Mysql(超级详细)
(黑小子-余)

一、Mysql介绍
1、应用环境

2、系统特性
(1)mySQL使用 C和 C++编写,并使用了多种编译器进行测试,保证了源代码的可移植性。
(2)支持 AIX、FreeBSD、HP-UX、Linux、Mac OS、NovellNetware、OpenBSD、OS/2 Wrap、Solaris、Windows等多种操作系统。
(3)为多种编程语言提供了 API。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby,.NET和 Tcl 等。
(4)支持多线程,充分利用 CPU 资源。
(5)优化的 SQL查询算法,有效地提高查询速度。
(6)既能够作为一个单独的应用程序应用在客户端服务器网络环境中,也能够作为一个库而嵌入到其他的软件中。
(7)提供多语言支持,常见的编码如中文的 GB 2312、BIG5,日文的 Shift_JIS等都可以用作数据表名和数据列名。
(8)提供 TCP/IP、ODBC 和 JDBC等多种数据库连接途径。
(9)提供用于管理、检查、优化数据库操作的管理工具。
(10)支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
(11)支持多种存储引擎。
(12)MySQL 是开源的,所以你不需要支付额外的费用。
(13)MySQL 使用标准的 SQL数据语言形式。
(14)MySQL 对 PHP 有很好的支持,PHP是比较流行的 Web 开发语言。
(15)MySQL是可以定制的,采用了 GPL协议,你可以修改源码来开发自己的 MySQL 系统。
(16)在线 DDL/更改功能,数据架构支持动态应用程序和开发人员灵活性(5.6新增)。
(17)复制全局事务标识,可支持自我修复式集群(5.6新增)。
(18)复制无崩溃从机,可提高可用性(5.6新增)。
(19)复制多线程从机,可提高性能(5.6新增)。
(20)3倍更快的性能(5.7 新增)。
(21)新的优化器(5.7新增)。
(22)原生JSON支持(5.7新增)。
(23)多源复制(5.7新增)。
(24)GIS的空间扩展 (5.7新增)。
3、存储引擎
4、应用架构
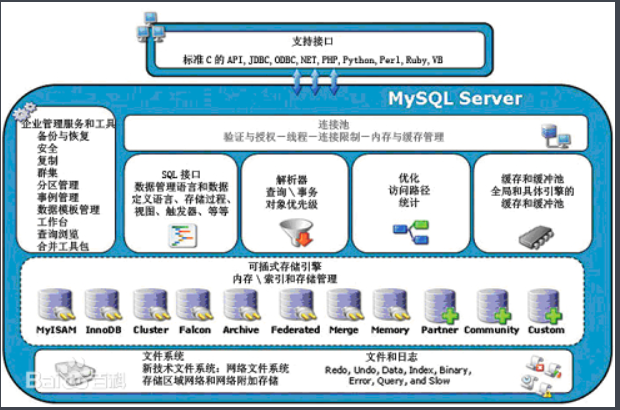
5、索引
索引功能
索引是一种特殊的文件(InnoDB 数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。索引不是万能的,索引可以加快数据检索操作,但会使数据修改操作变慢。每修改数据记录,索引就必须刷新一次。为了在某种程度上弥补这一缺陷,许多 SQL 命令都有一个 DELAY_KEY_WRITE 项。这个选项的作用是暂时制止 MySQL 在该命令每插入一条新记录和每修改一条现有之后立刻对索引进行刷新,对索引的刷新将等到全部记录插入/修改完毕之后再进行。在需要把许多新记录插入某个数据表的场合,DELAY_KEY_WRITE 选项的作用将非常明显。另外,索引还会在硬盘上占用相当大的空间。因此应该只为最经常查询和最经常排序的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。从理论上讲,完全可以为数据表里的每个字段分别建一个索引,但 MySQL 把同一个数据表里的索引总数限制为16个。(1)InnoDB 数据表的索引与 InnoDB数据表相比,在 InnoDB 数据表上,索引对 InnoDB 数据表的重要性要大得多。在 InnoDB 数据表上,索引不仅会在搜索数据记录时发挥作用,还是数据行级锁定机制的基础。“数据行级锁定”的意思是指在事务操作的执行过程中锁定正在被处理的个别记录,不让其他用户进行访问。这种锁定将影响到(但不限于)SELECT、LOCKINSHAREMODE、SELECT、FORUPDATE 命令以及 INSERT、UPDATE 和 DELETE 命令。出于效率方面的考虑,InnoDB 数据表的数据行级锁定实际发生在它们的索引上,而不是数据表自身上。显然,数据行级锁定机制只有在有关的数据表有一个合适的索引可供锁定的时候才能发挥效力。(2)限制如果 WHERE 子句的查询条件里有不等号(WHERE coloum !=),MySQL 将无法使用索引。类似地,如果 WHERE 子句的查询条件里使用了函数(WHERE DAY(column)=),MySQL 也将无法使用索引。在 JOIN 操作中(需要从多个数据表提取数据时),MySQL 只有在主键和外键的数据类型相同时才能使用索引。如果 WHERE 子句的查询条件里使用比较操作符 LIKE 和 REGEXP,MySQL 只有在搜索模板的第一个字符不是通配符的情况下才能使用索引。比如说,如果查询条件是 LIKE 'abc%‘,MySQL 将使用索引;如果查询条件是 LIKE '%abc’,MySQL 将不使用索引。在 ORDER BY 操作中,MySQL 只有在排序条件不是一个查询条件表达式的情况下才使用索引。(虽然如此,在涉及多个数据表查询里,即使有索引可用,那些索引在加快 ORDER BY 方面也没什么作用)。如果某个数据列里包含许多重复的值,就算为它建立了索引也不会有很好的效果。比如说,如果某个数据列里包含的净是些诸如 “0/1” 或 “Y/N” 等值,就没有必要为它创建一个索引。
索引类别
(1)普通索引普通索引(由关键字 KEY 或 INDEX 定义的索引)的任务是加快对数据的访问速度。因此,应该只为那些最经常出现查询条件(WHERE column =)或排序条件(ORDER BY column)中的数据列创建索引。只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。(2)索引普通索引允许被索引的数据列包含重复的值。比如说,因为人有可能同名,所以同一个姓名在同一个“员工个人资料”数据表里可能出现两次或更多次。如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该用关键字UNIQUE 把它定义为一个索引。这么做的好处:一是简化了 MySQL 对这个索引的管理工作,这个索引也因此而变得更有效率;二是 MySQL 会在有新记录插入数据表时,自动检查新记录的这个字段的值是否已经在某个记录的这个字段里出现过了;如果是,MySQL 将拒绝插入那条新记录。也就是说,索引可以保证数据记录的独特性。事实上,在许多场合,人们创建索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。(3)主索引(4)外键索引如果为某个外键字段定义了一个外键约束条件,MySQL 就会定义一个内部索引来帮助自己以最有效率的方式去管理和使用外键约束条件。(5)复合索引索引可以覆盖多个数据列,如像 INDEX (columnA, columnB) 索引。这种索引的特点是 MySQL 可以有选择地使用一个这样的索引。如果查询操作只需要用到 columnA 数据列上的一个索引,就可以使用复合索引 INDEX(columnA, columnB)。不过,这种用法仅适用于在复合索引中排列在前的数据列组合。比如说,INDEX (A,B,C) 可以当做 A 或 (A,B) 的索引来使用,但不能当做 B、C 或 (B,C) 的索引来使用。
索引长度
在为 CHAR 和 VARCHAR 类型的数据列定义索引时,可以把索引的长度限制为一个给定的字符个数(这个数字必须小于这个字段所允许的最大字符个数)。这么做的好处是可以生成一个尺寸比较小、检索速度却比较快的索引文件。在绝大多数应用里,数据库中的字符串数据大都以各种各样的名字为主,把索引的长度设置为10~15 个字符已经足以把搜索范围缩小到很少的几条数据记录了。在为 BLOB 和 TEXT 类型的数据列创建索引时,必须对索引的长度做出限制;MySQL 所允许的最大索引全文索引文本字段上的普通索引只能加快对出现字段内容最前面的字符串(也就是字段内容开头的字符)进行检索操作。如果字段里存放的是由几个、甚至是多个单词构成的较大段文字,普通索引就没什么作用了。这种检索往往以的形式出现,这对 MySQL 来说很复杂,如果需要处理的数据量很大,响应时间就会很长。这类场合正是全文索引(full-textindex)可以大显身手的地方。在生成这种类型的索引时,MySQL 将把在文本中出现的所有单词创建为一份清单,查询操作将根据这份清单去检索有关的数据记录。全文索引即可以随数据表一同创建,也可以等日后有必要时再使用下面这条命令添加:ALTER TABLE tablename ADD FULLTEXT(column1,column2)有了全文索引,就可以用 SELECT 查询命令去检索那些包含着一个或多个给定单词的数据记录了。下面是这类查询命令的基本语法:SELECT * FROM tablenameWHERE MATCH (column1,column2) AGAINST('word1','word2','word3')上面这条命令将把 column1 和 column2 字段里有 word1、word2 和 word3 的数据记录全部查询出来。注解:InnoDB 数据表不支持全文索引。
查询和索引
只有当数据库里已经有了足够多的测试数据时,它的性能测试结果才有实际参考价值。如果在测试数据库里只有几百条数据记录,它们往往在执行完第一条查询命令之后就被全部加载到内存里,这将使后续的查询命令都执行得非常快--不管有没有使用索引。只有当数据库里的记录超过了 1000 条、数据总量也超过了 MySQL 服务器上的内存总量时,数据库的性能测试结果才有意义。在不确定应该在哪些数据列上创建索引的时候,人们从 EXPLAIN SELECT 命令那里往往可以获得一些帮助。这其实只是简单地给一条普通的 SELECT 命令加一个 EXPLAIN 关键字作为前缀而已。有了这个关键字,MySQL 将不是去执行那条 SELECT 命令,而是去对它进行分析。MySQL 将以表格的形式把查询的执行过程和用到的索引等信息列出来。在 EXPLAIN 命令的输出结果里,第1列是从数据库读取的数据表的名字,它们按被读取的先后顺序排列。type列指定了本数据表与其它数据表之间的关联关系(JOIN)。在各种类型的关联关系当中,效率最高的是 system,然后依次是 const、eq_ref、ref、range、index 和 All(All 的意思是:对应于上一级数据表里的每一条记录,这个数据表里的所有记录都必须被读取一遍——这种情况往往可以用一索引来避免)。possible_keys 数据列给出了 MySQL 在搜索数据记录时可选用的各个索引。key 数据列是 MySQL 实际选用的索引,这个索引按字节计算的长度在 key_len 数据列里给出。比如说,对于一个 INTEGER 数据列的索引,这个字节长度将是4。如果用到了复合索引,在 key_len 数据列里还可以看到 MySQL 具体使用了它的哪些部分。作为一般规律,key_len 数据列里的值越小越好。ref 数据列给出了关联关系中另一个数据表里的数据列的名字。row 数据列是 MySQL 在执行这个查询时预计会从这个数据表里读出的数据行的个数。row 数据列里的所有数字的乘积可以大致了解这个查询需要处理多少组合。最后,extra 数据列提供了与 JOIN 操作有关的更多信息,比如说,如果 MySQL 在执行这个查询时必须创建一个临时数据表,就会在 extra 列看到 usingtemporary 字样。
二、Mysql安装(可供学习和使用)
1、mysql官网下载地址:https://dev.mysql.com/downloads/mysql/
(1)下载Mysql,我这里下载的是5.5.18-winx64版本的驱动程序,双击
![]()
(2)next下一步

(3)勾选红色框框选项,next下一步
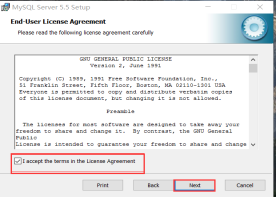
(4)推荐自定义安装,默认安装在C盘,我个人安装建议Mysql不要安装在C盘里
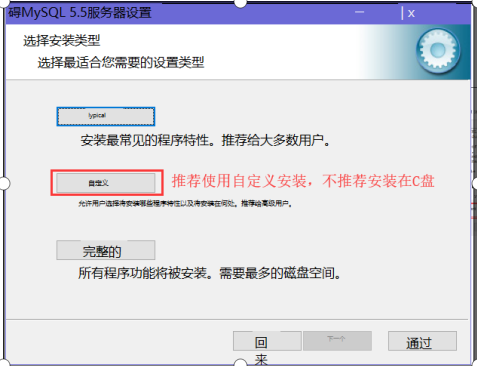
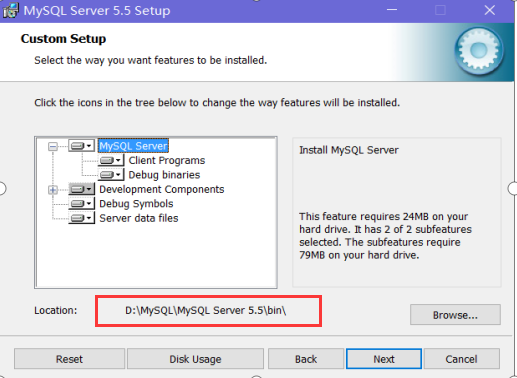
(5)next下一步,初始化完毕。

(6)现在开始安装Mysql,双击,然后next下一步

(7)next下一步
(8)mysql安装其实比较傻瓜式,next下一步
(9)开发机器
(10)next下一步
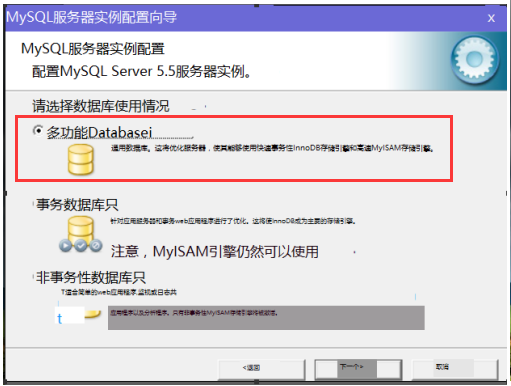
(11)next下一步
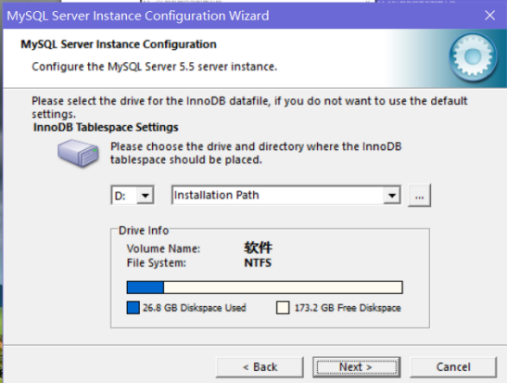
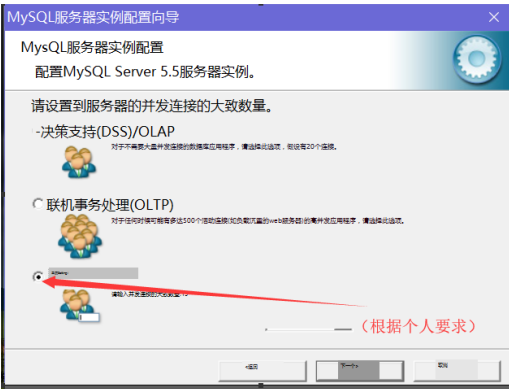
(12)根据个人要求,选择
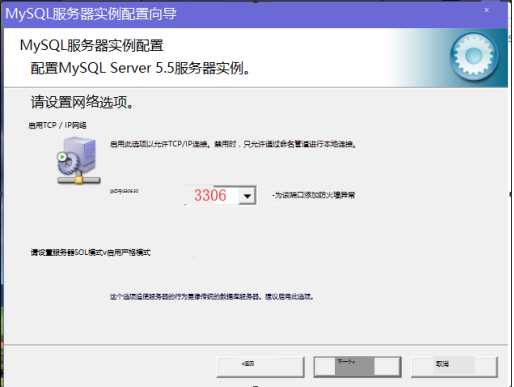
(13)next下一步,安装成功!
(14)查看Mysql是否安装成功
1.配置mysql环境变量(windows10系统),在系统Path环境变量中编辑,Mysql的bin目录路径:

2.打开cmd窗口,输入:
net start mysql -开启
如果能启动,那说明安装成功了。
net stop mysql -关闭
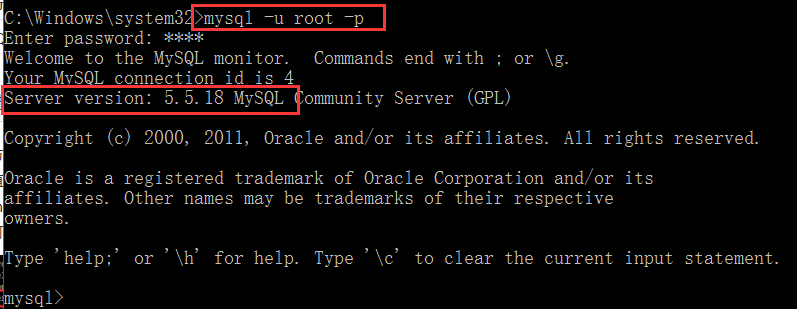
3.登录mysql查看版本信息,cmd窗口,输入:
>mysql -u root -p
>1234(密码)
2、Mysql图形化操作工具:SQLyog
(1)我用的是SQLyog,这个根据个人喜好来选吧。我看它页面精简,好看一点。
说个趣事(真实发生的),同时也引以为戒:我以前刚进一家小公司,旁边坐着一个也是新来的女同事,她用了一款mysql图形操作工具,太精简了,说白了,就是好lousy,不知道她从哪弄的;我坐她旁边,快下班了,瞄她电脑时,亲眼看见她点击鼠标操作时把服务器数据库删掉了,然后再输地址导数据库,不存在。我操:“rm -rf ?”。然后,对面的老开发,都在说数据库咋没了?我们的数据库咋没了;群里面也炸开了锅,纷纷说有没有备份,通通提前下班了。然后老板来了:说谁弄的;然后那妹子哭了。
我本来觉得这是一件伤心的事,但老板接下来的一般话,我没有忍住。
老板生气有十分腼腆笑着跟经理说:“**,你前阵子看过一段子没有?员工把公司数据库删了,然后跑路了;我当时还在笑,没想到今天居然被我也碰到了”。
老板刚说完,我他瞄的没憋住,想起之前我也看到过这种段子,跟着老板一起笑,笑出声音的那种,经理虽然着急但也没憋住笑,那妹子就在一旁哭。
不过,后来到了6点30,我是新来的,经理不走,我也不敢走,那妹子更是不敢走。经理要我们先回去,在那里也没用,下电梯的途中我说了一些话安慰了一下那妹子。
第二天,正常去上班,经理说好了,不过丢失了一些数据。(注意:一定要引以为戒)

(2)SQLyog下载安装,我是网上搜的,里面有广告插件,温馨提示还是要找到正规的。

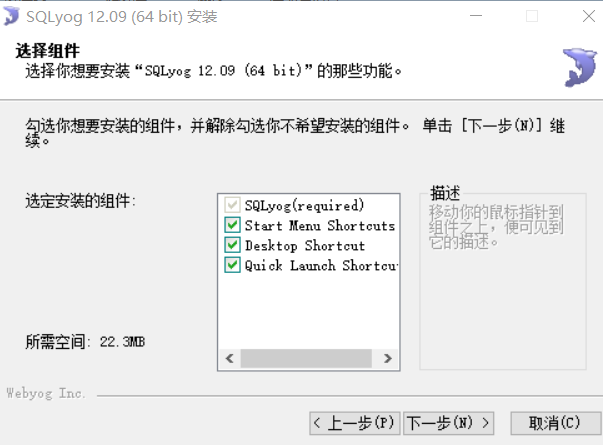
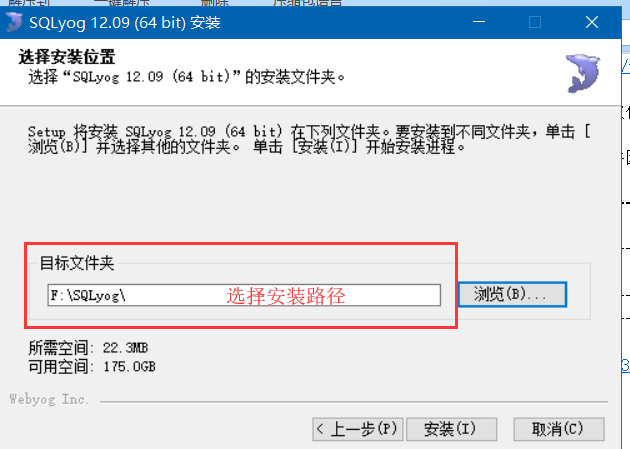
(3)新建用户,密码,图形化操作,简直是爽的不要不要滴。测试一下,是否能连接上。(图二,表示连接成功)
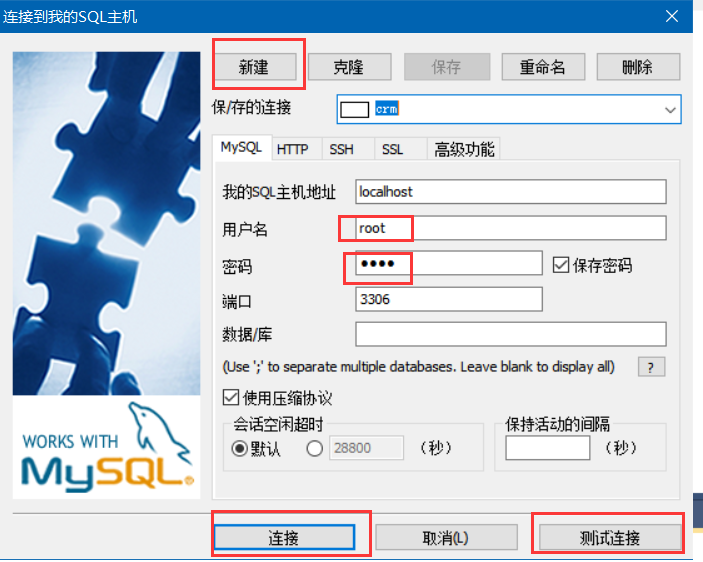
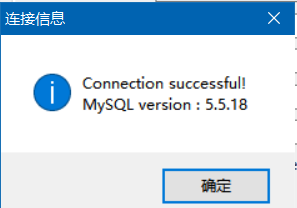
(4)好了该干大事了,sql语言走起。不过在这里再提供一下,
Oracle数据库安装教程
三、MySql使用
1、数据库分类
-
DDL :数据库定义语言 建库,建表,视图,索引
-
DML :数据库操作语言 对表中数据 增删改
-
DQL :数据库查询语言 对表中的记录查询
-
DCL :数据库控制语言 对用户权限的设置,控制事务
2、基础
(1)DDL : 数据库定义语言
1.创建数据库
create database dbname(数据库名); --- 直接创建数据库
create database if not exists dbname ; ---判断是否存在,如果不存在则创建数据库
create database dbname default character set gbk ; ---创建数据库并指定字符集为gbk
2.查看数据库
show database ; ---查看所有数据库
show create database dbname; ---查看某个数据库的定义信息
3.修改数据库
alter database dbname default character set utf8 ; ---修改数据库默认字符集
4.删除数据库
drop database dbname(数据库名);
5.使用数据库
select database(); ---查看正在使用的数据库
use dbname; ---切换数据库
6.创建表
create table `user`(
`userid` int ,
`name` varchar(20) ,
`birthday` date
) ;
7.查看表
use dbname; --- 选择数据库
show tables; ---显示该数据库所有表
desc user; ---显示表结构
show create table user; ---查看创建表的sql语句
8.快速创建一个表结构相同的表
create table user2 like user;
desc user;
9.删除表
drop table user;
drop table if exists user; --- 判断表是否存在并删除user表
10.修改表结构
#添加表列ADD
alter table user add age varchar(20); ---为user表添加一个‘age’字,类型为 varchar(20)
#修改列类型MODIFY
alter table user modify age int(4) ; ---将表中‘age’字段的类型修改为int
#修改列名 CHANGE
alter table user name remark username varchar(50); ---将表中‘name’字段修改为username,类型修改为varchar(50)
#删除列 DROP
alter table user drop age;
#修改表名RENAME
rename table user to users ;
#修改字符集character set
alter table user character set gbk ;
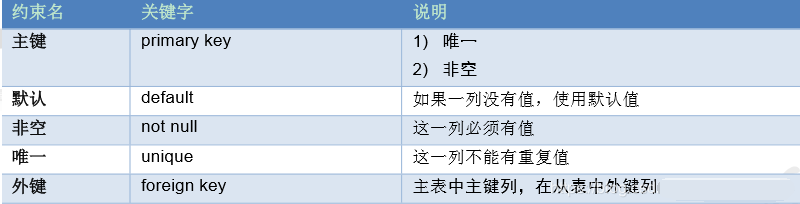
11.数据库表约束
语法:CREATE TABLE 表名(){
列名 int primary key AUTO_INCREMENT
}AUTO_INCREMENT=起始值;
#指定起始值为1000
create table uesr(){
id int primary key auto_increment,
name varchar(20),
} auto_increment = 1000;
insert into user values(null,'观音菩萨');
select * from user;
#创建好以后修改起始值
alter table user auto_increment = 2000;
insert into user values(null,'玉帝被猴打过');
#指定默认值
create table user(){
id int,
name varchar(20),
address varchar(20) default ''广州 ---地址默认为广州
}
insert into user values(null,'玉帝被猴打过',default);
select * from user;
#外键约束
1.添加外键
语法:alter table 从表 add constraint 外键(形如:FK_从表_主表) foreign key (从表外键字段) references 主表(主键字段);
2.删除外键
语法:drop foreign key 外键名称;
3.外键级联
-- 删除employee表,重新创建employee表,添加级联更新和级联删除
drop table employee;
create table employee( id int primary key auto_increment, name varchar(20), age int, dep_id int, -- 外键对应主表的主键
-- 创建外键约束
constraint emp_depid_fk foreign key (dep_id) references department(id) on update cascade on delete cascade )
-- 再次添加数据到员工表和部门表
INSERT INTO employee (NAME, age, dep_id) VALUES ('张三', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('李四', 21, 1);
-- 删除部门表?能不能直接删除?
drop table department;
-- 把部门表中id等于1的部门改成id等于10
update department set id=10 where id=1;
select * from employee; select * from department;
-- 删除部门号是2的部门
delete from department where id=2;




(2)DML :数据库操作语言
1.插入数据
insert into user/表名 (userid,name,birthday,age)/列名 values(3,'猪八戒','2019-12-27',18); ---写字段名
insert into user/表名 values(3,'孙悟空','2019-12-25',20); ---不写字段名
2.修改数据
update user set age='公' ; ---将表中字段age的数据都改成‘公’
update user set name='沙和尚' where userid=3; ---将 userid 条件 =3 的name改成 ‘沙和尚’
3.删除数据
delete from user; ---删除user表中所有数据
delete from user where userid=3; ---删除user表中 userid 条件 =3的所有数据
4、乱码现象
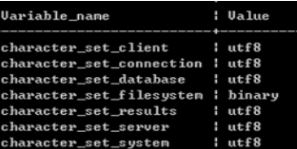
用DOS窗口查询数据时,部分数据乱码,但是工具中查询是正常的。原因在于工具和DOS窗口的编码格式不一致。
(1)查看包含character开头的全局变量
show variables like 'character%';
(2)修改 client、connection、results 的编码为 GBK,保证和 DOS 命令行编码保持一致
set names gbk;
5.蠕虫复制(将一张表的数据复制到另一张表中去)
drop table user2;
create table user2 like user ; ---创建一个表结构和user 一样的 user2 表
insert into user2 select * from user ; --- 将user表中的数据添加到user2中
insert into user2 (id,name) select id,name from user; ---只将user表中的id和name两个字段的数据添加到user2中

(3)DQL :数据库查询语言
1.查询数据
select * from user;---查询所有数据
select userid,name,birthday from user ; ---只查某些字段数据
select userid as '用户编号' ,name as '用户姓名' ,birthday as '用户生日' from user as '用户' ; ---给表和列 取别名
2.清除重复值 : 关键字:DISTINCT
select address from user ; ---查询user的地址
select distinct address from user ; ---去掉重复的记录
3.查询结果参与运算
select num+ 5 from user; ---给user表age+5
select * from user;
select * ,( num + num2 ) as 总数量 from user ; ---数量1+数量2 ,as 可以省略
4.条件查询运算符
5.逻辑运算符
(1)>,< ,=
select * from user where age>10 ; ---查询年龄大于10岁的用户
select * from user where age<10 ; ---查询年龄小于10岁的用户
select * from user where age=10; ---查询年龄等于10岁的用户
select * from user where age <> 10 ; ---查询age不等于20岁的学生,两种写法
select * from user where age !=10 ;
(2) IN 关键字
select * from user where userid in(1,3,5); ---查询userid是1、3、5的学生
select * from user where id not in(1,3,5); ---查询id不是1、3、5的学生
(3)范围查询 BETWEEN关键字
select * from user where age between 5 and 10; ---查询age成绩大于等于5,且小于等于10的学生
select * from user where age >= 5 && age<=10 ;
(4)模糊查询 LIKE关键字
select * from user where name like '孙' ; ---查询姓马的用户
select * from user where name like '孙%'; ---查询姓孙开头的用户
select * from user where name like '孙_' ; ---查询姓孙,且名字有两个字的用户
(5)排序 ORDER BY DESC: 降序 ASC:升序
select * from user order by age desc ; ---倒序
select * from user order by age asc; ---升序
(6)聚合函数
select count(*) as 总人数 from user; ---查询学生总数
select count(userid) as 总人数 from user;
select ifnull(id,0)from user ; ---查询userid字段,如果为null,则用0代替
select count(ifnull(id,0)) from user; ---利用ifnull()函数,如果记录为null,给个默认值,这样统计的数据就不会遗漏
select count(*) from user where age>0; ---查询年龄大于20的总数
select sum(age) 总年龄 from user ; ---查询年龄总和
select avg(age) 平均分 from user ; ---查询平均年龄
select max(age) 最大年龄 from user; ---查询最大年龄
select min(age) 最小年龄 from user; ---查询最小年龄
(7)分组 GROUP BY
select sex,avg(age) from user group by sex ; ---按性别进行分组,求男女的年龄平均数
select sex,count(*) from user group by sex; ---按性别分组,查询男女各性别的总数
select sex,count(*) from user where age>5 group by sex; ---查询年龄大于5,并且按性别分组,和统计每组用户的总数
select sex,count(*) from user where age>5 group by sex having count(*) > 2; ---查询年龄大于5,并且筛选按性别分组后,性别大于2的数据
(8)分页 LIMIT
select * from user limit 2,6; ---查询用户数据从第三条开始显示,显示6条。下标从0开始
select * from user limit 5; ---如果第一个参数是0,可以省略第一个参数。
select * from uesr limit 10,5; ---如果数据不够5条,那么有多少显示多少
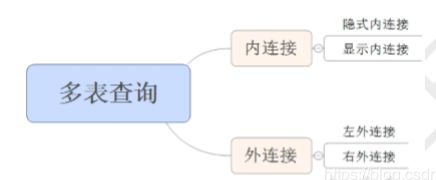
(9)多表查询
1. 创建部门表
create table dept(
id int primary key auto_increment, ---主键,自动增长
name varchar(20)
) ;
insert into dept (name) values ('开发部'),('市场部'),('财务部');
创建员工表
create table emp (
id int primary key auto_increment, ---主键,自动增长
name varchar(10),
gender char(1), -- 性别
salary double, -- 工资
join_date date, -- 入职日期
dept_id int,
foreign key (dept_id) references dept(id) --- 员工表外键,关联部门表(部门表的主键)
) ;
insert into emp(name,gender,salary,join_date,dept_id) values('孙悟空','男 ',7200,'2013-02-24',1);
insert into emp(name,gender,salary,join_date,dept_id) values('猪八戒','男 ',3600,'2010-12-02',2);
insert into emp(name,gender,salary,join_date,dept_id) values('唐僧','男',9000,'200808-08',2);
insert into emp(name,gender,salary,join_date,dept_id) values('小龙女','女 ',5000,'2015-10-07',3);
insert into emp(name,gender,salary,join_date,dept_id) values('观音','女 ',4500,'2011-03-14',1);
2.出现笛卡尔积(笛卡尔积百度百科)
select * from emp,dept; ---查询员工和部门的所有数据
-- 设置过滤条件 Column 'id' in where clause is ambiguous
select * from emp,dept where id=5;
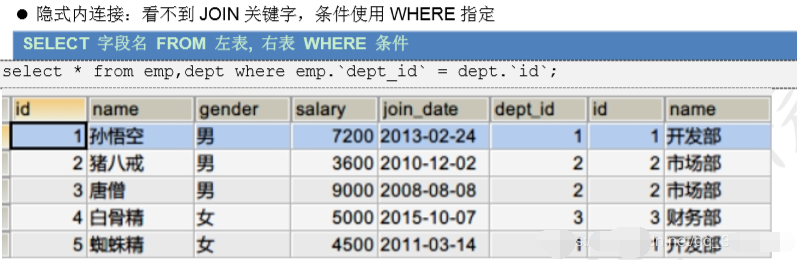
select * from emp,dept where emp.`dept_id` = dept.`id`;
-- 查询员工和部门的名字
select emp.`name`, dept.`name` from emp,dept where emp.`dept_id` = dept.`id`;
(10)内连接
1.隐式内连接
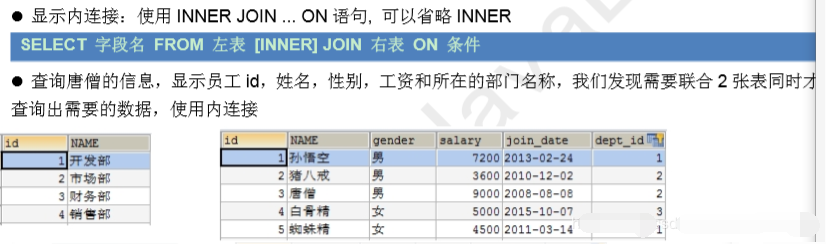
2.显式内连接
#确定表连接条件,员工表.dept_id = 部门表.id 的数据才是有效的
select * from emp e inner join dept d on e.`dept_id` = d.`id`;
#确定查询条件,我们查询的是唐僧的信息,员工表.name='唐僧' ;
select * from emp e inner join dept d on e.`dept_id` = d.`id` where e.`name`='唐僧 ';
#确定查询字段,查询唐僧的信息,显示员工 id,姓名,性别,工资和所在的部门名称
select e.`id`,e.`name`,e.`gender`,e.`salary`,d.`name` from emp e inner join dept d on e.`dept_id` = d.`id` where e.`name`='唐僧';
#写表名有点长,可以给表取别名,显示的字段名也使用别名
select e.`id` 编号,e.`name` 姓名,e.`gender` 性别,e.`salary` 工资,d.`name` 部门名字 from emp e inner join dept d on e.`dept_id` = d.`id` where e.`name`='唐僧';
(11)左外连接
语法:LEFT OUTER JOIN ... ON , OUTER 可以省略
SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件 ==
-- 在部门表中增加一个销售部
insert into dept (name) values ('销售部'); select * from dept;
-- 使用内连接查询
select * from dept d inner join emp e on d.`id` = e.`dept_id`;
-- 使用左外连接查询
select * from dept d left join emp e on d.`id` = e.`dept_id`;
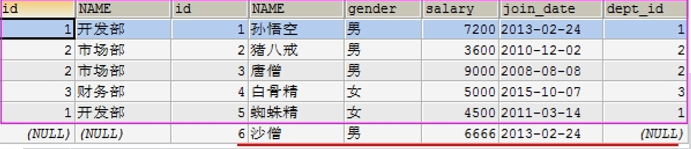
(12)右外连接
##用右边表的记录去匹配左边表的记录,如果符合条件的则显示;否则,显示 NULL 可以理解为:在内连接的基础上保证右表的数据全部显示
语法:RIGHT OUTER JOIN ... ON , OUTER 可以省略
SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件 ==
-- 在员工表中增加一个员工
insert into emp values (null, '沙僧','男',6666,'2013-12-05',null);
select * from emp;
-- 使用内连接查询
select * from dept inner join emp on dept.`id` = emp.`dept_id`;
-- 使用右外连接查询
select * from dept right join emp on dept.`id` = emp.`dept_id`;
(13)子查询
-- 需求:查询开发部中有哪些员工
select * from emp;
-- 通过两条语句查询
select id from dept where name='开发部' ;
select * from emp where dept_id = 1;-- 使用子查询
select * from emp where dept_id = (select id from dept where name='市场部')1.子查询的结果是一个值的时候
注意:子查询结果只要是单行单列,肯定在 WHERE 后面作为条件,父查询使用:比较运算符,如:> 、<、<>、 = 等
SELECT 查询字段 FROM 表 WHERE 字段=(子查询);--案例:查询工资最高的员工是谁?
-- 1) 查询最高工资是多少
select max(salary) from emp;
-- 2) 根据最高工资到员工表查询到对应的员工信息
select * from emp where salary = (select max(salary) from emp);
查询工资小于平均工资的员工有哪些?
-- 1) 查询平均工资是多少
select avg(salary) from emp;
-- 2) 到员工表查询小于平均的员工信息
select * from emp where salary < (select avg(salary) from emp);2.子查询结果是多行单列的时候
注意:子查询结果是单例多行,结果集类似于一个数组,父查询使用 IN 运算符
SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);--查询工资大于5000的员工,来自于哪些部门的名字
-- 先查询大于5000的员工所在的部门id
select dept_id from emp where salary > 5000;
-- 再查询在这些部门id中部门的名字 Subquery returns more than 1 row
select name from dept where id = (select dept_id from emp where salary > 5000);select name from dept where id in (select dept_id from emp where salary > 5000);
--查询开发部与财务部所有的员工信息
-- 先查询开发部与财务部的id
select id from dept where name in('开发部','财务部');
-- 再查询在这些部门id中有哪些员工
select * from emp where dept_id in (select id from dept where name in('开发部','财务 部'));3.子查询的结果是多行多列
注意:子查询结果只要是多列,肯定在 FROM 后面作为表;子查询作为表需要取别名,否则这张表没有名称则无法访问表中的字段
SELECT 查询字段 FROM (子查询) 表别名 WHERE 条件;--查询出2011年以后入职的员工信息,包括部门名称
-- 查询出2011年以后入职的员工信息,包括部门名称
-- 在员工表中查询2011-1-1以后入职的员工
select * from emp where join_date >='2011-1-1';
-- 查询所有的部门信息,与上面的虚拟表中的信息组合,找出所有部门id等于的dept_id
select * from dept d, (select * from emp where join_date >='2011-1-1') e where d.`id`= e.dept_id ;--也可以使用表连接:
select * from emp inner join dept on emp.`dept_id` = dept.`id` where join_date >='2011-1-1';
select * from emp inner join dept on emp.`dept_id` = dept.`id` and join_date >='2011-1-1';子查询总结:
- 子查询结果只要是单列,则在 WHERE 后面作为条件
- 子查询结果只要是多列,则在 FROM 后面作为表进行二次查询










(4)DCL :数据库控制语言
我们现在默认使用的都是 root 用户,超级管理员,拥有全部的权限。但是,一个公司里面的数据库服务器上面 可能同时运行着很多个项目的数据库。所以,我们应该可以根据不同的项目建立不同的用户,分配不同的权限来管理 和 维护数据库。
1.创建用户
语法:CREATE USER '用户名' @ '主机名' IDENTIFIED BY '密码';
create user 'root2' @ 'localhost' identified by '123456'; ---创建'root2' 用户,只能在 'localhost'这个服务器登录mysql服务器,密码为123456
2.给用户授权
用户创建后,是没有权限的,现在给它授权。
语法:GRANT 权限 1,权限2,权限3,... ON 数据库名 . 表名 TO ‘用户名’ @ ‘主机名’;
grant create ,alter,insert,update,select on test . * to 'root2' @ 'localhost' ; ---给 ‘root2’ 用户分配对 test 这个数据库操作的权限:创建表、修改表、插入数据、更新数据,查询
grant all on . to ' root3' @ ' % ' ; ---给 ‘root3’ 用户分配所有权限,对所有数据库的表
3.撤销授权
revoke all on test . * from 'root1' @ 'localhost' ; ---撤销 root1 用户对数据库 test 所有表的操作操作
4. 查看权限
SHOW GRANTS FOR '用户名 ' @ '主机名' ;
5.删除用户
语法:DROP USER ' 用户名 ' @ ' 主机名 ' ;
drop user ' root3 ' @ ' % ' ; ---删除root3
6.修改管理员密码
mysqlladmin -u root -p password 新密码;
7.修改普通用户密码
set password for ' 用户名 ' @ ' 主机名 ' = password(' 新密码 ');



总结:看到这里,我相信,通过本文的对mysql的介绍和一些mysql的操作,你已经能够对mysql有一个清晰的认识,sql语言的世界很广大,需要你这种有梦想的人去探索。我最初写博客,也只是想对自己的理解做一个记录,如果本文有不合格的地方,可以指正,三人行,必有我师!
qq:2931445528
-----------------------------------------------------------END----------------------------------------------------------------
本文有借鉴: https://blog.csdn.net/qq_38923630/article/details/90601991