java集合学习
此篇博客用sout代替System.out.pringln();
Java集合类是一种特别有用的工具类,可以用于存储数量不等的多个对象,并可以实现常用的数据结构,如栈、队列等。除此之外,Java集合还可用于保存具有映射关系的关联数组。Java集合大致可分为Set、List和Map三种体系,其中Set代表无序、不可重复的集合;List代表有序、重复的集合;而Map则代表具有映射关系的集合。从Java 5以后,Java又增加了Queue体系集合,代表一种队列集合实现。
概述
集合类和数组不一样,数组元素既可以是基本类型的值,也可以是对象(实际上保存的是对象的引用变量);而集合里只能保存对象(实际上只是保存对象的引用变量,但通常习惯上认为集合里保存的是对象)。
Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口,这两个接口又包含了一些子接口或实现类。(PS:图片来源于冰湖一角的博客)
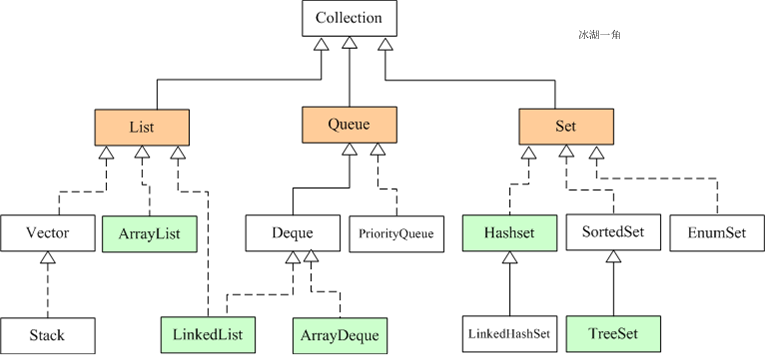
Collection和iterator接口
Collection接口是List、Set和Queue接口的父接口,该接口里定义的方法既可用于操作Set集合,也可用于操作List和Queue集合。Collection接口里定义了如下操作集合元素的方法。以下为快速参考,详见API文档。
boolean add(Object o)//该方法用于向集合里添加一个元素。如果集合对象被添加操作改变了,则返回true。
boolean addAll(Collection c)//该方法把集合c里的所有元素添加到指定集合里。如果集合对象被添加操作改变了,则返回true。
void clear()//清除集合里的所有元素,将集合长度变为0。
boolean contains(Object o)//返回集合里是否包含指定元素。
boolean containsAll(Collection c)//返回集合里是否包含集合c里的所有元素。
boolean isEmpty()//返回集合是否为空。当集合长度为0时返回true,否则返回false。
Iterator iterator()//返回一个Iterator对象,用于遍历集合里的元素。
boolean remove(Object o)//删除集合中的指定元素o,当集合中包含了一个或多个元素o时,这些元素将被删除,该方法将返回true。
boolean removeAll(Collection c)//从集合中删除集合c里包含的所有元素(相当于用调用该方法的集合减集合c),如果删除了一个或一个以上的元素,则该方法返回true。
boolean retainAll(Collection c)//从集合中删除集合c里不包含的元素(相当于把调用该方法的集合变成该集合和集合c的交集),如果该操作改变了调用该方法的集合,则该方法返回true。
int size()//该方法返回集合里元素的个数。
Object[] toArray()//该方法把集合转换成一个数组,所有集合元素变成对应的数组元素。
在普通情况下,当我们把一个对象“丢进”集合中后,集合会忘记这个对象的类型——也就是说,系统把所有的集合元素都当成Object类的实例进行处理。从JDK 1.5以后,这种状态得到了改进:可以使用泛型来限制集合里元素的类型,并让集合记住所有集合元素的类型。
使用Iterator接口遍历元素
Iterator接口隐藏了各种Collection实现类的底层细节,向应用程序提供了遍历Collection集合元素的统一编程接口。Iterator接口里定义了如下三个方法。
boolean hasNext()//如果被迭代的集合元素还没有被遍历,则返回true。
Object next()//返回集合里的下一个元素。
void remove()//删除集合里上一次next方法返回的元素。
eg:
public static void main(){
Collection books=new HashSet();
books.add("aaaaa");
books.add("bbbbb");
books.add("ccccc");
Iterator it =books.iterator();
while(it.hasNext()){
String book =(String)it.next();//it.next()返回Object需要强转
System.out.println(book);
if(book.equals("aaaaa")){
it.remove();//删除上一次next方法返回的元素
//下面代码引发异常 iterator迭代过程中不可修改集合元素
//books.remoce(book);
}
book="ceshi";//对book赋值
}
System.out.println(books);
}
当使用Iterator对集合元素进行迭代时,Iterator并不是把集合元素本身传给了迭代变量,而是把集合元素的值传给了迭代变量,所以修改迭代变量的值对集合元素本身没有任何影响。
Iterator迭代器采用的是快速失败(fail-fast)机制,一旦在迭代过程中检测到该集合已经被修改(通常是程序中的其他线程修改),程序立即引发ConcurrentModificationException异常,而不是显示修改后的结果,这样可以避免共享资源而引发的潜在问题。
Iterator仅用于遍历集合,Iterator本身并不提供盛装对象的能力。如果需要创建Iterator对象,则必须有一个被迭代的集合。没有集合的Iterator仿佛无本之木,没有存在的价值。
使用foreach遍历元素
与使用Iterator接口迭代访问集合元素类似的是,foreach循环中的迭代变量也不是集合元素本身,系统只是依次把集合元素的值赋给迭代变量,因此在foreach循环中修改迭代变量的值也没有任何实际意义。
同样,当使用foreach循环迭代访问集合元素时,该集合也不能被改变,否则将引发ConcurrentModificationException异常。
Set集合
Set集合与Collection基本上完全一样,它没有提供任何额外的方法。实际上Set就是Collection,只是行为略有不同(Set不允许包含重复元素)。
Set集合不允许包含相同的元素,如果试图把两个相同的元素加入同一个Set集合中,则添加操作失败,add方法返回false,且新元素不会被加入。
Set判断两个对象相同不是使用==运算符,而是根据equals方法。也就是说,只要两个对象用equals方法比较返回true,Set就不会接受这两个对象;反之,只要两个对象用equals方法比较返回false,Set就会接受这两个对象(甚至这两个对象是同一个对象,Set也可把它们当成两个对象处理,在后面程序中可以看到这种极端的情况)。
HashSet类
HashSet是Set接口的典型实现,大多数时候使用Set集合时就是使用这个实现类。HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。
特点:
- 不能保证元素的排列顺序,顺序有可能发生变化
- HashSet不是同步的,如果多个线程同时访问一个HashSet,假设有两个或者两个以上线程同时修改了HashSet集合时,则必须通过代码来保证其同步。
- 集合元素值可以是null。
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该HashCode值决定该对象在HashSet中的存储位置。如果有两个元素通过equals()方法比较返回true,但它们的hashCode()方法返回值不相等,HashSet将会把它们存储在不同的位置,依然可以添加成功。
简单地说,HashSet集合判断两个元素相等的标准是两个对象通过equals()方法比较相等,并且两个对象的hashCode()方法返回值也相等。
下面程序分别提供了三个类A、B和C,它们分别重写了equals()、hashCode()两个方法的一个或全部
class A{//类A的equals方法总是返回true;没有重写hashCode方法
public boolean equals(Object obj){return true;}
}
class B{//类B的hashCode方法总是返回1;没有重写equals方法
public int hashCode(){return 1;}
}
class C{//类C的hashCode方法总是返回2;且重写equals方法
public int hashCode(){return 2;}
public boolean equals(Object obj){return true;}
}
//main
HashSet books=new HashSet();
books.add(new A());
books.add(new A());
books.add(new B());
books.add(new B());
books.add(new C());
books.add(new C());
System.out.println(books);
运行结果:
[b@1,B@1,C@2,A@5438cd,A@9931f5]‘
从上面程序可以看出,即使两个A对象通过equals()方法比较返回true,但HashSet依然把它们当成两个对象;即使两个B对象的hashCode()返回相同值(都是1),但HashSet依然把它们当成两个对象。这里有一个问题需要注意:当把一个对象放入HashSet中时,如果需要重写该对象对应类的equals()方法,则也应该重写其hashCode()方法。其规则是:如果两个对象通过equals()方法比较返回true,这两个对象的hashCode值也应该相同。
如果该对象哈希码与集合已存在对象的哈希码不一致,则该对象没有与其他对象重复,添加到集合中.如果存在于该对象相同的哈希码,那么通过equals方法判断两个哈希码相同的对象是否为同一对象(判断的标准是:属性是否相同)
注意
当把一个对象放入HashSet中时,如果需要重写该对象对应类的equals()方法,则也应该重写其hashCode()方法。其规则是:如果两个对象通过equals()方法比较返回true,这两个对象的hashCode值也应该相同。
如果两个对象通过equals()方法比较返回true,但这两个对象的hashCode()方法返回不同的hashCode值时,这将导致HashSet会把这两个对象保存在Hash表的不同位置,从而使两个对象都可以添加成功,这就与Set集合的规则有些出入了。
如果两个对象的hashCode()方法返回的hashCode值相同,但它们通过equals()方法比较返回false时将更麻烦:因为两个对象的hashCode值相同,HashSet将试图把它们保存在同一个位置,但又不行(否则将只剩下一个对象),所以实际上会在这个位置用链式结构来保存多个对象;而HashSet访问集合元素时也是根据元素的hashCode值来快速定位的,如果HashSet中两个以上的元素具有相同的hashCode值,将会导致性能下降。
所以如果需要把某个类的对象保存到HashSet集合中,重写这个类的equals()方法和hashCode()方法时,应该尽量保证两个对象通过equals()方法比较返回true时,它们的hashCode()方法返回值也相等。
HashSet中每个能存储元素的“槽位”(slot)通常称为“桶”(bucket),如果有多个元素的hashCode值相同,但它们通过equals()方法比较返回false,就需要在一个“桶”里放多个元素,这样会导致性能下降。
重写hashCode()方法的基本规则
- 在程序运行过程中,同一个对象多次调用hashCode()方法应该返回相同的值。
- 当两个对象通过equals()方法比较返回true时,这两个对象的hashCode()方法应返回相等的值。
- 对象中用作equals()方法比较标准的Field,都应该用来计算hashCode值。
重写hashCode()的一般规则
1.首先计算一个int类型的哈希值计算规则:
| Boolean | hashCode=(f?0:1) |
|---|---|
| 整数类型(byte short int char) | hashCode=(int)f |
| long | hashCode=(int)(f^(f>>>32)) |
| float | hashCode=Float.floatToIntBits(f) |
| double | long l = Double.doubleToLongBits(f); hashCode=(int)(l^(l>>>32)) |
| 普通引用类型 | hashCode=f.hashCode() |
2.计算出来的多个hashCode值组合计算出一个hashCode值返回
return f1.hashCode()+(int)f2;//可能相加产生偶然相等
//为了避免直接相加产生偶然相等,可以通过为各个Field乘以任意一个质数后再相加。
return f1.hashCode()*17+(int)f2*13;
注意
当向HashSet中添加可变对象时,必须十分小心。如果修改HashSet集合中的对象,有可能导致该对象与集合中的其他对象相等,从而导致HashSet无法准确访问该对象。
比如改变了Set集合中第一个对象的count实例变量的值,这将导致该该对象与集合中的其他对象相同。这时的HashSet集合会变得十分混乱。
底层实现
private transient HashMap<E, Object> map;
public HashSet() {
this.map = new HashMap();
}
由以上源码可见HashSet底层是由HashMap实现的
LinkedHashSet类
HashSet还有一个子类LinkedHashSet,LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。
也就是说,当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时将有很好的性能,因为它以链表来维护内部顺序.
LinkedHashSet books =new LinkedHashSet();
books.add("aaa");
books.add("bbb");
sout(books);
books.remove("aaa");
books.add("aaa");
sout(books);
运行结果如下
["aaa","bbb"]
["bbb","aaa"]
TreeSet
TreeSet是SortedSet接口的实现类,正如SortedSet名字所暗示的,TreeSet可以确保集合元素处于排序状态。与HashSet集合相比,TreeSet还提供了如下几个额外的方法。
Comparator comparator():如果TreeSet采用了定制排序,则该方法返回定制排序所使用的Comparator;如果TreeSet采用了自然排序,则返回null。
Object first():返回集合中的第一个元素。
Object last():返回集合中的最后一个元素。
Object lower(Object e):返回集合中位于指定元素之前的元素(即小于指定元素的最大元素,参考元素不需要是TreeSet集合里的元素)。
Object higher (Object e):返回集合中位于指定元素之后的元素(即大于指定元素的最小元素,参考元素不需要是TreeSet集合里的元素)。
SortedSet subSet(fromElement, toElement):返回此Set的子集合,范围从fromElement(包含)到toElement(不包含)。
SortedSet headSet(toElement):返回此Set的子集,由小于toElement的元素组成。
SortedSet tailSet(fromElement):返回此Set的子集,由大于或等于fromElement的元素组成。
表面上看起来这些方法很复杂,其实它们很简单:因为TreeSet中的元素是有序的,所以增加了访问第一个、前一个、后一个、最后一个元素的方法,并提供了三个从TreeSet中截取子TreeSet的方法。
TreeSet nums=new TreeSet();
num.add(5);num.add(2);num.add(10);num.add(-9);
System.out.println(nums);
System.out.println(nums.first());
System.out.println(nums.last());
System.out.println(nums.headSet(4));
System.out.println(nums.tailSet(5));
System.out.println(nums.subSet(-3,4));
结果
[-9,2,5,10]
-9
10
[-9,2]
[5,10]
[2]
根据上面程序的运行结果即可看出,TreeSet并不是根据元素的插入顺序进行排序的,而是根据元素实际值的大小来进行排序的。
与HashSet集合采用hash算法来决定元素的存储位置不同,TreeSet采用红黑树的数据结构来存储集合元素。那么TreeSet进行排序的规则是怎样的呢?TreeSet支持两种排序方法:自然排序和定制排序。在默认情况下,TreeSet采用自然排序。
自然排序
TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素之间的大小关系,然后将集合元素按升序排列,这种方式就是自然排序。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类的对象就可以比较大小。当一个对象调用该方法与另一个对象进行比较时,例如obj1.compareTo(obj2),如果该方法返回0,则表明这两个对象相等;如果该方法返回一个正整数,则表明obj1大于obj2;如果该方法返回一个负整数,则表明obj1小于obj2。
如果试图把一个对象添加到TreeSet时,则该对象的类必须实现Comparable接口,否则程序将会抛出异常。如下程序示范了这个错误。
class A{}
class Test{
main(){
TreeSet ts=new TreeSet();
ts.add(new A());ts.add(new A());
}
}
上面程序试图向TreeSet集合中添加两个A对象,添加第一个对象时,TreeSet里没有任何元素,所以不会出现任何问题;当添加第二个A对象时,TreeSet就会调用该对象的compareTo(Object obj)方法与集合中的其他元素进行比较——如果其对应的类没有实现Comparable接口,则会引发ClassCastException异常
而且向TreeSet中添加的应该是同一个类的对象,否则也会引发ClassCastException异常。
对于TreeSet集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过compareTo(Object obj)方法比较是否返回0——如果通过compareTo(Object obj)方法比较返回0,TreeSet则会认为它们相等;否则就认为它们不相等。
注意
当需要把一个对象放入TreeSet中,重写该对象对应类的equals()方法时,应保证该方法与compareTo(Object obj)方法有一致的结果,其规则是:如果两个对象通过equals()方法比较返回true时,这两个对象通过compareTo(Object obj)方法比较应返回0。
如果两个对象通过compareTo(Object obj)方法比较返回0时,但它们通过equals()方法比较返回false将很麻烦,因为两个对象通过compareTo(Object obj)方法比较相等,TreeSet不会让第二个元素添加进去,这就会与Set集合的规则产生冲突。
与HashSet类似的是,如果TreeSet中包含了可变对象,当可变对象的Field被修改时,TreeSet在处理这些对象时将非常复杂,而且容易出错。为了让程序更加健壮,推荐HashSet和TreeSet集合中只放入不可变对象。
定制排序
TreeSet的自然排序是根据集合元素的大小,TreeSet将它们以升序排列。如果需要实现定制排序,例如以降序排列,则可以通过Comparator接口的帮助。该接口里包含一个int compare(T o1, T o2)方法,该方法用于比较o1和o2的大小:如果该方法返回正整数,则表明o1大于o2;如果该方法返回0,则表明o1等于o2;如果该方法返回负整数,则表明o1小于o2。
class M{
int age;
public M(int age){
this.age=age;
}
public String toString(){.....}
}
class Test{
public static void main(){
TreeSet ts =new TreeSet(new Comparator(){
//根据对象age决定大小
public int compare(Object o1,Object o2){
M m1=(M)o1; M m2=(M)o2;
return m1.age>m2.age?-1:m1.age<m2.age?1:0;
}
});
ts.add(new M(5)); ts.add(new M(-9)); ts.add(new M(3));
sout(ts);
}
}
结果:
[M对象(age:5),M对象(age:3),M对象(age:-9)]
EnumSet类
EnumSet是一个专为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式或隐式地指定。EnumSet的集合元素也是有序的,EnumSet以枚举值在Enum类内的定义顺序来决定集合元素的顺序。
EnumSet集合不允许加入null元素,如果试图插入null元素,EnumSet将抛出NullPointerException异常。如果只是想判断EnumSet是否包含null元素或试图删除null元素都不会抛出异常,只是删除操作将返回false,因为没有任何null元素被删除。
各Set的性能分析
HashSet和TreeSet是Set的两个典型实现,到底如何选择HashSet和TreeSet呢?HashSet的性能总是比TreeSet好(特别是最常用的添加、查询元素等操作),因为TreeSet需要额外的红黑树算法来维护集合元素的次序。只有当需要一个保持排序的Set时,才应该使用TreeSet,否则都应该使用HashSet。
HashSet还有一个子类:LinkedHashSet,对于普通的插入、删除操作,LinkedHashSet比HashSet要略微慢一点,这是由维护链表所带来的额外开销造成的;不过,因为有了链表,遍历LinkedHashSet会更快。
List集合
List接口和ListIterator接口
List作为Collection接口的子接口,当然可以使用Collection接口里的全部方法。而且由于List是有序集合,因此List集合里增加了一些根据索引来操作集合元素的方法。
void add(int index, Object element):将元素element插入到List集合的index处。
boolean addAll(int index, Collection c):将集合c所包含的所有元素都插入到List集合的index处。
Object get(int index):返回集合index索引处的元素。
int indexOf(Object o):返回对象o在List集合中第一次出现的位置索引。
int lastIndexOf(Object o):返回对象o在List集合中最后一次出现的位置索引。
Object remove(int index):删除并返回index索引处的元素。
Object set(int index, Object element):将index索引处的元素替换成element对象,返回新元素。
List subList(int fromIndex, int toIndex):返回从索引fromIndex(包含)到索引toIndex(不包含)处所有集合元素组成的子集合。
所有的List实现类都可以调用这些方法来操作集合元素。与Set集合相比,List增加了根据索引来插入、替换和删除集合元素的方法。
List books =new ArrayList();
books.add(new String("aaa"));books.add(new String("bbb"));book.add(new String("ccc"));
System.out.println(books);
//在第二个位置插入
book,add(1,new String("ddd"));
for(int i=0;i<books.size();i++){
System.out.println(books.get(i));
}
books.remove(2);
System.out.println(books);
//输出1表明在第二个位置
System.out.println(books.indexOf("ddd"));//1
books.set(1,new String("bbb"));
System.out.println(books);
System.out.println(books.subList(1,2));
结果:
[aaa,bbb,ccc]
aaa
ddd
bbb
ccc
[aaa,ddd,ccc]
1
[aaa,bbb,ccc]
[bbb]
从上面运行结果清楚地看出List集合的用法。注意1行代码处,程序试图返回新字符串对象在List集合中的位置,实际上List集合中并未包含该字符串对象。因为List集合添加字符串对象时,添加的是通过new关键字创建的新字符串对象,1行代码处也是通过new关键字创建的新字符串对象,两个字符串显然不是同一个对象,但List的indexOf方法依然可以返回1。List判断两个对象相等的标准是什么呢?List判断两个对象相等只要通过equals()方法比较返回true即可。比如:
class A{ public boolean equals(Object obj){return true;}}
List books =new ArrayList();
books.add(new String("aaa"));books.add(new String("bbb"));book.add(new String("ccc"));
books.remove(new A());//1
执行①行代码时,程序试图删除一个A对象,List将会调用该A对象的equals()方法依次与集合元素进行比较,如果该equals()方法以某个集合元素作为参数时返回true,List将会删除该元素——A类重写了equals()方法,该方法总是返回true。所以我们看到每次从List集合中删除A对象,总是删除List集合中的第一个元素。
遍历元素
与Set只提供了一个iterator()方法不同,List还额外提供了一个listIterator()方法,该方法返回一个ListIterator对象,ListIterator接口继承了Iterator接口,提供了专门操作List的方法。ListIterator接口在Iterator接口基础上增加了如下方法。
boolean hasPrevious():返回该迭代器关联的集合是否还有上一个元素。
Object previous():返回该迭代器的上一个元素。
void add():在指定位置插入一个元素。
ListIterator增加了向前迭代的功能(Iterator只能向后迭代),而且ListIterator还可通过add方法向List集合中添加元素(Iterator只能删除元素)。
List books =new ArrayList();
books.add(new String("aaa"));books.add(new String("bbb"));
ListIterator lit=books.listIterator();
while(lit.hasNext()){
sout(lit.next());
lit.add("xxxxxxxxxx");
}
sout("反向迭代-------------");
while(lit.hasPrevious()){
sout(lit.previous());
}
使用ListIterator迭代List集合时,开始也需要采用正向迭代,即先使用next()方法进行迭代,在迭代过程中可以使用add()方法向上一次迭代元素的后面添加一个新元素。结果:
aaa
bbb
反向迭代-------------
xxxxxxxxxx
bbb
xxxxxxxxxx
aaa
ArrayList和Vector实现类
ArrayList和Vector类都是基于数组实现的List类,所以ArrayList和Vector类封装了一个动态的、允许再分配的Object[]数组。从源码(Java8)看,默认大小是10.
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = new Object[0];
ArrayList或Vector对象使用initialCapacity参数来设置该数组的长度,当向ArrayList或Vector中添加元素超出了该数组的长度时,它们的initialCapacity会自动增加。ArrayList和Vector还提供了如下两个方法来重新分配Object[]数组。
void ensureCapacity(int minCapacity):将ArrayList或Vector集合的Object[]数组长度增加minCapacity。
void trimToSize():调整ArrayList或Vector集合的Object[]数组长度为当前元素的个数。程序可调用该方法来减少ArrayList或Vector集合对象占用的存储空间。
ArrayList和Vector在用法上几乎完全相同,但由于Vector是一个古老的集合(从JDK 1.0就有了),那时候Java还没有提供系统的集合框架,所以Vector里提供了一些方法名很长的方法,例如addElement(Object obj),实际上这个方法与add (Object obj)没有任何区别
ArrayList和Vector的显著区别是:ArrayList是线程不安全的,当多个线程访问同一个ArrayList集合时,如果有超过一个线程修改了ArrayList集合,则程序必须手动保证该集合的同步性;但Vector集合则是线程安全的,无须程序保证该集合的同步性。因为Vector是线程安全的,所以Vector的性能比ArrayList的性能要低。
public synchronized E firstElement() {
if (this.elementCount == 0) {
throw new NoSuchElementException();
} else {
return this.elementData(0);
}
}
由上面源码可见Vector是由synchronized实现同步。
实际上,即使需要保证List集合线程安全,也同样不推荐使用Vector实现类。有一个Collections工具类,它可以将一个ArrayList变成线程安全的。
LinkedList实现类
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, Serializable
以上为LinkedList的源码(Java8)可见该类实现了List和Deque接口,所以详见下面Deque接口。
固定长度的List
操作数组的工具类:Arrays,该工具类里提供了asList(Object... a)方法,该方法可以把一个数组或指定个数的对象转换成一个List集合,这个List集合既不是ArrayList实现类的实例,也不是Vector实现类的实例,而是Arrays的内部类ArrayList的实例。
@SafeVarargs
public static <T> List<T> asList(T... var0) {
return new Arrays.ArrayList(var0);//1
}
上面1位置的这个类是在Arrays类中的内部类见下面
private static class ArrayList<E> extends AbstractList<E> implements RandomAccess, Serializable {
private static final long serialVersionUID = -2764017481108945198L;
private final E[] a;
ArrayList(E[] var1) {
this.a = (Object[])Objects.requireNonNull(var1);
}
public int size() {
return this.a.length;
}
//。。。。。。
}
Arrays.ArrayList是一个固定长度的List集合,程序只能遍历访问该集合里的元素,不可增加、删除该集合里的元素。试图增加删除元素都会引发UnsupportedOperationException异常。
Queue
Queue用于模拟队列这种数据结构,队列的头部保存存放时间最长的元素,队列的尾部保存存放时间最短的元素。queue接口中定义了如下几个方法:
void add(Object e):将指定元素加入到队列的尾部
Object element():获取队列头部的元素,但是不删除元素
boolean offer(Object e):将指定元素加入到队列的尾部。当时拥有容量限制的队列时,此方法只会返回false,而add会抛出IllegalStateException异常。
Object peek():获取队列头部的元素,但是不删除元素,如果队列为空,则返回null
Object poll():获取队列头部的元素,并删除元素。如果队列为空,则返回null
Object remove():获取队列头部的元素,并删除元素。
PriorityQueue实现类
PriorityQueue是一个比较标准的队列实现类。之所以说它是比较标准的队列实现,而不是绝对标准的队列实现,是因为PriorityQueue保存队列元素的顺序并不是按加入队列的顺序,而是按队列元素的大小进行重新排序。因此当调用peek()方法或者poll()方法取出队列中的元素时,并不是取出最先进入队列的元素,而是取出队列中最小的元素。从这个意义上来看,PriorityQueue已经违反了队列的最基本规则:先进先出(FIFO)。
public static void main(String []args){
Queue queue = new PriorityQueue();
queue.add(30);
queue.offer(15);
queue.add(6);
queue.offer(52);
queue.add(-9);
System.out.println(queue);
}
运行结果:
[-9, 6, 15, 52, 30]
PriorityQueue不允许插入null元素,它还需要对队列元素进行排序,PriorityQueue的元素有两种排序方式。自然排序、定制排序。PriorityQueue队列对元素的要求与TreeSet对元素的要求基本一致。
Deque接口
Deque接口是Queue接口的子接口,它代表一个双端队列,Deque接口里定义了一些双端队列的方法,这些方法允许从两端来操作队列的元素。
void addFirst(Object e):将指定元素插入该双端队列的开头。
void addLast(Object e):将指定元素插入该双端队列的末尾。
Iterator descendingIterator():返回该双端队列对应的迭代器,该迭代器将以逆向顺序来迭代队列中的元素。
Object getFirst():获取但不删除双端队列的第一个元素。
Object getLast():获取但不删除双端队列的最后一个元素。
boolean offerFirst(Object e):将指定元素插入该双端队列的开头。
boolean offerLast(Object e):将指定元素插入该双端队列的末尾。
Object peekFirst():获取但不删除该双端队列的第一个元素;如果此双端队列为空,则返回null。
Object peekLast():获取但不删除该双端队列的最后一个元素;如果此双端队列为空,则返回null。
Object pollFirst():获取并删除该双端队列的第一个元素;如果此双端队列为空,则返回null。
Object pollLast():获取并删除该双端队列的最后一个元素;如果此双端队列为空,则返回null。
Object pop()(栈方法):pop出该双端队列所表示的栈的栈顶元素。相当于removeFirst()。
void push(Object e)(栈方法):将一个元素push进该双端队列所表示的栈的栈顶。相当于addFirst(e)。
Object removeFirst():获取并删除该双端队列的第一个元素。
Object removeFirstOccurrence(Object o):删除该双端队列的第一次出现的元素o。
removeLast():获取并删除该双端队列的最后一个元素。
removeLastOccurrence(Object o):删除该双端队列的最后一次出现的元素o。
从上面方法中可以看出,Deque不仅可以当成双端队列使用,而且可以被当成栈来使用,因为该类里还包含了pop(出栈)、push(入栈)两个方法。
Deque方法与Queue方法对照
| Queue的方法 | Deque的方法 |
|---|---|
| add(e)/offer(e) | addLast(e)/offerLast(e) |
| remove()/pool() | removeFirst()/poolFirst() |
| element()/peek() | getFirst()/peekFirst() |
Deque方法与Stack方法对照
| Stack的方法 | Deque的方法 |
|---|---|
| push(e) | addFirst(e)/offerFirst(e) |
| pop() | removeFirst()/poolFirst() |
| peek() | getFirst()/peekFirst() |
Deque接口与ArrayDeque实现类
Deque接口提供了一个典型的实现类:ArrayDeque,从该名称就可以看出,它是一个基于数组实现的双端队列,创建Deque时同样可指定一个numElements参数,该参数用于指定Object[]数组的长度;如果不指定numElements参数,Deque底层数组的长度为16。以下为ArrayDeque的构造函数源码(Java8)
public ArrayDeque() {
this.elements = new Object[16];
}
以下示例将ArrayDeque用作栈来使用:
public static void main(String[] args) {
ArrayDeque stack = new ArrayDeque();
stack.push("aaa");
stack.push("bbb");
stack.push("ccc");
//输出 ccc,bbb,aaa
System.out.println(stack);
System.out.println(stack.peek());
System.out.println(stack);
System.out.println(stack.pop());
System.out.println(stack);
}
使用ArrayDeque的性能会更加出色,因此现在的程序中需要使用“栈”这种数据结构时,推荐使用ArrayDeque或LinkedList,而不是Stack。
Deque接口与LinkedList实现类
LinkedList类是List接口的实现类——这意味着它是一个List集合,可以根据索引来随机访问集合中的元素。除此之外,LinkedList还实现了Deque接口,因此它可以被当成双端队列来使用,自然也可以被当成“栈”来使用了。
简单示例:
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.offer("aaa");//加入队列尾部
linkedList.push("bbb");//加入栈的顶部
linkedList.offerFirst("ccc");//加入到队列的头部(相当于栈的顶部)
for (int i = 0; i <linkedList.size() ; i++) {
System.out.println(linkedList.get(i));
}
System.out.println(linkedList.peekFirst());
System.out.println(linkedList.peekLast());
System.out.println(linkedList.pop());
System.out.println(linkedList);
System.out.println(linkedList.pollLast());
System.out.println(linkedList);
}
运行结果:
ccc
bbb
aaa
ccc
aaa
ccc
[bbb, aaa]
aaa
[bbb]
LinkedList与ArrayList、ArrayDeque的实现机制完全不同,ArrayList、ArrayDeque内部以数组的形式来保存集合中的元素,因此随机访问集合元素时有较好的性能;而LinkedList内部以链表的形式来保存集合中的元素,因此随机访问集合元素时性能较差,但在插入、删除元素时性能非常出色(只需改变指针所指的地址即可)。需要指出的是,虽然Vector也是以数组的形式来存储集合元素的,但因为它实现了线程同步功能,所以各方面性能都有所下降。
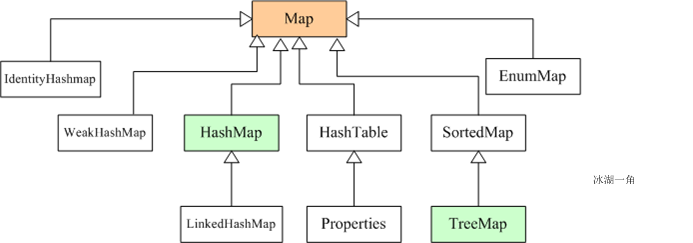
Map
Map用于保存具有映射关系的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value,key和value都可以是任何引用类型的数据。Map的key不允许重复,即同一个Map对象的任何两个key通过equals方法比较总是返回false。
Map与Set关系
Set与Map之间的关系非常密切。虽然Map中放的元素是key-value对,Set集合中放的元素是单个对象,但如果我们把key-value对中的value当成key的附庸:key在哪里,value就跟在哪里。这样就可以像对待Set一样来对待Map了。事实上,Map提供了一个Entry内部类来封装key-value对,而计算Entry存储时则只考虑Entry封装的key。从Java源码来看, Java是先实现了Map,然后通过包装一个所有value都为null的Map就实现了Set集合。
如果把Map里的所有value放在一起来看,它们又非常类似于一个List:元素与元素之间可以重复,每个元素可以根据索引来查找,只是Map中的索引不再使用整数值,而是以另一个对象作为索引。如果需要从List集合中取出元素,则需要提供该元素的数字索引;如果需要从Map中取出元素,则需要提供该元素的key索引。因此,Map有时也被称为字典,或关联数组。Map接口中定义了如下常用的方法。
void clear():删除该Map对象中的所有key-value对。
boolean containsKey(Object key):查询Map中是否包含指定的key,如果包含则返回true。
boolean containsValue(Object value):查询Map中是否包含一个或多个value,如果包含则返回true。
Set entrySet():返回Map中包含的key-value对所组成的Set集合,每个集合元素都是Map.Entry (Entry是Map的内部类)对象。
Object get(Object key):返回指定key所对应的value;如果此Map中不包含该key,则返回null。
boolean isEmpty():查询该Map是否为空(即不包含任何key-value对),如果为空则返回true。
Set keySet():返回该Map中所有key组成的Set集合。
Object put(Object key, Object value):添加一个key-value对,如果当前Map中已有一个与该key相等的key-value对,则新的key-value对会覆盖原来的key-value对。
void putAll(Map m):将指定Map中的key-value对复制到本Map中。
Object remove(Object key):删除指定key所对应的key-value对,返回被删除key所关联的value,如果该key不存在,则返回null。
int size():返回该Map里的key-value对的个数。
Collection values():返回该Map里所有value组成的Collection。
Map中包括一个内部类Entry,该类封装了一个key-value对。Entry包含如下三个方法。
Object getKey():返回该Entry里包含的key值。
Object getValue():返回该Entry里包含的value值。
Object setValue(V value):设置该Entry里包含的value值,并返回新设置的value值。
所有的Map实现类都重写了toString()方法,调用Map对象的toString()方法总是返回如下格式的字符串:{key1=value1,key2=value2...}。
HashMap和Hashtable实现类
HashMap和Hashtable都是Map接口的典型实现类,它们之间的关系完全类似于ArrayList和Vector的关系:Hashtable是一个古老的Map实现类,它从JDK 1.0起就已经出现了,当它出现时,Java还没有提供Map接口,所以它包含了两个烦琐的方法,即elements()(类似于Map接口定义的values()方法)和keys()(类似于Map接口定义的keySet()方法),现在很少使用这两个方法
区别:
Hashtable是一个线程安全的Map实现,但HashMap是线程不安全的实现,所以HashMap比Hashtable的性能高一点;但如果有多个线程访问同一个Map对象时,使用Hashtable实现类会更好。
Hashtable不允许使用null作为key和value,如果试图把null值放进Hashtable中,将会引发NullPointerException异常;但HashMap可以使用null作为key或value。
由于HashMap里的key不能重复,所以HashMap里最多只有一个key-value对的key为null,但可以有无数多个key-value对的value为null。例如:
main(){
HashMap hm=new HashMap();
hm.put(null,null);
//1处无法将key-value对放入,因为Map中已经有一个key-value对的key为null值
hm.put(null,null);//1
//2代码处可以放入该key-value对,因为一个HashMap中可以有多个value为null值
hm.put("a",null);//2
sout(hm);
}
为了成功地在HashMap、Hashtable中存储、获取对象,用作key的对象必须实现hashCode()方法和equals()方法。与HashSet集合不能保证元素的顺序一样,HashMap、Hashtable也不能保证其中key-value对的顺序。
类似于HashSet,HashMap、Hashtable判断两个key相等的标准也是:两个key通过equals()方法比较返回true,两个key的hashCode值也相等。
与HashSet类似的是,如果使用可变对象作为HashMap、Hashtable的key,并且程序修改了作为key的可变对象,则也可能出现与HashSet类似的情形:程序再也无法准确访问到Map中被修改过的key。
遍历
遍历Map中的全部key-value对:调用Map对象的keySet()方法返回全部key组成的Set集合,通过遍历该Set集合的所有元素(就是Map的全部key)就可以遍历Map中的所有key-value对。
for(Object key:hm.keySet()){
sout(key);
sout(ht.get(key));
}
LinkedHashMap实现类
HashSet有一个子类是LinkedHashSet,HashMap也有一个LinkedHashMap子类;LinkedHashMap也使用双向链表来维护key-value对的次序(其实只需要考虑key的次序),该链表负责维护Map的迭代顺序,迭代顺序与key-value对的插入顺序保持一致。
LinkedHashMap可以避免对HashMap、Hashtable里的key-value对进行排序(只要插入key-value对时保持顺序即可),同时又可避免使用TreeMap所增加的成本。
LinkedHashMap scores=new LinkedHashMap();
scores.put("语文",80);
scores.put("数学",70);
scores.put("英语",90);
for(Object key :scores.keySet()){
sout(key+"--->"+scores.get(key));
}
使用Properties读写属性文件
Properties类是Hashtable类的子类,正如它的名字所暗示的,该对象在处理属性文件时特别方便(Windows操作平台上的ini文件就是一种属性文件)。Properties类可以把Map对象和属性文件关联起来,从而可以把Map对象中的key-value对写入属性文件中,也可以把属性文件中的“属性名=属性值”加载到Map对象中。由于属性文件里的属性名、属性值只能是字符串类型,所以Properties里的key、value都是字符串类型。该类提供了如下三个方法来修改Properties里的key、value值。
String getProperty(String key)//获取Properties中指定属性名对应的属性值,类似于Map的get(Object key)方法。
String getProperty(String key, String defaultValue)//该方法与前一个方法基本相似。该方法多一个功能,如果Properties中不存在指定的key时,则该方法指定默认值。
Object setProperty(String key, String value)//设置属性值,类似于Hashtable的put()方法。
除此之外,它还提供了两个读写Field文件的方法。
void load(InputStream inStream)//从属性文件(以输入流表示)中加载key-value对,把加载到的key-value对追加到Properties里(Properties是Hashtable的子类,它不保证key-value对之间的次序)。
void store(OutputStream out, String comments)//将Properties中的key-value对输出到指定的属性文件(以输出流表示)中。
示例:
Properties props =new Properties();
props.setProperty("username","haha");
props.setProperty("password","123456");
props.store(new FileOutPutStream("a.ini"),"comment line");//1
Properties props2 =new Properties();
props2.setProperty("gender","male");
props2.load(new FileInputStream("a.ini"))//2
sout(props2)
其中①代码处将Properties对象中的key-value对写入a.ini文件中;②代码处则从a.ini文件中读取key-value对,并添加到props2对象中.
Properties可以把key-value对以XML文件的形式保存起来,也可以从XML文件中加载key-value对,用法与此类似,此处不再赘述。
SortedMap接口和TreeMap实现类
正如Set接口派生出SortedSet子接口,SortedSet接口有一个TreeSet实现类一样,Map接口也派生出一个SortedMap子接口,SortedMap接口也有一个TreeMap实现类。
TreeMap就是一个红黑树数据结构,每个key-value对即作为红黑树的一个节点。TreeMap存储key-value对(节点)时,需要根据key对节点进行排序。TreeMap可以保证所有的key-value对处于有序状态。TreeMap也有两种排序方式。
自然排序:TreeMap的所有key必须实现Comparable接口,而且所有的key应该是同一个类的对象,否则将会抛出ClassCastException异常。
定制排序:创建TreeMap时,传入一个Comparator对象,该对象负责对TreeMap中的所有key进行排序。采用定制排序时不要求Map的key实现Comparable接口。
TreeSet类似的是,TreeMap中也提供了一系列根据key顺序访问key-value对的方法。
Map.Entry firstEntry()//返回该Map中最小key所对应的key-value对,如果该Map为空,则返回null。
Object firstKey()//返回该Map中的最小key值,如果该Map为空,则返回null。
Map.Entry lastEntry()//返回该Map中最大key所对应的key-value对,如果该Map为空或不存在这样的key-value对,则都返回null。
Object lastKey()//返回该Map中的最大key值,如果该Map为空或不存在这样的key,则都返回null。
Map.Entry higherEntry(Object key)//返回该Map中位于key后一位的key-value对(即大于指定key的最小key所对应的key-value对)。如果该Map为空,则返回null。
Object higherKey(Object key)//返回该Map中位于key后一位的key值(即大于指定key的最小key值)。如果该Map为空或不存在这样的key-value对,则都返回null。
Map.Entry lowerEntry(Object key)//返回该Map中位于key前一位的key-value对(即小于指定key的最大key所对应的key-value对)。如果该Map为空或不存在这样的key-value对,则都返回null。
Object lowerKey(Object key)//返回该Map中位于key前一位的key值(即小于指定key的最大key值)。如果该Map为空或不存在这样的key,则都返回null。
NavigableMap subMap(Object fromKey, boolean fromInclusive, Object toKey,boolean toInclusive)//返回该Map的子Map,其key的范围是从fromKey(是否包括取决于第二个参数)到toKey(是否包括取决于第四个参数)。
SortedMap subMap(Object fromKey, Object toKey)//返回该Map的子Map,其key的范围是从fromKey(包括)到toKey(不包括)。
SortedMap tailMap(Object fromKey)//返回子Map,其key的范围是大于fromKey(包括)的所有key
NavigableMap tailMap(Object fromKey, boolean inclusive)//返回该Map的子Map,其key的范围是大于fromKey(是否包括取决于第二个参数)的所有key。
SortedMap headMap(Object toKey)//返回该Map的子Map,其key的范围是小于toKey(不包括)的所有key。
NavigableMap headMap(Object toKey, boolean inclusive)//返回该Map的子Map,其key的范围是小于toKey(是否包括取决于第二个参数)的所有key。
因为TreeMap中的key-value对是有序的,所以增加了访问第一个、前一个、后一个、最后一个key-value对的方法,并提供了几个从TreeMap中截取子TreeMap的方法。
类似于TreeSet中判断两个元素相等的标准,TreeMap中判断两个key相等的标准是:两个key通过compareTo()方法返回0,TreeMap即认为这两个key是相等的。
注意
再次强调:Set和Map的关系十分密切,Java源码就是先实现了HashMap、TreeMap等集合,然后通过包装一个所有的value都为null的Map集合实现了Set集合类。
各种实现类的分析
对于Map的常用实现类而言,HashMap和Hashtable的效率大致相同,因为它们的实现机制几乎完全一样;但HashMap通常比Hashtable要快一点,因为Hashtable需要额外的线程同步控制。
TreeMap通常比HashMap、Hashtable要慢(尤其在插入、删除key-value对时更慢),因为TreeMap底层采用红黑树来管理key-value对(红黑树的每个节点就是一个key-value对)。
使用TreeMap有一个好处:TreeMap中的key-value对总是处于有序状态,无须专门进行排序操作。当TreeMap被填充之后,就可以调用keySet(),取得由key组成的Set,然后使用toArray()方法生成key的数组,接下来使用Arrays的binarySearch()方法在已排序的数组中快速地查询对象。
对于一般的应用场景,程序应该多考虑使用HashMap,因为HashMap正是为快速查询设计的(HashMap底层其实也是采用数组来存储key-value对)。但如果程序需要一个总是排好序的Map时,则可以考虑使用TreeMap。LinkedHashMap比HashMap慢一点,因为它需要维护链表来保持Map中key-value时的添加顺序。IdentityHashMap性能没有特别出色之处,因为它采用与HashMap基本相似的实现,只是它使用==而不是equals()方法来判断元素相等。
操作集合的工具类:Collections
Java提供了一个操作Set、List和Map等集合的工具类:Collections,该工具类里提供了大量方法对集合元素进行排序、查询和修改等操作,还提供了将集合对象设置为不可变、对集合对象实现同步控制等方法。
排序操作
static void reverse(List list):反转指定List集合中元素的顺序。
static void shuffle(List list):对List集合元素进行随机排序(shuffle方法模拟了“洗牌”动作)。
static void sort(List list):根据元素的自然顺序对指定List集合的元素按升序进行排序。
static void sort(List list, Comparator c):根据指定Comparator产生的顺序对List集合元素进行排序。
static void swap(List list, int i, int j):将指定List集合中的i处元素和j处元素进行交换。
static void rotate(List list , int distance):当distance为正数时,将list集合的后distance个元素“整体”移到前面;当distance为负数时,将list集合的前distance个元素“整体”移到后面。该方法不会改变集合的长度。
ArrayList nums=new ArrayList();
nums.add(2);nums.add(-5);nums.add(3);nums.add(0);
sout(nums);
Collections.reverse(nums);//反转
sout(nums);
Collections.sort(nums);//排序
sout(nums);
Collections.shuffle(nums);//随机排序
sout(nums);
查找替换操作
Collections还提供了如下用于查找、替换集合元素的常用方法。
static int binarySearch(List list, Object key):使用二分搜索法搜索指定的List集合,以获得指定对象在List集合中的索引。如果要使该方法可以正常工作,则必须保证List中的元素已经处于有序状态。
static Object max(Collection coll):根据元素的自然顺序,返回给定集合中的最大元素。
static Object max(Collection coll, Comparator comp):根据Comparator指定的顺序,返回给定集合中的最大元素。
static Object min(Collection coll):根据元素的自然顺序,返回给定集合中的最小元素。
static Object min(Collection coll, Comparator comp):根据Comparator指定的顺序,返回给定集合中的最小元素。
static void fill(List list, Object obj):使用指定元素obj替换指定List集合中的所有元素。
static int frequency(Collection c, Object o):返回指定集合中指定元素的出现次数。
static int indexOfSubList(List source, List target):返回子List对象在父List对象中第一次出现的位置索引;如果父List中没有出现这样的子List,则返回-1。
static int lastIndexOfSubList(List source, List target):返回子List对象在父List对象中最后一次出现的位置索引;如果父List中没有出现这样的子List,则返回-1。
static boolean replaceAll(List list, Object oldVal, Object newVal):使用一个新值newVal替换List对象的所有旧值oldVal。
同步控制
Collections类中提供了多个synchronizedXxx()方法,该方法可以将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题。
Java中常用的集合框架中的实现类HashSet、TreeSet、ArrayList、ArrayDeque、LinkedList、HashMap和TreeMap都是线程不安全的。如果有多个线程访问它们,而且有超过一个的线程试图修改它们,则可能出现错误。Collections提供了多个静态方法可以把它们包装成线程同步的集合。
public static void main(){
Collection c =Collections.synchronizedCollection(new ArrayList());
List list =Collections.synchronizedList(new ArrayList());
Set s=Collections.synchronizedSet(new HashSet());
Map m=Collections.synchronizedLMap(new HashMap();
}
将新创建的集合对象传给了Collections的synchronizedXxx方法,这样就可以直接获取List、Set和Map的线程安全实现版本。
设置不可变集合
Collections提供了如下三类方法来返回一个不可变的集合。
emptyXxx():返回一个空的、不可变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。
singletonXxx():返回一个只包含指定对象(只有一个或一项元素)的、不可变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。
unmodifiableXxx:返回指定集合对象的不可变视图,此处的集合既可以是List,也可以是Set,还可以是Map。
上面三类方法的参数是原有的集合对象,返回值是该集合的“只读”版本。通过Collections提供的三类方法,可以生成“只读”的Collection或Map。
List unmodifiableList=Collections.emptyList();//创建一个空的、不可改变的List对象
Set unmodifiableSet=Collections.singleton("aaa");//创建一个只有一个元素,且不可改变的Set对象
Map scores = new HashMap();
spours.put("yuwen",90);spours.put("yingyu",80);
Map unmodifiableMap=Collections.unmodifiableMap(scores);
unmodifiableList.add("xxx");
unmodifiableSet.add("xxx");
unmodifiableMap.put("yuwen",90);
上面程序的3行粗体字代码分别定义了一个空的、不可变的List对象,一个只包含一个元素的、不可变的Set对象和一个不可变的Map对象。不可变的集合对象只能访问集合元素,不可修改集合元素。所以上面程序中①②③处的代码都将引发UnsupportedOperationException异常。