https://www.bilibili.com/video/BV1C7411C7CP/?spm_id_from=333.788.recommend_more_video.14








那么主要来事介绍这个语义网数据的这个管理或者呢也可以称为唻是这个啊rdf数据的管理。那么呃,那么这一章来我们大概来会分成两个呃主要的这个部分。那么这个数据管理了,一般来讲呢我们都会包含两个部,第一部分的是关于这个存储。第二部分呢是关于这个检索存储来那么代表的就是说我们的这个数据啊,比如说我们前面学到的这个rdf数据。那么这个数据呢在我们的这个一个地方,那么我们有的存储引擎,比如说我们关系数据库,或者了我们这个rdf自己有自己的分组引擎,我们在这个存储引擎里面怎么样把它存起来。怎么这里面最主要的问题,比如说我们应该采用什么样的结构去存?那么另外呢我们比如说怎么样存可以比较高效?另外一个部分呢就涉及到这个检索。这个检索来就是我们怎么样把我们的这个存进去的数据能把它查出来。之前大家都可以这个学到了,比如说我们说关系数据库,SQL这个语言可以去把它查出来。那么对于这个XML的时候,我们讲到了这个xml可以用xpath的方法去把XML里面的都是假的。那么对于我们的这种rdf数据,实际上我们有一种专门的这个查询语言称为叫sparkle的这样那个查询语言。那么你用这个查询语言,我们可以把存储在这个数据库或者知识库里面的这个rdf数据把他查出来。我们这个主要来分成这两个部分。好,首先让我们来看一看一些简单的背景。那我们的前面的课来学到了很多关于RDF与以往本体等等的许多的这个知识。但是在这里面说我们仅仅如果只想让这个rdf数据啊可以用起来。实际上还远远不够。那么我们想要让这些数据更好地用起来的时候。我们就需要有好多的工具,比如说能处理,转换和推理这些信息。并且来我们需要有方法来存储这个rdf数据和它进行交互。这显然是你也工具。这些方法使得我们的数据rdf的数据不仅仅是变得可用。而是变成了它相对来讲更加好用的这样的目的。那么我们这时候就会引出了我们两个很主要的问题。第一个问题就是说,现在的这些存储系统是不是适合存储这个rdf?也就是说比如说我们现在有关系数据库的这个存储系统,我们在关系数据库这个存储系统里面,我是不是能很好的存储啊?rdf数据呢?这个就是我们遇到的第一个问题。第二个问题是现有的这个查询语言是不是适合能查询这个啊表,比如说我们现在用了一个SQL的语言。我们是不是已经可以把rdf数据很好的查询出来?如果可以的话,那么意味着我们不需要去定义新的查询语言。所以这两点的实际上驱动的我们对于这个语义网数据或者rdf数据。这个存储管理这方面的这个进展或者思考。那么我们现在首先来看一下数据库和这个rdf。我们大家来可能之前比如说我们本科的课,那么本科,因为我教这个数据库的课,那么实际上大家可能都会学到了这个关系数据库,它是一种这个存储的这个剧技术。来存储信息,并且来来提供了这个查询支持。这个查询呢我们一般把它称为来教SQL,或者来这个称为这个读作这个circle。那么关系数据库呢它被设计和实现的主要是针对呀。这样的一种情况,你就说这些情况呢是他不常改变这种模式。也就是说这个这个表关机数据库的这个表一般来讲我们一旦把这个表的格式把它确定下来之后,那么实际上我们很少再去改变这个表,虽然它允许改变。但是一般来讲我们的改编的不是很频繁,我们主要来是在这个表的结构下。我们怎么样去尽可能多的尽可能好的把这个数据啊?比如说我们现在假设我们有一个IDF数据的片段,大家可以看到这是我们啊df数据的一个片段,这个是我们之前课提到的过的一种,用这个长形的long form的形式去写打点。如果你不记得这个long form是什么东西了,那么你可能来这个要回顾一下。那么我们在这里看到我们说啊我们有一个rdf的片段,所以有一个人或者有一个人他叫这个949318的这样一个编号的一个东西。那么这个是我们做的一个URI。那么它的类型呢是什么呢?它的类型是个lecture,是个是个讲师,他的名字来叫这个determine the他的title来是一个学校的这个教授。那么现在我们对于这个很简单的这样一个啊df的这个数据片段。我们如果想把它存在一个关系数据库里。那么首先来看一看我们有什么样的一些方法可以去把它存下来。首先我们做第一种可能的这个方法。那么第一种可能的方法就是我们用传统的关系数据库的方法就行。比如说我们现在有这样的一个关系数据库,这是一个表,这个表来我们给它起名字叫讲师。这当兵。那么在这张表里面呢我们可以设置三个列。第一个链是这样子的id,第二个裂了叫那第三个练了就要这个title。然后在这我们存储了一行记录这行记录里面说的有一个949318。嫁了一个人这样一个id,他的内容是什么?她的title是什么?这种情况下就是我们一个传统的关系数据。这个传统的关系数据库就是这样,我们有一个表的名字,然后呢有几列每列来存储了我们记录中间的一个字段,就是我们传统的关系复读。那么这时候我们可能会遇到一个新的问题,也就是说如果没有传统关系数据库来存储的话,我的一个问题是什么呢?是如果我们现在要添加一个新的概念,比如说我们现在要添加一个新的叫这个副教授associate professor。那么这时候我就不能存在这个lecture的党表里面。我就需要创建一个新的表。这个新的表叫这个associate professor,然后呢下面还是一样的id,那抬头的执行力。这个实际上这种方法那么很容易,大家可以想到,那么他会产生了一个问题,就是缺乏可伸缩性。因为比如说对于我们这个传统的这个本体来讲,我们一般来讲在一个稍微大一点规模的本体里面,那么他的累很多,那么意味着我要创建很多很多的这个表。那么有的人说我可能呢可以通过把这些表合并,比如说我建立一道新的表。这张表来就要这个呃faculty,然后来增加一个列叫lecture,然后再叫associate professor等等的。那么这时候嘞这些东西啊,这个表啊时机的那么这样的去创建的时候,那么又丧失了我们之前说的这个里面的推理,那么它的一个层次结构。所以在总体来讲,那么在这样的一个过程里面,我们首先来讲,如果门卫每一个概念都要创建一个表的话,那么实际上是一种缺乏可伸缩性。同时呢我们也缺乏一些这个动态性,因为一旦这个表固定的,比如说我们创建了这个lecture,这个表那么意味着这个lecture这个表啊里面它只能存储这个角色,那么这个表来也不好再随意去改变。那么时尚最重要的一点是在如果我们把数据存储成这个关系数据库表的这个形式的话,那么他就不会再遵从r ds的这个原则。因为在这个表里面大家可以看到它完全是一个关系数据库的形式。




而这个表里面他没有任何的三元组的信息单。对,这就是我们最大的一个问题,我们在这个表里面实际上已经把RDF的三元组的这种结构信息啊或者丢失掉,只剩下了我们说的啊跌幅的。这样的一个呃只吃下了一个关系数据库的东西。所以呢这个实际上和我们的你往的这样一个规范或者渔网的设计思想来讲,那么他们是不吻合。那么我们现在又可以说可能那我们还有一种设计方法,这种设计方法我们把它称为叫基于三元组的方法。在这个方法里面呢,我们一般来讲我们会定义一般三个列。三个列了,第一列是主语。第二列了是我们说的这个位置,那么后面两年来你可以认为它是宾语。在我们的这个啊dx的规范里面,大家还记得我们说我们的这个宾语啊实际上有几块东西,宾语里面。一种是我们的URI,一种来世我们再次面料URI和字面量,实际上两者之间是这个不相交的,也就是说一个对象。那么他嘞g不可能是URI也做,要不然是URI,要不然呢就是一个自变量,两者来是不可能,同时这个这个都有值得虽然在这种情况下,我们为了这个性能,我们可能呢不是把它分开。本田两列你列来称谓叫这个object URI,它存储的是一个URI,那么对应的它的这个literal这边就唯恐。如果来它的取值是一个litter,那么意味着在他的这个URI这边来就胃口,虽然你可以把它认为了这两年来是一个互斥的关系。那么在这个表里面实际上一般来讲我们还会做一点点优化,也就是说在这个表里面我们会用一些编码的形式。来替代这个哟啊。在家可能会看到在这里比如说我会说101101对应的是怎么了,对应的是我们右边会建一个专门的resource,这个表。这个表里面我们会说101对应的是刚才的一个URI叫949318的远。R102来是我们的一个谓词,它对应到的是IDF type。然后同样的对于literary来讲,我们也可以说,比如说201对应的是这个determine the这样的一个字符串。金总方法,实际上它的好处是怎么的?好处是对我们的这个三元组的这个statement这张表。尽情的这个压缩,因为大家可能知道我们在这个you're呀,有长有短。有时候在家平时你去搜索这个新浪网,那么新浪网的网址很短,能把心脏点COM点cn就可以了。但是呢你如果是谷歌上搜索一个东西,那么他的这个链接很长,那么如果你直接把这个URI存储在这个格子里面的话,那么势必我们大家可能有一些关系,数据库基础的时候你都知道,那你可能要按照这个最长的剧存储或者来你用这个可变堂的字不断地去存储的话,那么也面临着你的性能会比较下降了,你知道吗?所以呢这个量呢我们做了一个简单很简单的优化,也就是说我们在这用一个编码的形式来代替原来的油啊。指的这个表唻占用的空间,它的存取效率地对提供这个人是我们使用这个三元组的这个方法去做这个方法,他会有好处。大家看到我们刚才说前面的那个问题里面前面的关系数据库的存储方法里面最主要的问题是它破坏了我们啊df的三元股价。而这张表里面我们实际上没有破坏的,我们从这个表里面直接可以看出来,这就是一个三元结构。就三元组的结构实际上使得我们的这个雨衣,外国的这个IDs数据的这个信息啊这一完整。所以这种方法来看似好像挺好的,那么它是基于三元组的方法,那么比较灵活,那么也没有我们刚才做的各种问题。知道我们可以来谈谈。那么我们可以说啊这个缺点可能是这样,比如说我现在对于动态添加id,f三元组而已呀这样子的一个表三元祖级形式的字存储啊。是非常容易扩展。但是呢他的这个一个小问题是他不能再去修改这个数据库的节奏了。这个数据库的结构就是我们三元组的形式。而更重要的一个问题是,如果对于查询而言,那这样的一个事情,他到底是行不行?基于三元子这个方式,它的查询效率是不是很高?那么现在我们可以说假设啊我们就使用这个原声的啊df的存储方法。我们现在举一个例子。我们说啊,我们想发现所有讲师的名字。你就说我们想放假,所有讲师叫什么名字?这个呢在传统的数据库里面大家可能知道我们就是一条这个。Select语句这条select语句或select name from the lecture。意思是从我从lecture这个表里面查询出来他们的那么我们前面说啊,我们原来在这个关系数据库的这种表示方法的时候,我只要去查这个lecture,这张表单独查这张表。那么它很简单,很快速,很有效。而且呢他也不需要做任何的这个连接操作。这个连接操作了我们这里大家可能会知道它是数据库查询中的啊。最昂贵的一种操作。但是呢实际上我们前面也说过了这个方法的缺点,这个方法的缺点就是它没有可扩展性。并且来他破坏了RDF这个结构。同时我们说啊,刚才我们说我们说这个基于三元组的这种存储方法似乎是比较好的一种吧。那么我们来看一下这个基于三元组的这个方法,那么他又是一个怎么样的给查询?大家来看一看,实际上我们想在刚才的那个三元组表里面把我们说啊这个所有的教师的姓名,把它查出来的话,这时候需要一个很大的这样这个产品大家来看一看。我们是一个什么样的意思?我们给大家来这个一点点时间,大家来看一看。大家可以看到我们这种基于三元组的这种关系方法,那么实际上呢它会有一个很大的这样子就查询这个查询里面他做了很多的事情。手机让我看这边它有很多的这个inner join的这样的操作。这些inner join的操作是什么意思的?实际上是他要把数据库的表和表。做一个连接操作。因为我们刚才看到我们说啊,我们对于为了存储的高校来讲,我们会把一些literal一些id就是URI。我回来把它进行一些编码。同样的,我还需要呢让一些我们说的这些位置等等的把它连接起来。因为大家想到我们刚才讲的是什么?我们刚才讲的是他是以三元组的形式去存储的,每一行只是一个三元组。那么比如说我想象一下,我要查所有的讲师,我要首先呢去查一个人。他的这个太酷了,是一个讲师,同时呢那么我要去查这个人的名字。那么这时候这个人在这个位置上他就需要做这个连接操作。而实际上待遇我们的这张表里面我们这边大家可以数一下,我们有好多个这个链接操作。才能完成我们说的一个基于这个三元组形式存储的这样一个查询。那么我们前面刚才说过了,基于这种连接操作的差距实际上是一个代价很高的,在数据库里面连接操作是一个代价很高的操作。所以那么我们现在可以看出来基于电脑三元组方式的存储。它会有一个很大的问题也就是说他虽然存储的时候啊这个解决了刚才关系数据库的存储问题,但是他在查询的时候,他的效率远远不如关系数据。他的效率是很低的。所以这种基于三元组的存储方式的方法,那么他嘞本质上来讲也不是一个很好的解决方案。

比如说在我们的这个里面我们详细的看一下,那么这个查询啊它很复杂,还有五个drawing。他需要很多的专门针对idea和三元组数据存储的优化。因为不优化的话,你这五个drawing啊做起来这个速度啊非常满。但是呢你针对啊df三元组的存储和优化了这个在关系数据库里面实在是不具有。因为关系数据库啊他设计的实话,他没有针对我们说的啊df或者三元组的总数。那么所以呢,如果我们想为了获得高效率,那么我们就要在这个数据库上再建立一层。更重要的是我们做传统的这个SQL这种团这种传统的。关系数据库的查询语言,他不适合来去查询rdf的这个结构。所以这时候我们就有一个问题,也就是说我们到底是不是需要一种新的查询里面。而不是仅仅啊用这个SQL这个语言去查询。






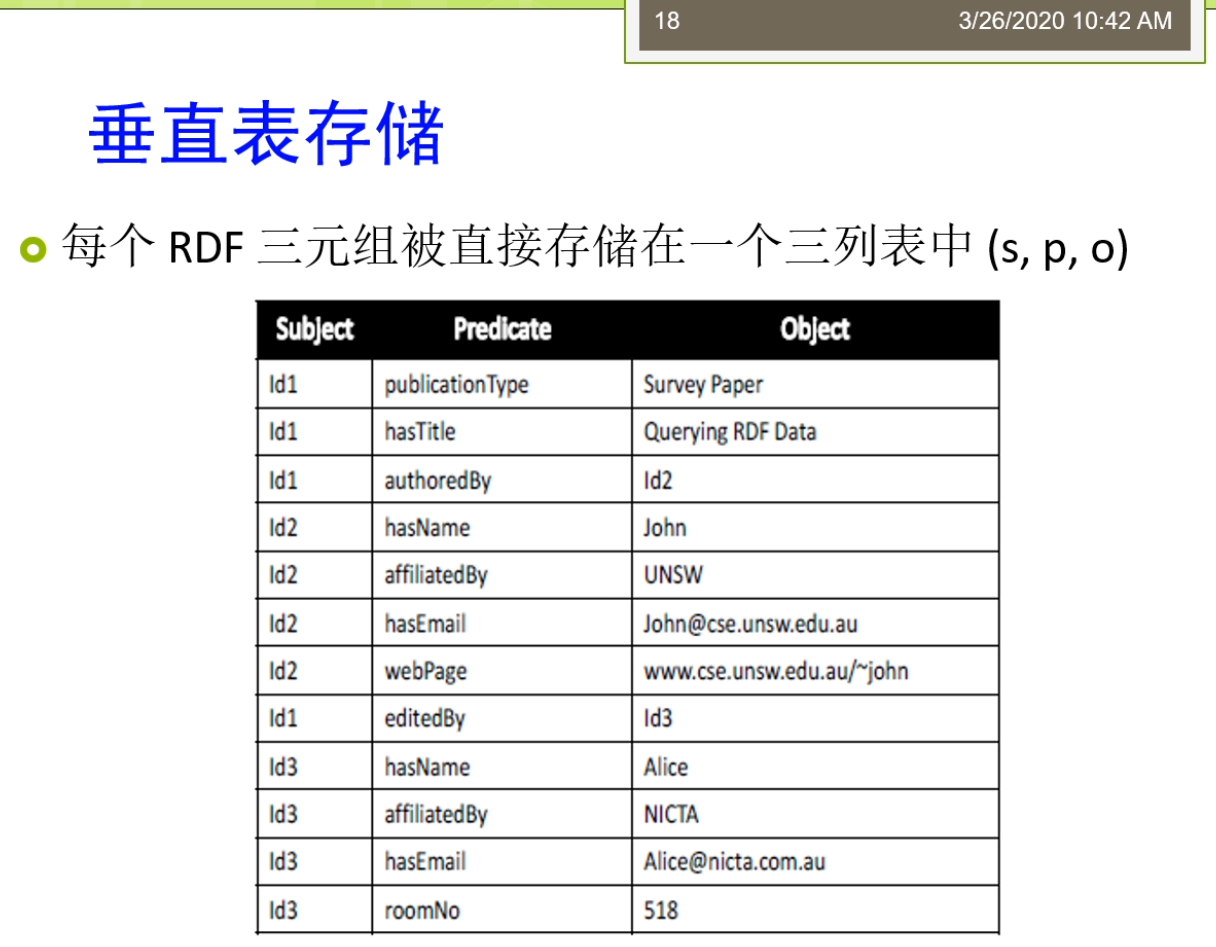
哦,前面呢就是我们说一些这个前面的一些简单的,通过一些简单的例子。我们给大家介绍了一下你的这个背景。那么我们现在奶奶看一看我们真正的这个IBM存储啊,他的一些细节以及呢它可能里面出现的问题或者她的意见以及这些问题他的解决方法之前。那么我们现在呢首先来看一看,第一个说基于表结构的这种分床。总体来讲来在我们的这个里面,基于表结构的主要呢会分为三种不同的三大类,不同的体系结构。第一种粮把它称为了就要这个内存是的,也就是说这个数据是放在这个内存里面。第二种呢,我把它称为调原声似的。那么原生是的呢?那我们等会会看一下例子,还有一种呢是不是原生的也不是内存,是那么我们来看一看这三个的细节。第一种内存是的方法。那么它的处理方法是它以啊df图在形式,也就是说以三元组的形式把这些数据直接存储在我们的主存你们这里的组成一般就是指纹的内存令。比如说我们提到过的这个阿帕奇有一个这个叫接纳的三个工具。或者呢原来还有个叫sesame的这样的个公主。这些工具啊他们都可以去解析一个RDF的文档。把这些IDF文档以图的形式这个读取到内存里存储在内存里。以后嘞,你的这个查询实际上也是在内存里面针对这个图了,要不然那么几种方法为什么称为内存?是因为它只存在于内存,它不会再把这个数据啊这个读到内存里面的东西写到这个字带上。所以呢你程序结束之后那么就没有这样的一个400M的这样的一个啊df图。第二种呢,我把它称为了叫这个原生的。原生的奶主要是基于数据库实现的一些19话的存储系统。那么它基于的是数据库去实现。它提供了对失误的这个支持,自己的边查询编译器。以及的过程语言等等。那么这种方法嘞实际上那么他是许多人都是由一些数据库厂商那么开发的。有时候我们说session米兰有一个这个native讲一个形式,还有我们用的比较多的效果two so。这个这个Oracle等等的这些东西,那么他们实际上自己的提供了自己的查询编译器。以及的这些过程语言。那么几种方法呢?实际上它是持久化存储,他和我们内存是的存储不一样,它是一个持久化存储的。那么还有一种呢是村委来叫非原生非的城市。那么它是建立在第三方数据库上的一种持久化存储系统。有在这个接纳他原来有一个叫sb的。如果这个SDB实际上它是建立在别人数据故障,他在别人数据库上又包了一层。那么这样的一个形式来被称为来就要这个非原生非内存姓,他可以比如说基于我们不做买circle,再买收购的基础上fall,it也可以的,放到别的地方,比如说搜狗server上面就不好意思。所以呢他底下是利用了我们做的第三方的数据库,他在上面来提供了针对这个RDF数据的管理和查询这样一些东西。能把现在来讲来。那么总体来讲,那么我们刚才看到这个内存是的方法呢它比较特殊,因为他不是一个持久化的模型。而相对而言呢,现在来讲这个原生是的要比这个非原生非类等式的影响还是要多一些。因为这个原生式的方法,那么他更好做到性能的那个优化,因为底层的这个存储也是他自己控制。那么同样的在这里我们还有一些这个指标上的一些东西。比如说我们说可伸缩性。那么这个内存是的存储方法,一般来讲来它都无法和持久化存储的存储容量去相比。为内存是在这个存储方法,它的效率相对来讲,那么比如说受限于内存的大小,他不可能做得很大。同时对于不同查询语言的它的支撑支持程度也是不太一样。有说像这个sesame,那么他有自己的查询语言,叫se。也可以了,他支持spark。那么Oracle的这个11寄来,那么它只支持自己的这个查询。那么这时候他们就出现了一些不一样。因为俩还有一些不同层次的推理的支持。因为一般来讲我们在通常来讲,我们在查询这个的事情里面,我们可以考虑推理也可以了,不考虑退,不考虑推理的话就变得我们直接把数据的查出来,这个人好像是讲也没错。但是也有一些方法来,它支持一定程度的腿。有时候这个30m还支持这个啊DFS的推理。那么这个Oracle来支持的更强一些。而通常呢这个内存是的存储啊,通常都支持的是比较高级别的,不会。有坐下这个pilot接纳等等,它里面的这个推理机啊相对来讲能力的就比较强。要死的。实际上这里来大家也可以比较容易的去想象。因为我们在内存里面去操作,那么因为我的数据,所有的数据都装载在这个内存里。我去做推理是比较简单。I如果咧,我数据是存储在这个外侧地面,有时候我们磁盘里面。那我去做这个推理的啥是很困难,而且效率是很低的。那么这这种上面的差异适当就造成了我们说内存似的存储。通常支持的都是这个高级别的,对不对?那么另外呢,我还考虑比如说是不是缺乏这个互操作性以及可移植性。这些问题的主要更多的是存在于原生的这个存储系统。好,我们来看一下,我们说啊这个存储了,第一种,我们把这个任务啊这样子去描述。我们这边呢有这个三元组叫sp。SPO来会写的这样的一个形式,三元组的形式。有时候我说Compaq的一是一个人,那么他有个for那。For name,that是一个我们做字不断。然后来contact的依赖他的态度来十个person,他的mailbox展示一个另外一个URI。那么这个呢我们还是回到我们第一种存储方法,我们又关系数据库的这种。关系数据库的这个存储方法里面我们就有id for那title。Type和这个没有box这五个不同的,这样肯定。这些恋爱实际的表示的,我们把这个相映的一行一行的记录啊或者存储进去。那我们前面提到,我们这个里面虽然我们上面的这样的一个图片里面我们看到的都是比较短的字。但是实际上在我们的真正的啊df里面,那么这些东西啊它十大是一个字符串,是一个又矮。You're可能得很长。比如说刚才我们说的contact,他可能对应到的是一个相对来讲比较完整的。这个相对来讲比较完整的一个很长的一个一个一个一个字符。那么这样的一个情况下呢,我们刚才也简单提到过,很直接的一个方法就是我们要将这个URI和字符串呢映射到一个整数。怎么映射为一个整数呢?它可以节省空间。意味着藏的值啊只被存储一次了,那么不需要存储很多次。有说我们这边看这个contact me,那么他们是一样的,所以呢他可以被存储的。这个只要存储一次很长的纸,那么别的地方呢都用这个短值来表示。因为他还可以做了这个快速处理。也就是说对于整数,比如说我们把它编码一个整数以及和字符串的这个相比的话,那么肯定的是这个整数的处理,它的效率要更高,它比字符串呢它的效率要高。
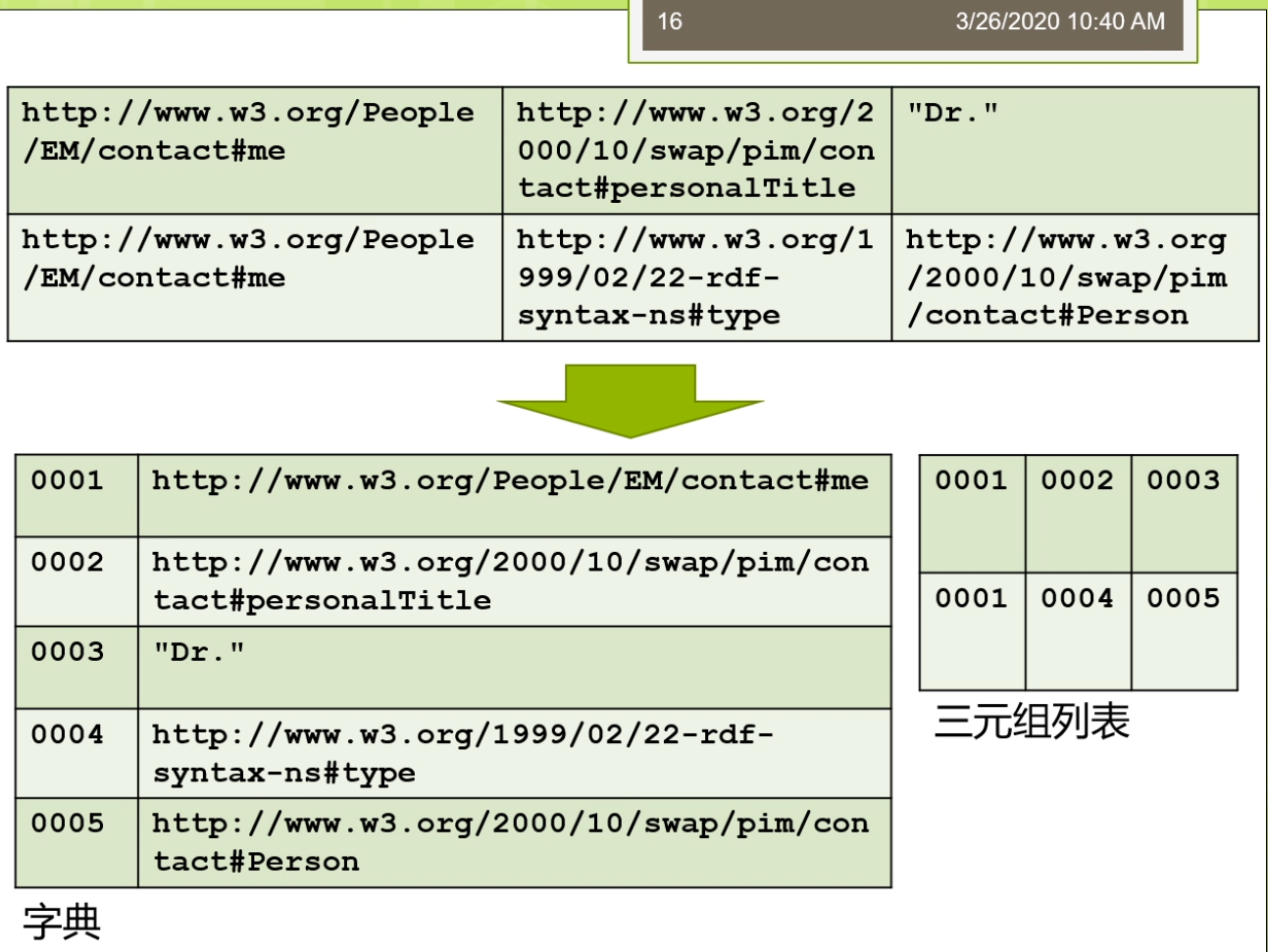







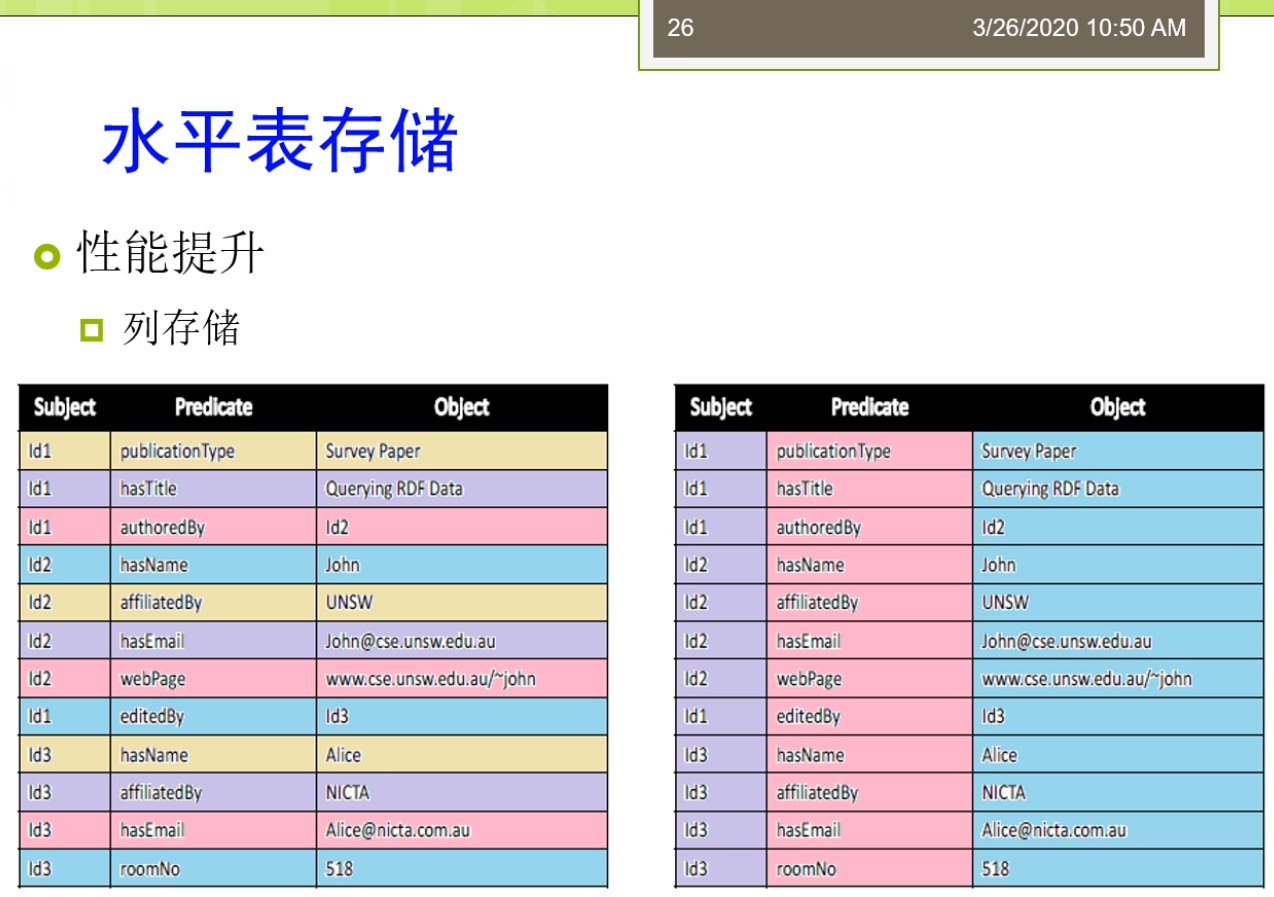








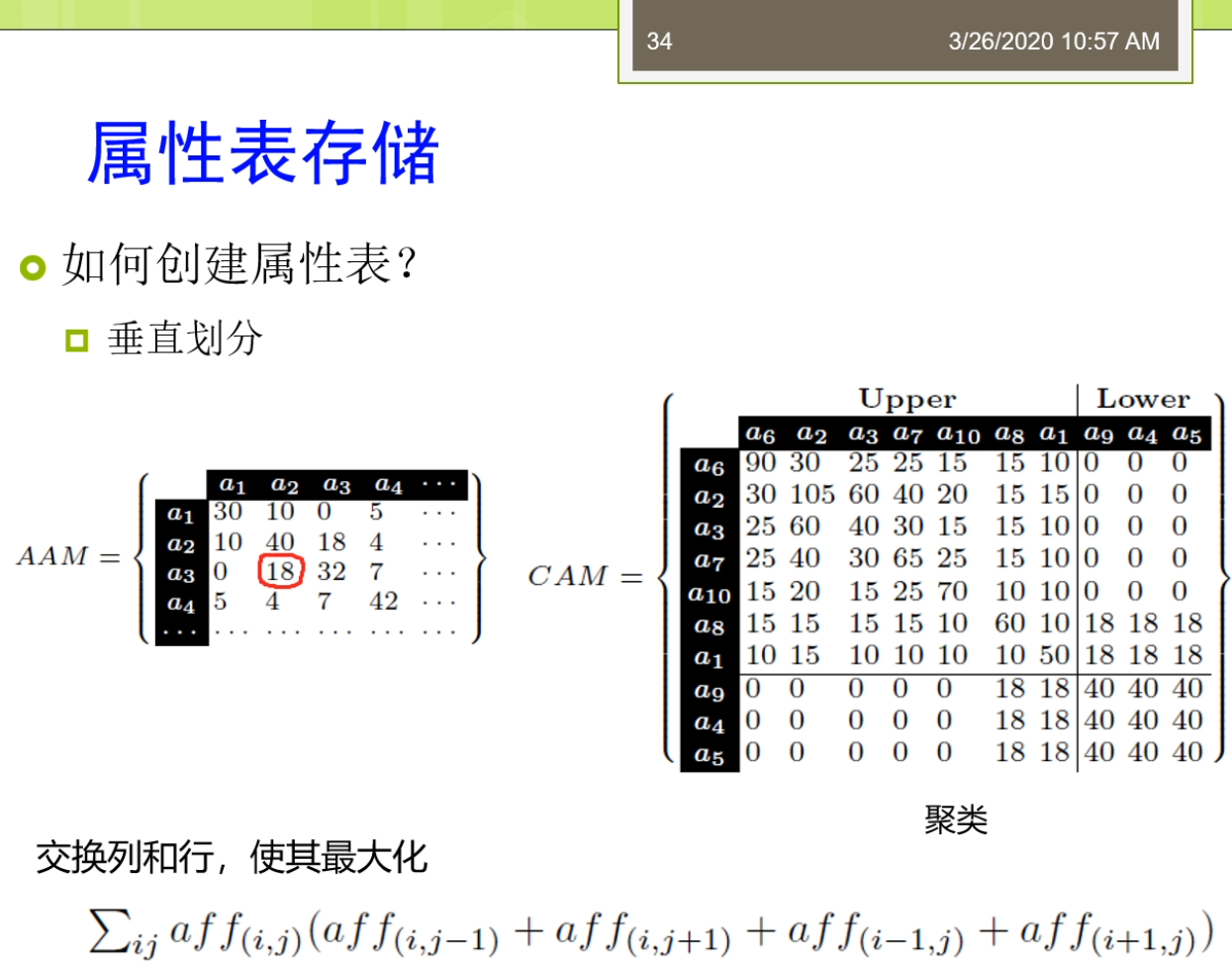

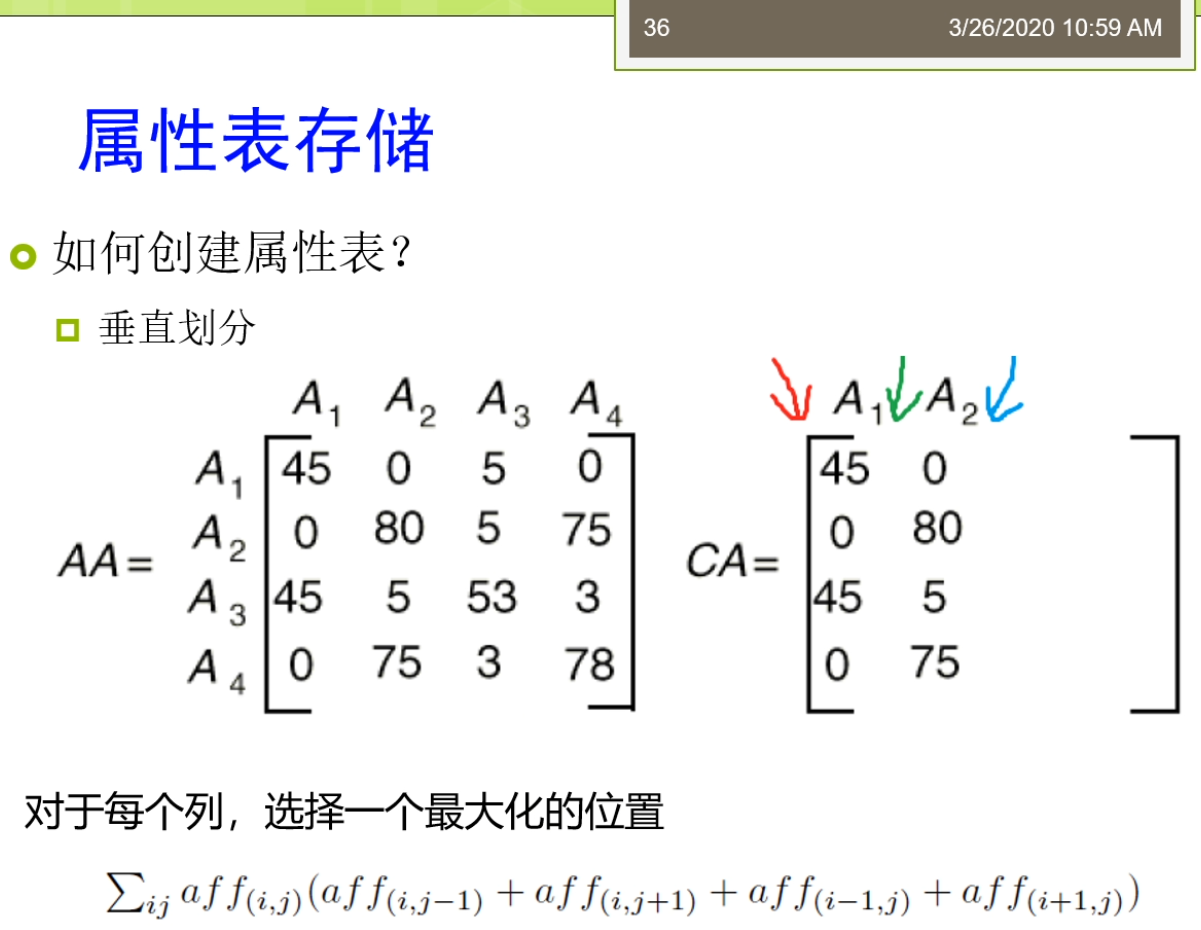
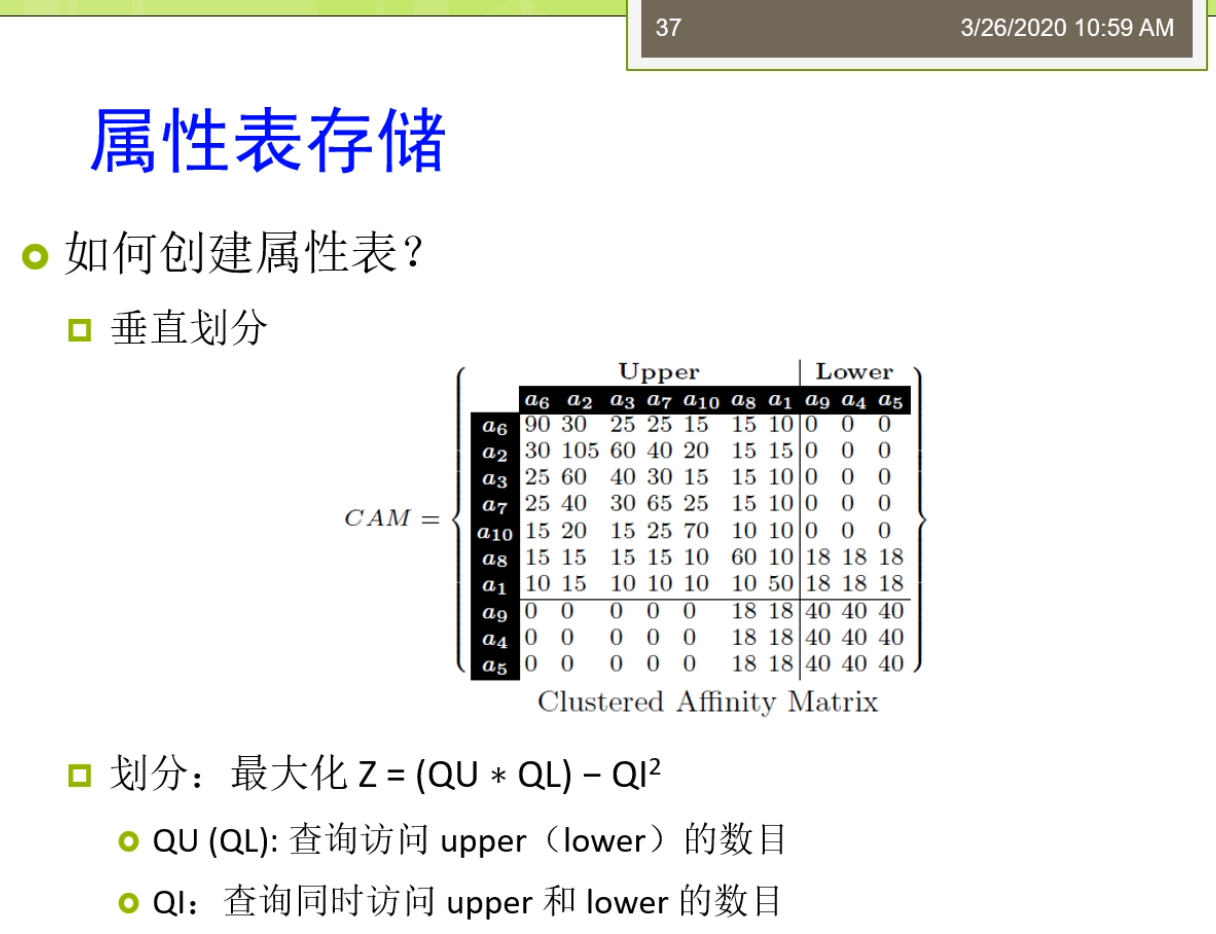

所以呢这时候我们刚才说的上面这张表,那么我们就会把他嘞变成下面这种形式。有做我们可以说0001代表的是这个contact me0002来代表的是这个contact personal title。那么这时候我们三人组的表现就可以缩写承担这样的形式给你010002000下。这样那你要知道他原始的在元祖了,那么你就要需要把这个0001,对导们说的这个字典里面去查一下。那么在这种关系型IBM存储的里面,只让我们严格的或者更好的分类一下。我可以分出来几种,一种来叫垂直的三元组表。一种呢被称为来教水平表水平表达式,一般来讲是个二元的方法。还有一种呢把它称为来调这个属性表属性表来一般来讲人们把它称为叫N元表。啊,我昨天看第一种这个团体。第一种存储来我们是一种垂直表,这个存储。随之表的存储里面每个啊df三元组啊,这都被直接存储在一个三列的这个表里面。这个三列的表里面来叫这个SPO。这是三面的表as you。那么每一列呢拾到存储的是主语,谓语或者宾语的形式。那么垂直表它的优点是当时来讲那不很简单,他呢很简单,很直观。因为这辆就三个列,每个炼奶正好对应的无所RDF三元组里面的一种,我就说不做图,你合并。但是他的缺点就是我们之前说的,那么他引入了太多的这样一个连接操作。比如说我们说我们再举个例子,我说我要查询这些外部配置是这些作者的。那么有一个呢是一个所谓这个是未来他一个title就要这个query RDF data。那么对于这样的一个操作时的看起来并不是很复杂的操作,我们可以写成的这样一个很长很大的这样一个。SQL查询的形式,大家在这里又看到我又有很多很多的这个连接操作需要。因为这个量的连接操作大家可以看到这个等号。都是我们做的这个连接操作。那么这时候大家会想了,那么我不是查询,慢慢那我可能这个有一个很简单的方法就是我创建一些,所以因为这个索引技术实际上是在我们的整个的这个关系数据库里面最常用的一种优化技术。有时候我们可以创建一种称为叫这个逼数所有的节目。那么我们可以用一个命令叫credit create index这个方法。那么这时候我可能说我可以去创建所有可能的,所以所有可能的,所以使得嘞我这个查询的连接我不敢不管怎么样去连接。那我的这个数据啊。这个因为我都建好了这个,所以那么我死所以的我的这个效率是很高的,我可以利用,所以这才但是这个方法适当仍然了会有些不好。那么比如说我们说一些不好的情况在于,比如说我现在要进行这个一些数据的更新或者重新插入删除的话,对吧?你刚才建立了那么多,所以知道你的效率就会第二个我们做还可以有些优化方法是这个查询计划生成。为大家可能知道在关系数据库里面,这个查询计划生成是一个很重要的内容,那么它基于了一些统计数据给出来最优的一种查询记录。那么面向这个啊颠覆了我们食堂也可以获得很多的统计数据。那么这些统计数据可以帮助我们判断,比如说我说这个威尔条件。他的一个执行的顺序到底先执行哪个比较好?一般来讲呢,我们都会先执行的高选择性的这个查询。高选择性的查询意味着我们要查的那个东西啊,它相对来讲这个比较特殊。所以呢他一开始的时候呢就可以使得我们的这个查询的候选集合。缩小的很快。怎么这样呢?未来的更多里面我们的这个查询啊再进行其他查询的时候,那么它的效率就会提高。那在这里我们有一个一般来讲通用的这样的一个一个一个一个规则,就是我们的主语和宾语。一般来讲呢会具有更高的这样一个选择性。也就做,那么他们的选择能力的更强,使用他们的水壶来执行的这个效率的会更高。另外呢,我们还有一种更加激进的方法。也就是说我们可以把我们的索引啊把他物化下来,形成新的表。这里物化和索引的整体来讲,那么他们的区别就在于。物化型呢是把索引真正的这个结果啊把他这个存储下来。比如说我说Expo我建立了在这个xp上建立了一个,所以另外呢也可以我把xp形成一张专门的表啊,这个表里面的数据存储的磁盘。所以这种雾化索引的方法。那么它比一般的这种B数索引啊等等的这种方法来并且还集锦。那么他大幅的会增加怎么说这个数据的力量?那么最坏的情况下它可能是速背了这样一个存储量增加。比如说我如果说我想查的是主语和宾语组合起来,那么我可能还要再查宾语和主语组合起来。等等,那么这些东西啊它都需要把它这个记录下来,存储在这个数据库上,然后变成一个单独的一个表去做。那么这个过程里面那显然它的存储量了会大幅的增强。I'm assuming我们讲的主要来是这个垂直表,那么我们还有一种方法称为了就要这个水平表。这个水平表啦,他被剑魔层一个这个水平表或者一个垂直分割的二元表这样的集合。在这个集合里面,每个属性啊他都对应到其中的一个表。比如说我们现在看到在这个里面,我说我们定义了好几个这个小的表。一个来叫这个publication type说一个具体的id,那么它的一个取值是一个survey paper。然后后来又说有一个表叫还是title,那么他的id了,第一个。Paper的id,那么他的title还是query RDF data等等。最这个跟我们刚才垂直表不太一样,随之表刚才说是一个这个单链的结构,主谓宾的结构。而水平表来实在是个两列的结构,那么这个两列怎么样去还原成一个三元组?谁让你只需要把这个表的名字把他带上。比如说对于第一条不就知道id,他的publication type是一个survey paper。这这个呢就是我们水平表的这个存储方法,它把中间的这个位置了放到了我们的表的作为表的这个名字放上去。那么最多水平表的方法它也有很多的这个优缺点,我可以看到第一个它的优点是他呢是直接的表的这个创建。那么这个三元组的位置它十档可以通过来,这个位置得去拍。比如说我想查所有的publication type这样的一个主语和宾语,那么我只需要来知道哦,我的publication太不是怎么了?那么我把这个位置指定了之后,那么我就可以了,把这样相应的结果不大查询出来,在这张表里面上面。但是它的缺点就是第一个它增加了插入开销。因为对于每一个插入,这个磁盘上可能就有多个位置需要被更新的。但是这里需要对每个属性啊需要来这个一次更新。因为他的一个缺点来是他增加了这个元祖重构的开场。他需要呢提供一个普通标准的关系数据库的接口,有做这个od,bc接近pc等等。那些关系数据库的接口了,迟到了,那么也需要的它增加这个开场。那么在这里那么还有一些这个可能的一些优化,比如说使得它的性能可以提升。比如说我们可以基于这个列存储的教育方式。易存储的方式里面,那么实际上他会把这边的Their看到这个主语我会进行了一个相映的这样一个排序的。如果把整体的这些数据排列的更好。那么具体怎么做呢?那么他可以了,比如说数据按列存储系每一行的单独存放。数据呢就是这个,所以只访问了这个产品,涉及到的这些例子可以来大幅的降低系统的这个输入输出开销。那么每一列的有一个线程来处理,实现了这个查询的并发处理性能高。以及的这个数据类型都是一致的,和数据特征比较相似,可以来相对来讲。比较高的这样一个压缩。所以呢整体来讲这个水平表还有一定这个优化的这个。但是这个水平表时当也有很多的这个争议。那么最早的呢是当时在2008年。这不在2008年的时候了。发表的这个vid b上的一个paper叫Colin stop support for RDF data management。然后呢后面用了一个做老子哦,swans are white,也就说不是所有的天鹅。都是这个白颜色。那么这个唻实际大概是这个我说这个国外的一种谚语不是说这个黑天鹅事件。那么大家来可能感兴趣的可以去查一查,对吧?意味着了你这个是一个。没有想到这个情况。那么这个工作他实际上是干了什么事嘞?他针对的是VR,DBA2007的一个工作,专门讲这个啊df数据存储的工作。那么他呢发现2007的那个工作实际上来并不他还是存在着一些这个缺陷。那么最后一种了,我们把它称为了就要这个属性表。如今表的存储是怎样?它是以主语作为特征,你就说对于相同的主语。多个id f模型啊被构建成一个能源表的这个列。那么应用方法来通常拥有的这个方法我是某些主语。和这个属性会被一起确保。所以这个属性表啊大家看到属性表刚才和我们的水平表啊他不太一样。属性表的这个表头表的名字是一个类别有的publication,这个是person。而不是我们刚才说的那样的一个属性。有的我们前面说的是一个publication type。最真实后这个属性表的存储里面,那么它的存储的这个形式发生的变化。他的缺点来是不是这个复杂度啊?相对来讲是比较高,去见这种属性表的复杂度是比较高,并且来他也高度地依赖于算法数据的情况。因为你如果确实你这个数据不好,你还不方便去接了我的这个属性。那么我们看怎么样去建这个属性表来怎么样创建这个表来,谁让咱是可以通过来这个用户指定的方式。比如钻,我知道这个主语和属性,我可以建立一个矩阵。雾化来这个连接视图。在这个关系管理部制度系统里面。我可以有个优化器开发了这个辅助的结构。我还可以来使用来这个叫愤怒多路的连接这样一个形式。那么这是一种另外一种呢还可以采用这个数据挖掘或者机器学习的方法。那么这里面IDF图或者idea日志就可以用起来看看这个也用户啊,他经常喜欢查的模式是什么?以此来来建立属性表。因为有主语属性贡献模式的发现或者查询模式的这个发型。以及的我们还可以应用模式设计或者缓存机制来提升那这里的这个姓。最积极的都是一些常见的这个方法可以去利用。具体来讲,我们可以看到,比如在属性表存储的时候,我很简单的有个方法。就是我们这个关系数据库啊,不是我们再出去挖掘里面经常会用的一个叫频繁项集的挖掘。那么它的原理就是说,如果我说某一个相机,那么他呢是平凡相机。那么他所有的子集也是品牌。也就是说如果假设在我们的下面的这个图里面,假设这个零,和依赖他都是这个平凡那么这个案子假设零一合起来是一个平凡的,那么意味着这个零和依赖单独的他们也是平板。那么用的时候呢你可以反过来用,如果说一个相机它不是平凡的,那么它所有的这个超级的也就不是品牌。那么具体来讲,我们现在看,假设我现在有一个属性表。我这个属性的集合了,把它称为来调这个pp二到pn以及呢到一个我们说的一个片段。集合f邋我叫feffx。我们可以构建了一个这样的一个查询。访问的一个一个一个表,这个表来记录了这个所有的查询访问。那么我们可以的用一些这个数据划分或者数据聚类的方法去分析。因为比如说我们在这个里面,我们可以对于hum这样的一个表去做一个聚类。我就知道这个哪一些属性啊,更应该经常在一块儿去存储,在这个属性表里一起存储在数据表里。那么更精细的我们在这里一般来讲我们填的是这个这个这个就是由访问开始呗。没有一或者这个这个零,那么我也可以的去统计属性共同访问的这个次数。那比如说这个a和这个AR他们共同访问的十次,对不对?我这里的我们都可以把它记录下来。那个记录之后那么时当我就可以了,进行这个划分,我的划分到目的地实际上是使得我们划分成这种也有点像对角形式的这样的一个矩阵,那么使得呢在这个upper这个部分里面这个数值啊尽量高,罗尔这个靓仔素质也可能尽量高。但是他们俩交叉的这个部分,那么他们的这个这个这个取值累加起来的相对来讲还比较少。那么意味着来我在这个里面我这个属性表里面这个这个整个的这个矩阵里面,我可以把它画成的两个角的那个属性表,第一个奶是这个upper第二个呢是这个lower,那么这样划分了它的性能,那可能相对来讲比较好。因为具体怎么样去划分,那么这时候来又有很多算法,比如说我可以使用bloom energy啊这个Agri them等等。这边呢我们就不仔细去介绍,那么大家来如果感兴趣后面呢我们也安排了一些这个论文呢给大家来阅读一下。在家可以后面感兴趣的去看看。那么包括在这儿我们说啊我们也可以,那不优化目标是变成对于每个列选择一个最大的这个位置。然后呢我最大化一个这样子一个海目标,这个目标里面包括了查询访问的数目。还需访问这个upper的树木或者lower的树木已经查询的同时访问upper和lower住的。那么这个公式大家很容易去看出来,变成了我要让upper这一块自身和这个lower这一块,他们的成绩单尽可能的要去大。而这个qi同时访问的最快,那么它的值要尽可能的小。你就说我不做嫁了个优化的目标。那么怎么样去创建这个属性表?我们刚才已经看到了有几类,包括了怎么样去分析IDF数据的模式。啊,呃,时间到了,我们先下课了,休息一会儿会儿,然后呢等一会儿我们再来接着讲。