配合使用,agg是基于列的聚合操作,而groupby是基于行的
DataFrame.agg(func,axis = 0,* args,** kwargs )
func : 函数,函数名称,函数列表,字典{'行名/列名','函数名'}
使用指定轴上的一个或多个操作进行聚合。

6 使用字典和Series分组
import pandas as pd
路径 = 'c:/pandas/分组聚合2.xlsx'
数据 = pd.read_excel(路径,index_col='店号')
对应关系 = {'1月':'一季度','2月':'一季度','3月':'一季度','4月':'二季度'}
数据2 = 数据.groupby(对应关系,axis=1)
print(数据2.sum())

三、分层索引MultiIndex
为什么要学习分层索引MultiIndex?
- 分层索引:在一个轴向上拥有多个索引层级,可以表达更高维度数据的形式;
- 可以更方便的进行数据筛选,如果有序则性能更好;
- groupby等操作的结果,如果是多KEY,结果是分层索引,需要会使用
- 一般不需要自己创建分层索引(MultiIndex有构造函数但一般不用)
演示数据:百度、阿里巴巴、爱奇艺、京东四家公司的10天股票数据
数据来自:英为财经 https://cn.investing.com/
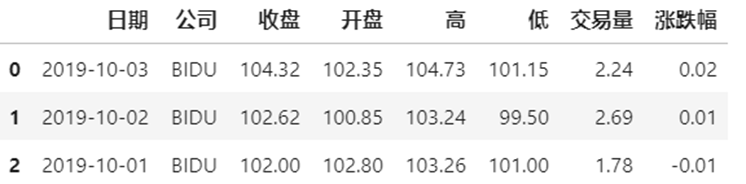
1 Series的分层索引MultiIndex
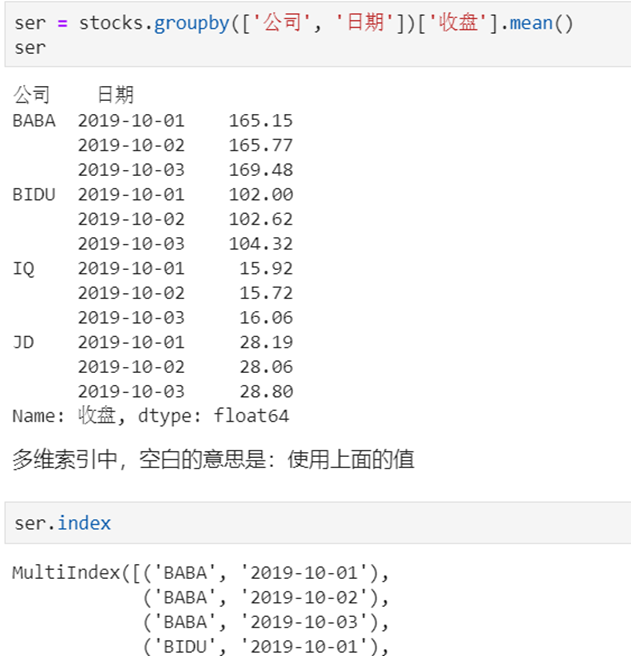
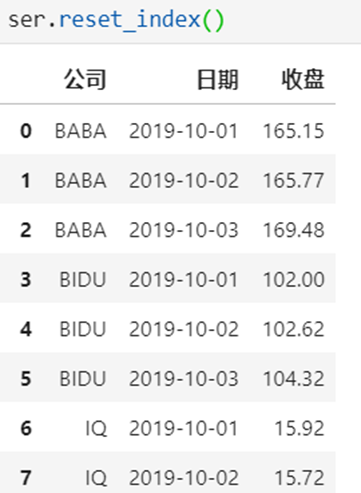
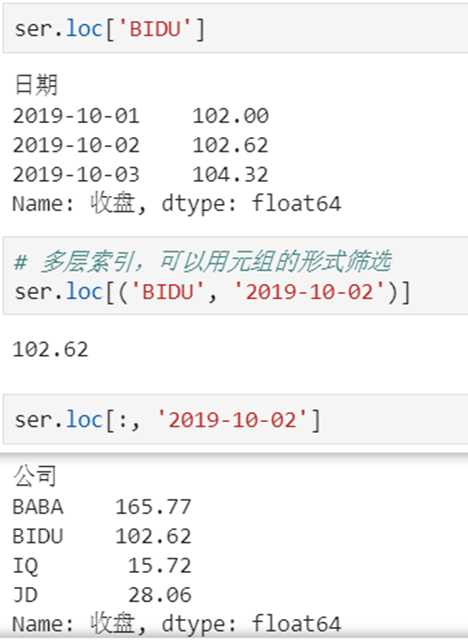
2 Series有多层索引怎样筛选数据?
3 DataFrame的多层索引MultiIndex
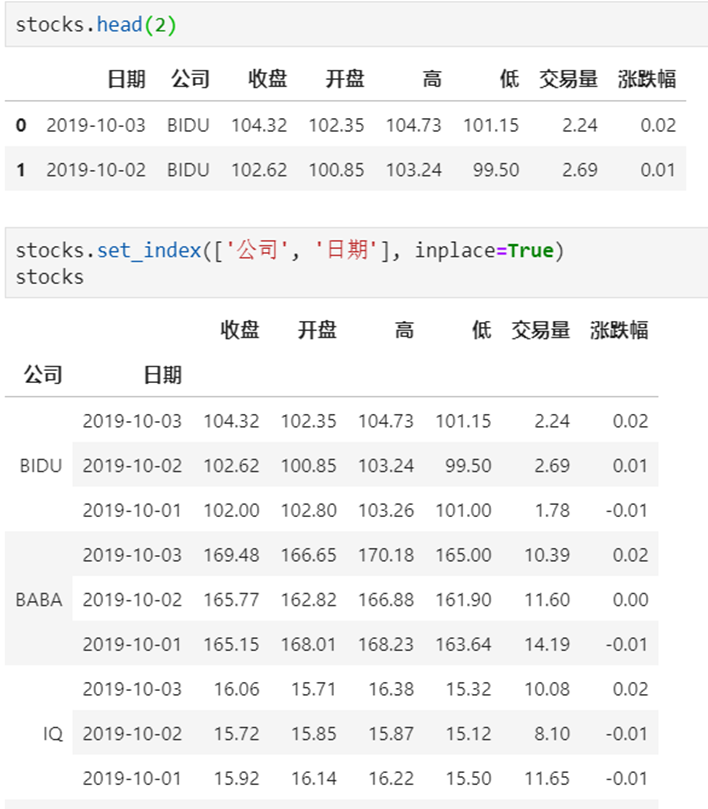
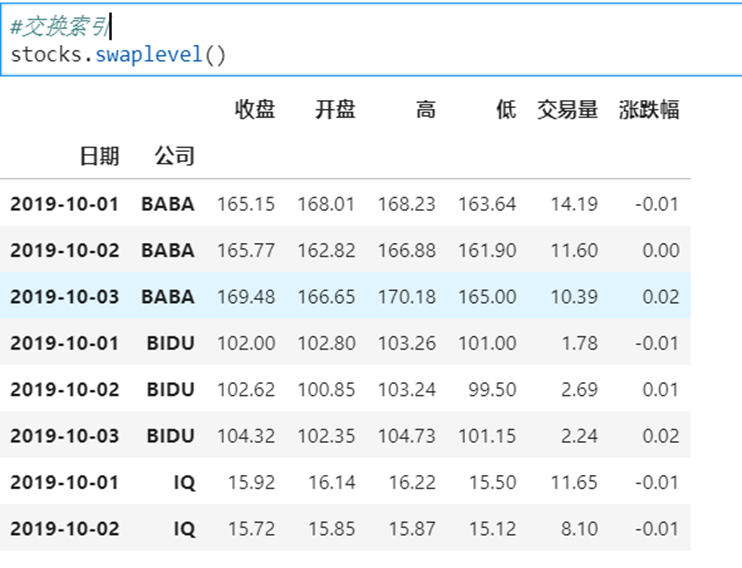
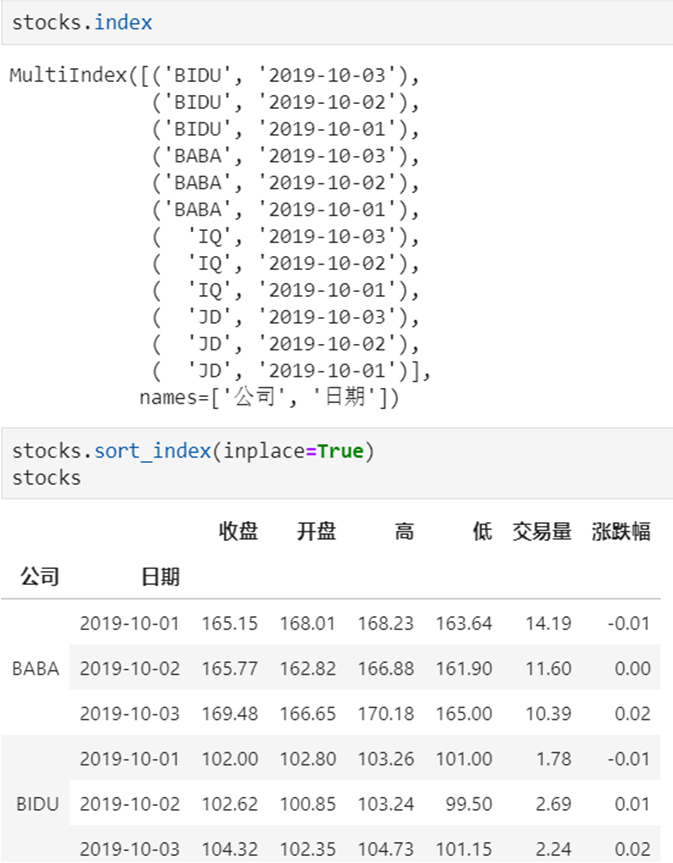
4 DataFrame有多层索引怎样筛选数据?
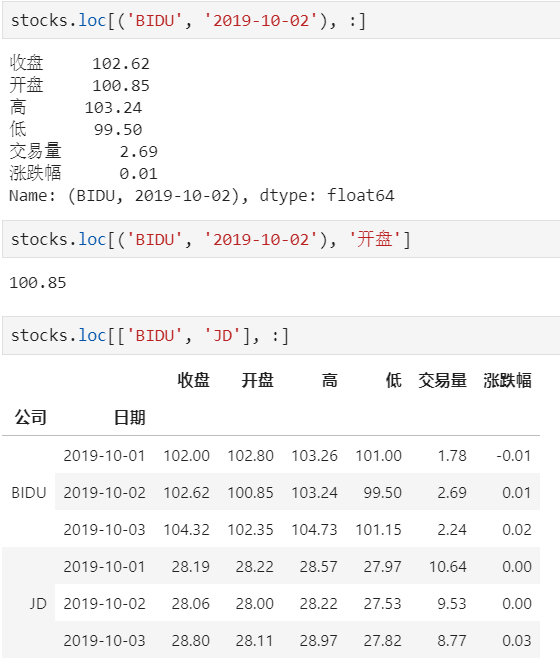
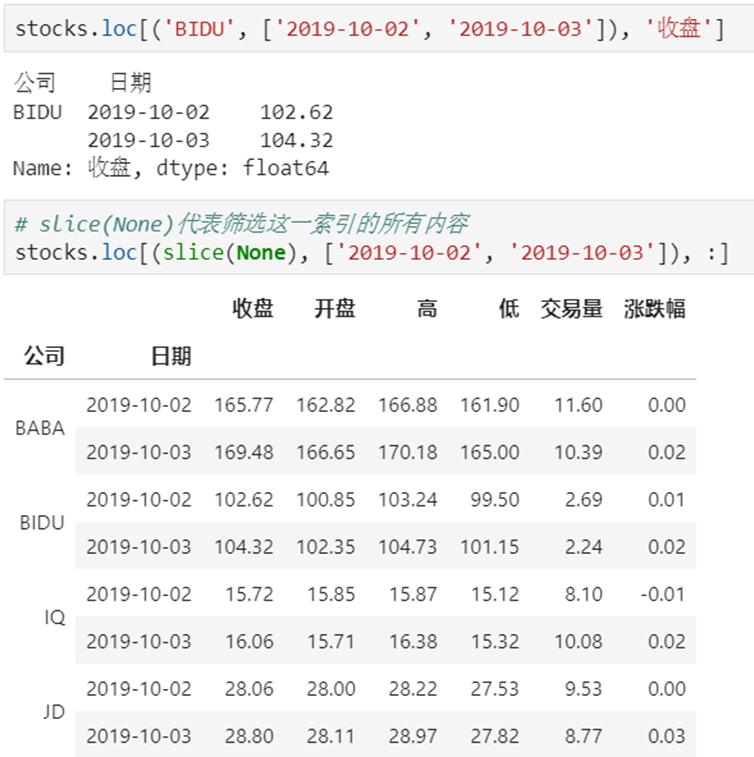
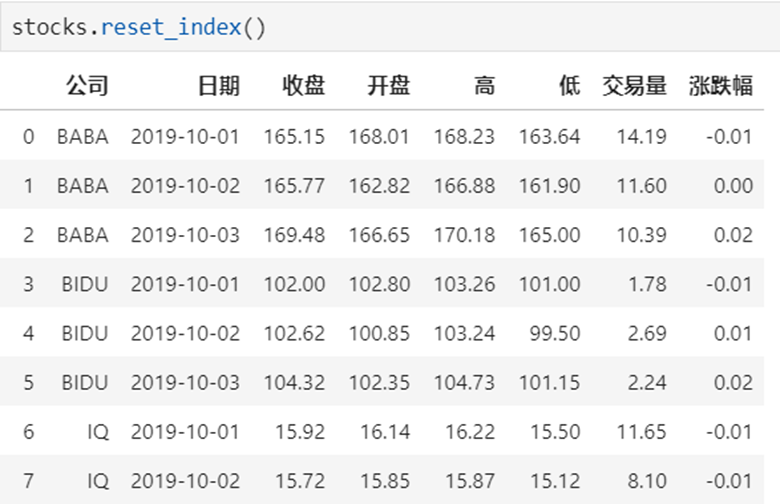
【重要知识】在选择数据时:
- 元组(key1,key2)代表筛选多层索引,其中key1是索引第一级,key2是第二级,比如key1=JD, key2=2019-10-02
- 列表[key1,key2]代表同一层的多个KEY,其中key1和key2是并列的同级索引,比如key1=JD, key2=BIDU
5 多层索引的创建的方式【行】
from_arrays | 接收一个多维数组参数,高维指定高层索引,低维指定底层索引 |
from_tuples | 接收一个元组的列表,每个元组指定每个索引(高维索引,低维索引) |
from_product | 接收一个可迭代对象的列表,根据多个可迭代对象元素的笛卡尔积进行创建索引 |
注:from_product相对于前两个方法而言,实现相对简单,但是,也存在局限。
1)from_arrays方法
from_arrays 参数为一个二维数组,每个元素(一维数组)来分别制定每层索引的内容
import pandas as pd
多层索引 = pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]],names=['x','y'])
2)from_tuples方法
from_tuples 参数为一个(嵌套的)可迭代对象,元素为元祖类型。元祖的格式为:(高层索引内容,低层索引内容)
import pandas as pd
多层索引 = pd.MultiIndex.from_tuples([('a',1),('a',2),('b',1),('b',2)],names=['x','y'])
3)from_product方法
使用笛卡尔积的方式来创建多层索引。参数为嵌套的可迭代对象。结果为使用每个一维数组中的元素与其他一维数组中的元素来生成 索引内容。
import pandas as pd
多层索引 = pd.MultiIndex.from_product([['a', 'b'], [1, 2]],names=['x','y'])
注:如果不在MultiIndex中设置索引名,也可以事后设置
数据.index.names = ['x', 'y']
6 多层索引的创建的方式【列】
在DataFrame中,行和列是完全对称的,就像行可以有多个索引层次一样,列也可以有多个层次。
index = pd.MultiIndex.from_product([[2019, 2020], [5, 6]],names=['年', '月'])
columns = pd.MultiIndex.from_product([['香蕉', '苹果'], ['土豆', '茄子']],names=['水果', '蔬菜'])
数据 = pd.DataFrame(np.random.random(size=(4, 4)), index=index, columns=columns)
7 分层索引计算

四、stack和pivot实现数据透视
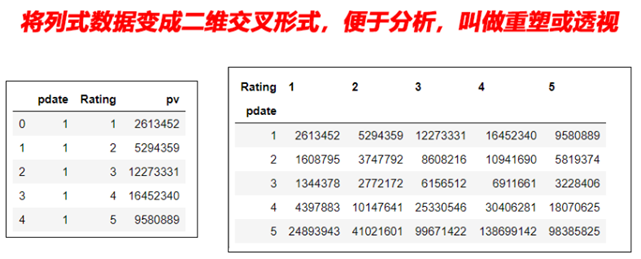
1 经过统计得到多维度指标数据

对这样格式的数据,我想查看按月份,不同评分的次数趋势,是没法实现的
需要将数据变换成每个评分是一列才可以实现
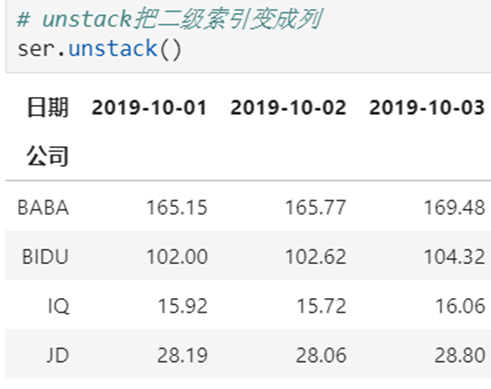
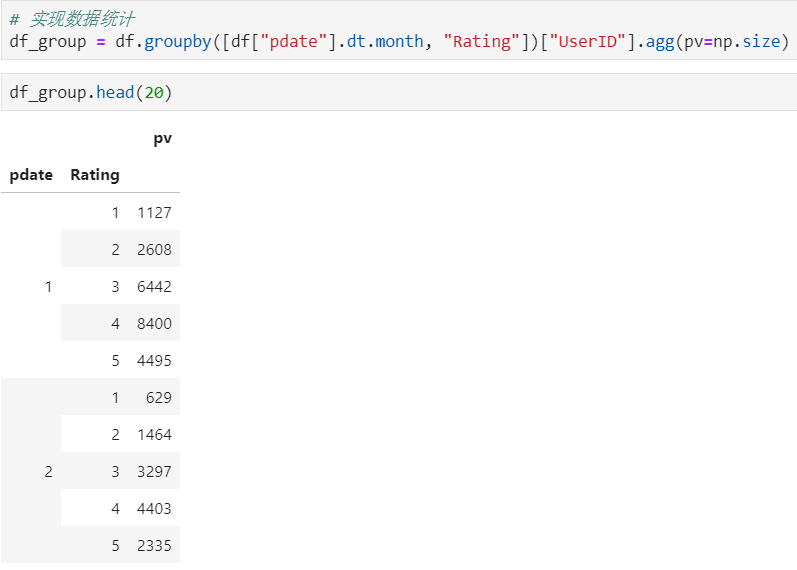
2 使用unstack实现数据二维透视
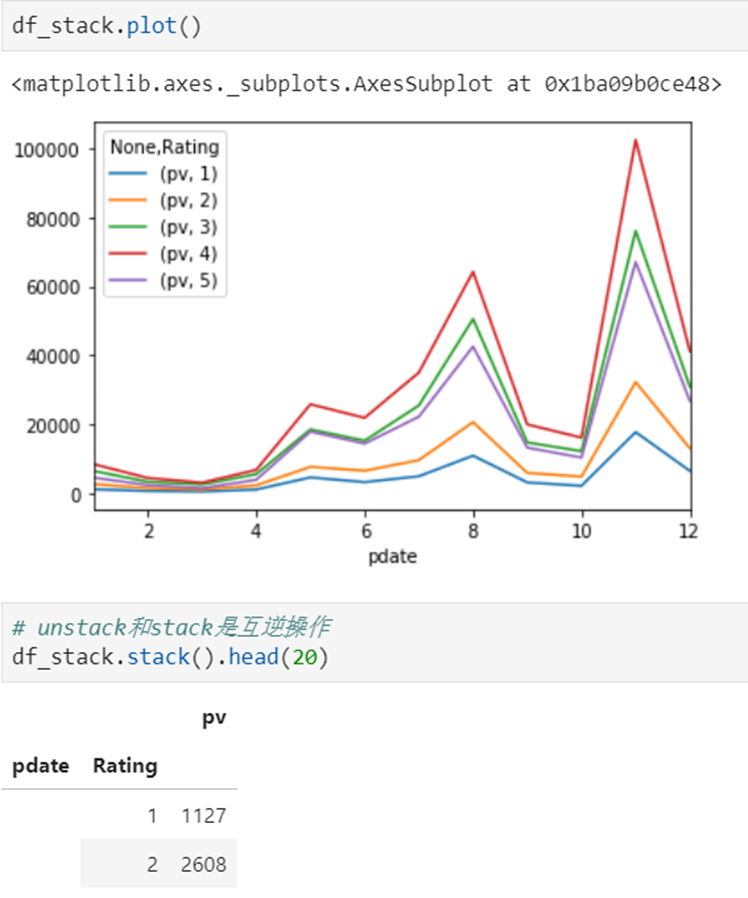
目的:想要画图对比按照月份的不同评分的数量趋势

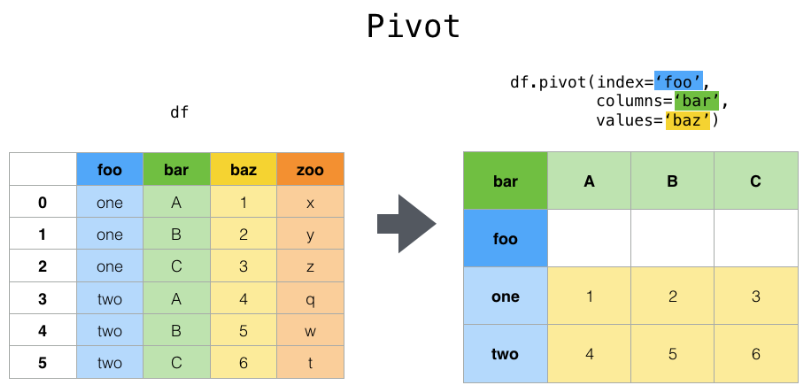
3 使用pivot简化透视
数据
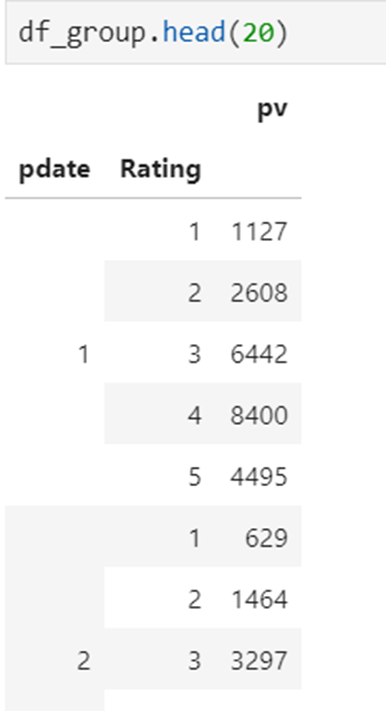
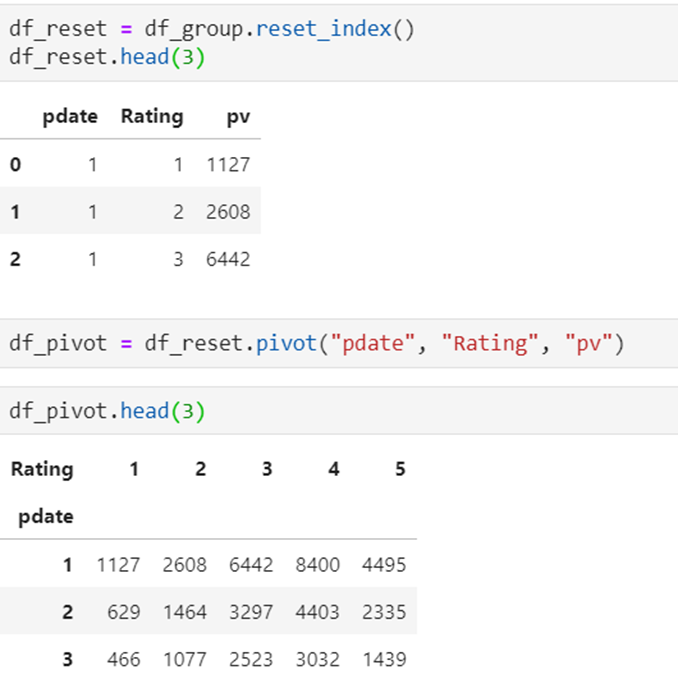
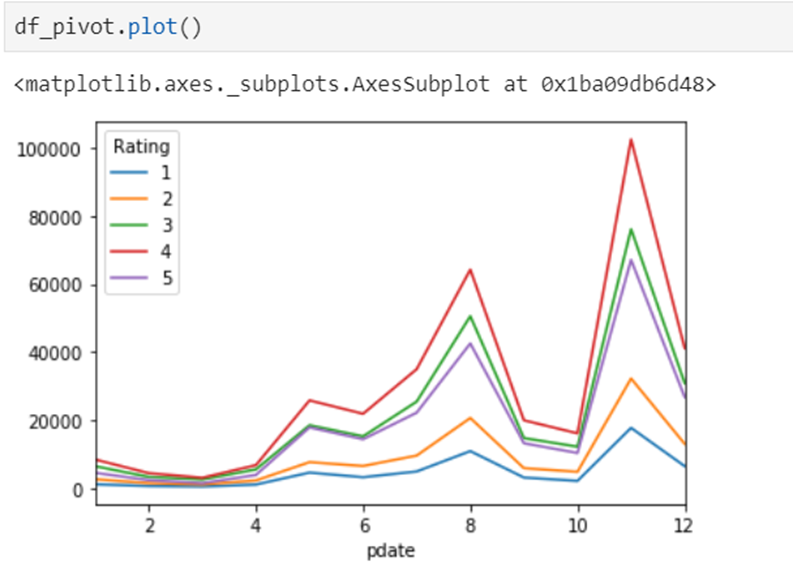
pivot方法相当于对df使用set_index创建分层索引,然后调用unstack
4 stack、unstack、pivot的语法
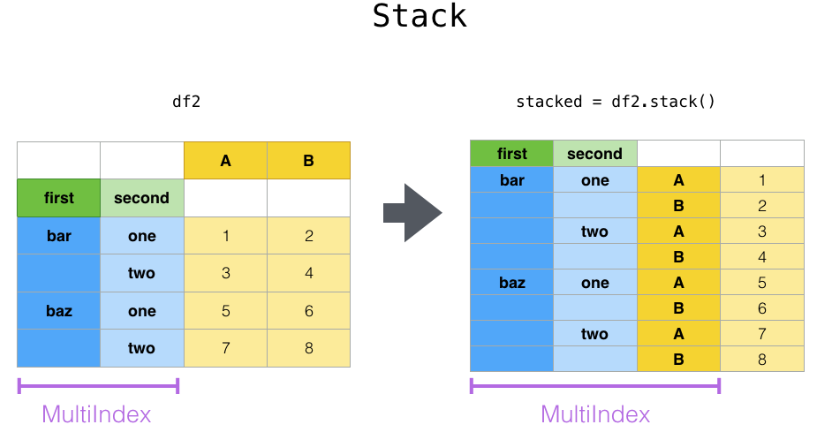
stack:DataFrame.stack(level=-1, dropna=True),将column变成index,类似把横放的书籍变成竖放
level=-1代表多层索引的最内层,可以通过==0、1、2指定多层索引的对应层
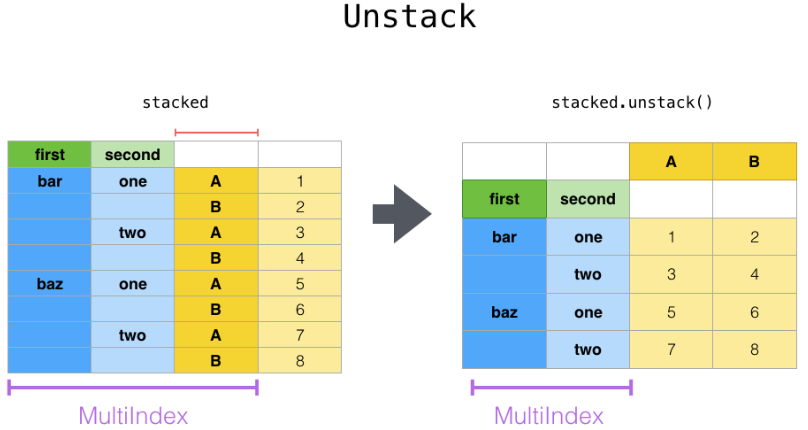
unstack:DataFrame.unstack(level=-1, fill_value=None),将index变成column,类似把竖放的书籍变成横放
pivot:DataFrame.pivot(index=None, columns=None, values=None),指定index、columns、values实现二维透视