Oracle数据库
目录
7. 创建和管理数据表,对表进行的操作 创建删除修改表 13
9. 约束(not null非空,unique唯一性,primary key主键,foreign key外键,check检查) 17
-
数据库初步
SQL语句分为以下三种类型:
DML::Data Manipulation Language 数据库操纵语言
-
DML用于查询与修改数据记录:包括如下SQL语句
-
Insert :添加数据到数据库中
-
Update:修改数据库中的数据
-
Delete:删除数据库中的数据
-
Select:选择(查询)数据
DDL::Data Definition Language 数据库定义语言
-
DDL用于定义数据库的结构,比如创建、修改或删除数据库对象,包括如下SQL语句:
-
Create table:创建数据库表
-
Alter table :更改表结构,添加,删除,修改列长度
-
Drop table:删除表
-
Create index:在表上建立索引
-
Drop index:删除索引
DCL::Data Control Language 数据库控制语言
-
DCL用来控制数据库的访问,包括如下sql语句:
-
GRANT:授予访问权限
-
REVOKE:撤销访问权限
-
COMMIT:提交事务处理
-
ROLLBACK:事务处理回退
-
SAVEPOINT:设置保存点
-
LOCK:对数据库的特定部分进行锁定
-
select… from…
-
返回表中的全部数据
|
Select * from employee; |
-
返回表中指定列的数据
|
Select department_id from employee; |
-
使用别名,一定要用双引号,不能使用单引号
|
Select department_id as "department" from employee; |
-
使用distinct,查找不重复数据
|
Select distinct department_id from employee; |
-
显示表结构
|
Distinct employees; |
-
过滤where和排序order by数据
-
使用where语句过滤掉不满足条件的语句
|
Select employee_id from employees where department_id=90; |
|
Select employee_id from employees where salary<=3000; |
|
Where语句可跟>,<,>=,<=,=,!=等等,其中字符和日期用单引号'字符串',不能使用双引号。 |
-
其他比较运算
-
Between…and… 在两个值之间,包含边界
|
Select last_name,salary from employees where salary between 2500 and 3000; |
-
In(set): 等于值列表中的一个
|
Select employee_id ,last_name from employees where manager_id in(101,201); |
-
Like:模糊查询(%表示零个或多个 '_'表示一个)
|
Select first_name from employees where first_name like '_o%'; 表示第二个字符是'o',后边有零个或多个字符 |
-
Is null:空值,用来判断空值
|
Select last_name from employees where manager_id is null; |
-
逻辑运算:并and ,或or,否not
|
Select employee_id,last_name from employees where salary>1000 and job_id like '%MAN%'; |
|
Select employee_id,last_name from employees where salary>1000 or job_id like '%MAN%'; |
|
Select last_name ,job_id from employees where job_id not in ('IT_PROG','ST_CLERK'); |
-
Order by子句在select语句的结尾
Asc :升序(ascend默认升序)
Desc:降序(descend)
|
Select last_name,job_id,department_id,hire_date from employees order by hire_date; |
|
Select last_name,job_id,hire_date from employees order by hire_date descend; |
-
多个列排序
|
Select last_name,salary,department_id from employees order by department_id,salary desc; 先按department_id排序,然后按照salary排序 |
|
select last_name,department_id,salary from employees order by salary,department_id desc; 先按salary排序,然后安好department_id排序。 |
-
多表查询
-
等值查询
|
Select employees.department_id,departments.department_id from employees,departments where employees.department_id=departments.department_id; |
|
查询两个数据表中department_id相同的数据 |
-
多个连接条件与and操作符
-
区分重复的列名
|
使用表名前缀在多个表中区分相同的列 在不同的表中具有相同列名的列可以用表的别名加以区分。 |
|
Select e.employee_id ,e.last_name ,d.department_id,d.location_id from employees e,departments d where e.department_id=d.department_id; |
|
使用别名可以简化查询, 使用表名前缀可以提高执行效率 |
-
连接多个表
连接n个表,至少需要n-1个连接条件,例如:连接三个表,至少需要两个连接条件。
|
select e.last_name,e.salary,j.grade_level from employees e,job_grades j where e.salary between j.lowest_sal and j.highest_sal; |
-
内连接和外连接
-
内连接:(典型的联接运算,使用像=或<,>之类的比较运算符),包括相等连接和自然连接。内连接使用比较运算符根据每个表共有的列的值匹配两个表中的行。例如,检索students和courses表中学生标识号相同的所有行。
A inner join B on 条件
-
外连接:外连接可以是左向外连接,右向外连接或完整外部连接。
-
左连接:返回左表中的所有行,如果左表中行在右表中没有匹配行,则结果中右表中的列返回空值。
A left join B on 条件
-
右连接:返回右表中的所有行,如果右表中行在左表中没有匹配行,则结果中左表中的列返回空值。
A right join B on 条件
-
全连接:返回左表和右表中的所有行。当某行在另一表中没有匹配行,则另一表中的列返回空值。
A full join B on 条件
-
交叉连接:不带where的子句,表示两个表的乘积,即A表的每个数据都对应B表的所有数据。当与笛卡尔积,左表和右表组合。
-
有where子句,往往会先生成两个表行数乘积的数据表,然后才根据where条件从中选择。查询结果跟等值连接的查询结果是一样。
-
自连接,使用本表中数据连接查询
|
select worker.last_name || 'work for'||manager.last_name from employees worker,employees manager where worker.manager_id=manager.employee_id; |
|
首先,先给employees员工起别名,worker,manager,然后查找的是worker.last_name和manager.last_name。条件是worker.manager_id与manager.employee_id相同。 |
-
分组函数(group by,having)
-
什么是分组函数
分组函数作用于一组数据,并对一组数据返回一个值。
-
组函数类型
Commission_pct:表示忽略空值
-
AVG()求平均值,(数值型数据)
-
SUM()合计,计算总和(数值型数据)
-
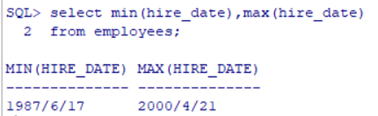
MIN()求最小值
-
MAX()求最大值

-
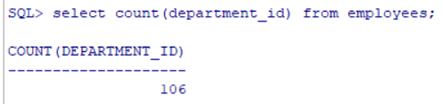
COUNT()计数,返回表中记录总数(默认不包含空值)
-
COUNT(expr)返回expr不为空的记录总数


-
DISTINCT关键字,返回非空且不重复的记录。

-
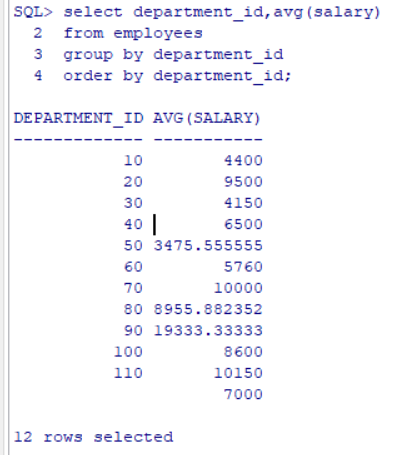
GROUP BY子句,可以将表中的数据按照列中的元素进行分组。

Where和group by是两个子句。
-
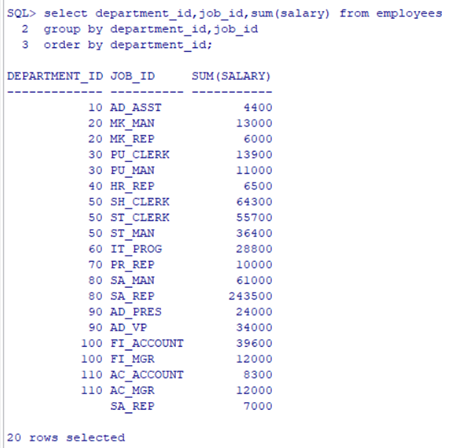
在group by子句中包含多个列
-
-
过滤分组 having子句
使用having过滤分组,
-
行已经被分组
-
使用了组函数
-
满足having子句中条件的分组将被显示

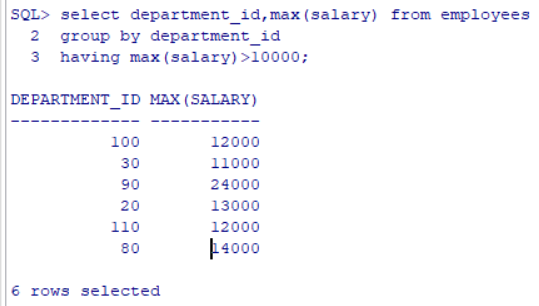
Having后面紧跟组函数:如max(),avg(),min(),count(),sum()等等
使用having子句
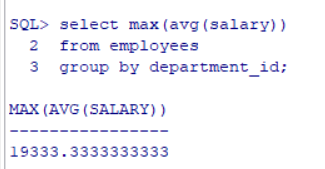
使用嵌套
-
-
子查询

-
子查询(内查询)在主查询之前一次执行完成。子查询的结果被主查询使用。
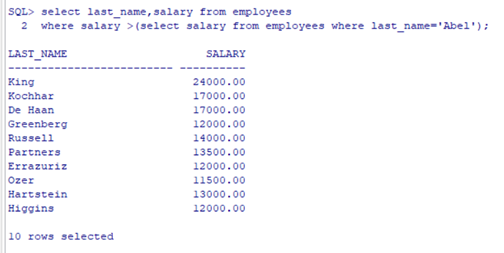
注意:
-
子查询要包含在括号中
-
将子查询放在比较条件的右侧
-
单行操作符对应单行子查询,多行操作符对应多行子查询

题目:返回job_id与141号员工相同,salary比143号员工多的员工的姓名,job_id,和工资。

题目:返回公司工资最少的员工的last_name,job_id和salary
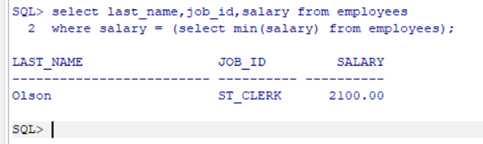
题目:查询最低工资大于50号部门最低工资的部门id和其最低工资
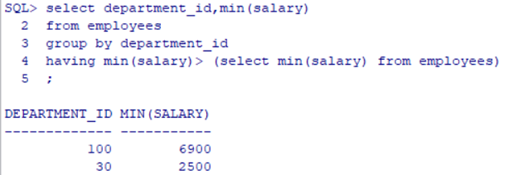
-
多行子查询
返回多行
使用多行比较操作符

-
创建和管理数据表,对表进行的操作

-
Create table语句
必须指定:表名,列名,数据类型,尺寸
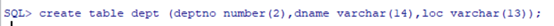


-
使用子查询创建表,复制表

-
Alter table语句,增删改
使用 ALTER TABLE 语句追加, 修改, 或删除列的语法
-
增加1列

-
修改1列

-
删除1列

-
修改列名

-
-
删除表drop table
数据和结构都被删除
所有正在运行的相关事务被提交
所有相关索引被删除
Drop table语句不能回滚。
-
清空表truncate table
删除表中所有的数据
释放表的存储结构
Truncate 语句不能回滚。
如果想要回滚数据,可以使用delete语句
Delete from emp2;select * from emp2;rollback;select * from emp2;
-
总结

-
数据处理,对数据表中的数据进行处理。

-
Insert 语句语法

使用insert语句向表中插入数据,
使用这种语法一次只能向表中插入一条数据。
-
从其他表中拷贝数据
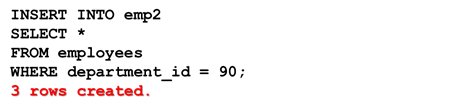
不必书写 VALUES 子句。
子查询中的值列表应与 INSERT 子句中的列名对应
-
Update语句语法

使用update语句更新数据
可以一次更新多条数据
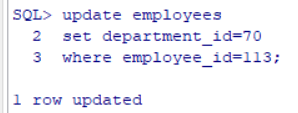
如果省略where子句,则表中的说有数据都将被更新。
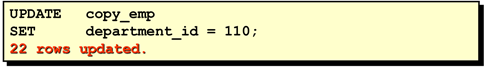
可以在update语句中使用子查询
题目:更新 114号员工的工作和工资使其与205号员工
相同。

-
删除数据delete from table where 条件
使用 DELETE 语句从表中删除数据。
使用where子句删除指定的记录,

如果省略where子句,则表中的全部数据将被删除
在delete中使用子查询
-
约束(not null非空,unique唯一性,primary key主键,foreign key外键,check检查)

-
表级约束和列级约束

-
Not null约束:保证列值不能为空,只能定义在列级
系统命名

用户命名

-
Unique约束:只允许值出现1此,除了null可以多次出现
系统命名:

用户命名:constraint前要加逗号。

-
Primary key约束
PRIMARY KEY 约束唯一标识数据库表中的每条记录。
主键必须包含唯一的值。
主键列不能包含 NULL 值。
每个表都应该有一个主键,并且每个表只能有一个主键。
系统命名:

用户命名:

-
Foreign key约束
一个表中的 FOREIGN KEY 指向另一个表中的 PRIMARY KEY。
FOREIGN KEY 约束用于预防破坏表之间连接的动作。
FOREIGN KEY 约束也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
CREATE TABLE Orders
(
Id_O int NOT NULL,
OrderNo int NOT NULL,
Id_P int,
PRIMARY KEY (Id_O),
FOREIGN KEY (Id_P) REFERENCES Persons(Id_P)
)
-
Check约束
CHECK 约束用于限制列中的值的范围。
如果对单个列定义 CHECK 约束,那么该列只允许特定的值。
如果对一个表定义 CHECK 约束,那么此约束会在特定的列中对值进行限制。
CREATE TABLE Persons
(
Id_P int NOT NULL CHECK (Id_P>0),
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
-
添加和删除约束,但是不能修改约束

添加not null约束
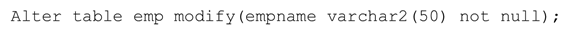
添加主键约束

删除约束:

无效化约束:

激活约束:

查询约束:


-
创建索引:
CREATE INDEX index_name
ON table_name (column_name)